 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPA: Inference Pipeline Adaptation to Achieve High Accuracy and Cost-Efficiency
Aug 24, 2023Efficiently optimizing multi-model inference pipelines for fast, accurate, and cost-effective inference is a crucial challenge in ML production systems, given their tight end-to-end latency requirements. To simplify the exploration of the vast and intricate trade-off space of accuracy and cost in inference pipelines, providers frequently opt to consider one of them. However, the challenge lies in reconciling accuracy and cost trade-offs. To address this challenge and propose a solution to efficiently manage model variants in inference pipelines, we present IPA, an online deep-learning Inference Pipeline Adaptation system that efficiently leverages model variants for each deep learning task. Model variants are different versions of pre-trained models for the same deep learning task with variations in resource requirements, latency, and accuracy. IPA dynamically configures batch size, replication, and model variants to optimize accuracy, minimize costs, and meet user-defined latency SLAs using Integer Programming. It supports multi-objective settings for achieving different trade-offs between accuracy and cost objectives while remaining adaptable to varying workloads and dynamic traffic patterns. Extensive experiments on a Kubernetes implementation with five real-world inference pipelines demonstrate that IPA improves normalized accuracy by up to 35% with a minimal cost increase of less than 5%.
Reconciling High Accuracy, Cost-Efficiency, and Low Latency of Inference Serving Systems
Apr 24, 2023The use of machine learning (ML) inference for various applications is growing drastically. ML inference services engage with users directly, requiring fast and accurate responses. Moreover, these services face dynamic workloads of requests, imposing changes in their computing resources. Failing to right-size computing resources results in either latency service level objectives (SLOs) violations or wasted computing resources. Adapting to dynamic workloads considering all the pillars of accuracy, latency, and resource cost is challenging. In response to these challenges, we propose InfAdapter, which proactively selects a set of ML model variants with their resource allocations to meet latency SLO while maximizing an objective function composed of accuracy and cost. InfAdapter decreases SLO violation and costs up to 65% and 33%, respectively, compared to a popular industry autoscaler (Kubernetes Vertical Pod Autoscaler).
SCAN: Structure Correcting Adversarial Network for Organ Segmentation in Chest X-rays
Apr 10, 2017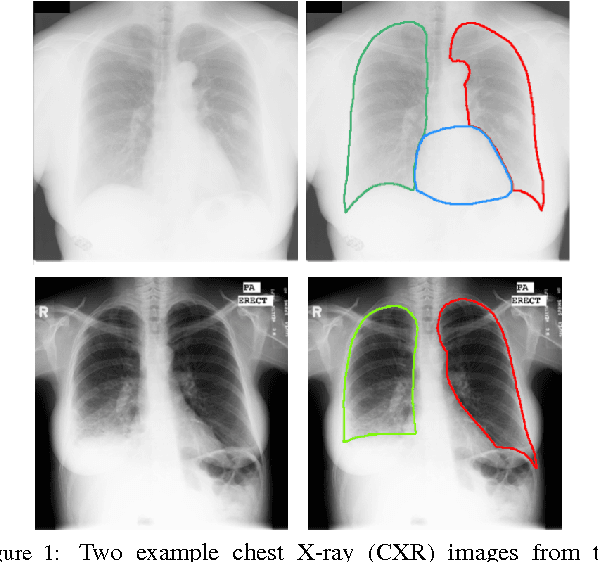



Chest X-ray (CXR) is one of the most commonly prescribed medical imaging procedures, often with over 2-10x more scans than other imaging modalities such as MRI, CT scan, and PET scans. These voluminous CXR scans place significant workloads on radiologists and medical practitioners. Organ segmentation is a crucial step to obtain effective computer-aided detection on CXR. In this work, we propose Structure Correcting Adversarial Network (SCAN) to segment lung fields and the heart in CXR images. SCAN incorporates a critic network to impose on the convolutional segmentation network the structural regularities emerging from human physiology. During training, the critic network learns to discriminate between the ground truth organ annotations from the masks synthesized by the segmentation network. Through this adversarial process the critic network learns the higher order structures and guides the segmentation model to achieve realistic segmentation outcomes. Extensive experiments show that our method produces highly accurate and natural segmentation. Using only very limited training data available, our model reaches human-level performance without relying on any existing trained model or dataset. Our method also generalizes well to CXR images from a different patient population and disease profiles, surpassing the current state-of-the-art.