 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Generation and Imputation of Driving Scenarios from Limited Vehicle CAN Data
Sep 15, 2025Training deep learning methods on small time series datasets that also include corrupted samples is challenging. Diffusion models have shown to be effective to generate realistic and synthetic data, and correct corrupted samples through imputation. In this context, this paper focuses on generating synthetic yet realistic samples of automotive time series data. We show that denoising diffusion probabilistic models (DDPMs) can effectively solve this task by applying them to a challenging vehicle CAN-dataset with long-term data and a limited number of samples. Therefore, we propose a hybrid generative approach that combines autoregressive and non-autoregressive techniques. We evaluate our approach with two recently proposed DDPM architectures for time series generation, for which we propose several improvements. To evaluate the generated samples, we propose three metrics that quantify physical correctness and test track adherence. Our best model is able to outperform even the training data in terms of physical correctness, while showing plausible driving behavior. Finally, we use our best model to successfully impute physically implausible regions in the training data, thereby improving the data quality.
SafePath: Conformal Prediction for Safe LLM-Based Autonomous Navigation
May 15, 2025


Large Language Models (LLMs) show growing promise in autonomous driving by reasoning over complex traffic scenarios to generate path plans. However, their tendencies toward overconfidence, and hallucinations raise critical safety concerns. We introduce SafePath, a modular framework that augments LLM-based path planning with formal safety guarantees using conformal prediction. SafePath operates in three stages. In the first stage, we use an LLM that generates a set of diverse candidate paths, exploring possible trajectories based on agent behaviors and environmental cues. In the second stage, SafePath filters out high-risk trajectories while guaranteeing that at least one safe option is included with a user-defined probability, through a multiple-choice question-answering formulation that integrates conformal prediction. In the final stage, our approach selects the path with the lowest expected collision risk when uncertainty is low or delegates control to a human when uncertainty is high. We theoretically prove that SafePath guarantees a safe trajectory with a user-defined probability, and we show how its human delegation rate can be tuned to balance autonomy and safety. Extensive experiments on nuScenes and Highway-env show that SafePath reduces planning uncertainty by 77\% and collision rates by up to 70\%, demonstrating effectiveness in making LLM-driven path planning more safer.
Whenever, Wherever: Towards Orchestrating Crowd Simulations with Spatio-Temporal Spawn Dynamics
Mar 20, 2025



Realistic crowd simulations are essential for immersive virtual environments, relying on both individual behaviors (microscopic dynamics) and overall crowd patterns (macroscopic characteristics). While recent data-driven methods like deep reinforcement learning improve microscopic realism, they often overlook critical macroscopic features such as crowd density and flow, which are governed by spatio-temporal spawn dynamics, namely, when and where agents enter a scene. Traditional methods, like random spawn rates, stochastic processes, or fixed schedules, are not guaranteed to capture the underlying complexity or lack diversity and realism. To address this issue, we propose a novel approach called nTPP-GMM that models spatio-temporal spawn dynamics using Neural Temporal Point Processes (nTPPs) that are coupled with a spawn-conditional Gaussian Mixture Model (GMM) for agent spawn and goal positions. We evaluate our approach by orchestrating crowd simulations of three diverse real-world datasets with nTPP-GMM. Our experiments demonstrate the orchestration with nTPP-GMM leads to realistic simulations that reflect real-world crowd scenarios and allow crowd analysis.
LiOn-XA: Unsupervised Domain Adaptation via LiDAR-Only Cross-Modal Adversarial Training
Oct 21, 2024



In this paper, we propose LiOn-XA, an unsupervised domain adaptation (UDA) approach that combines LiDAR-Only Cross-Modal (X) learning with Adversarial training for 3D LiDAR point cloud semantic segmentation to bridge the domain gap arising from environmental and sensor setup changes. Unlike existing works that exploit multiple data modalities like point clouds and RGB image data, we address UDA in scenarios where RGB images might not be available and show that two distinct LiDAR data representations can learn from each other for UDA. More specifically, we leverage 3D voxelized point clouds to preserve important geometric structure in combination with 2D projection-based range images that provide information such as object orientations or surfaces. To further align the feature space between both domains, we apply adversarial training using both features and predictions of both 2D and 3D neural networks. Our experiments on 3 real-to-real adaptation scenarios demonstrate the effectiveness of our approach, achieving new state-of-the-art performance when compared to previous uni- and multi-model UDA methods. Our source code is publicly available at https://github.com/JensLe97/lion-xa.
Reconciling High Accuracy, Cost-Efficiency, and Low Latency of Inference Serving Systems
Apr 24, 2023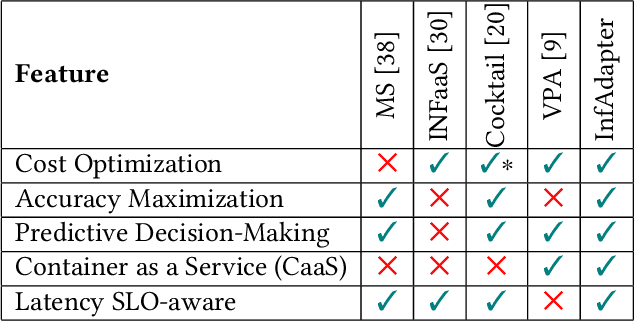
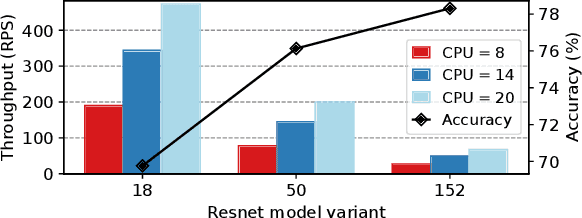
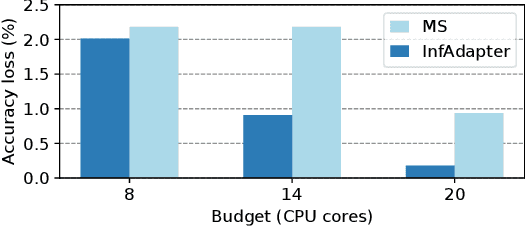

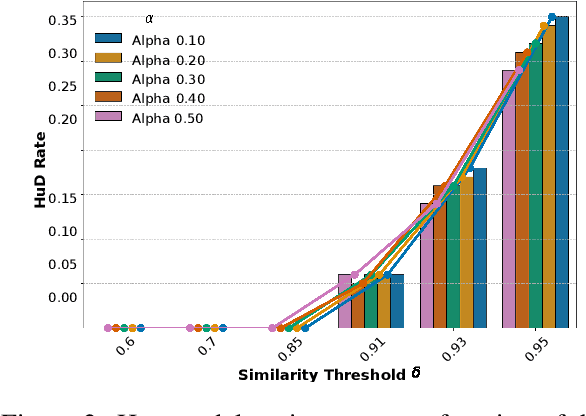
The use of machine learning (ML) inference for various applications is growing drastically. ML inference services engage with users directly, requiring fast and accurate responses. Moreover, these services face dynamic workloads of requests, imposing changes in their computing resources. Failing to right-size computing resources results in either latency service level objectives (SLOs) violations or wasted computing resources. Adapting to dynamic workloads considering all the pillars of accuracy, latency, and resource cost is challenging. In response to these challenges, we propose InfAdapter, which proactively selects a set of ML model variants with their resource allocations to meet latency SLO while maximizing an objective function composed of accuracy and cost. InfAdapter decreases SLO violation and costs up to 65% and 33%, respectively, compared to a popular industry autoscaler (Kubernetes Vertical Pod Autoscaler).
Unsupervised Driving Event Discovery Based on Vehicle CAN-data
Jan 12, 2023



The data collected from a vehicle's Controller Area Network (CAN) can quickly exceed human analysis or annotation capabilities when considering fleets of vehicles, which stresses the importance of unsupervised machine learning methods. This work presents a simultaneous clustering and segmentation approach for vehicle CAN-data that identifies common driving events in an unsupervised manner. The approach builds on self-supervised learning (SSL) for multivariate time series to distinguish different driving events in the learned latent space. We evaluate our approach with a dataset of real Tesla Model 3 vehicle CAN-data and a two-hour driving session that we annotated with different driving events. With our approach, we evaluate the applicability of recent time series-related contrastive and generative SSL techniques to learn representations that distinguish driving events. Compared to state-of-the-art (SOTA) generative SSL methods for driving event discovery, we find that contrastive learning approaches reach similar performance.
Unsupervised 4D LiDAR Moving Object Segmentation in Stationary Settings with Multivariate Occupancy Time Series
Dec 30, 2022



In this work, we address the problem of unsupervised moving object segmentation (MOS) in 4D LiDAR data recorded from a stationary sensor, where no ground truth annotations are involved. Deep learning-based state-of-the-art methods for LiDAR MOS strongly depend on annotated ground truth data, which is expensive to obtain and scarce in existence. To close this gap in the stationary setting, we propose a novel 4D LiDAR representation based on multivariate time series that relaxes the problem of unsupervised MOS to a time series clustering problem. More specifically, we propose modeling the change in occupancy of a voxel by a multivariate occupancy time series (MOTS), which captures spatio-temporal occupancy changes on the voxel level and its surrounding neighborhood. To perform unsupervised MOS, we train a neural network in a self-supervised manner to encode MOTS into voxel-level feature representations, which can be partitioned by a clustering algorithm into moving or stationary. Experiments on stationary scenes from the Raw KITTI dataset show that our fully unsupervised approach achieves performance that is comparable to that of supervised state-of-the-art approaches.
User Label Leakage from Gradients in Federated Learning
May 22, 2021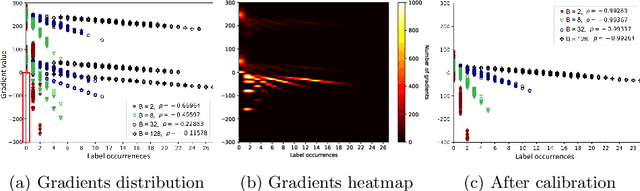

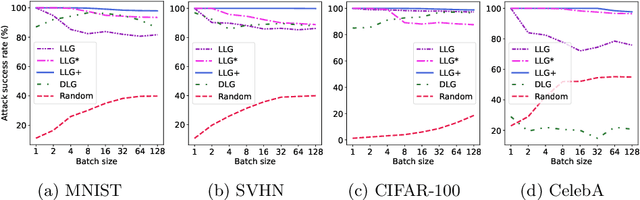

Federated learning enables multiple users to build a joint model by sharing their model updates (gradients), while their raw data remains local on their devices. In contrast to the common belief that this provides privacy benefits, we here add to the very recent results on privacy risks when sharing gradients. Specifically, we propose Label Leakage from Gradients (LLG), a novel attack to extract the labels of the users' training data from their shared gradients. The attack exploits the direction and magnitude of gradients to determine the presence or absence of any label. LLG is simple yet effective, capable of leaking potential sensitive information represented by labels, and scales well to arbitrary batch sizes and multiple classes. We empirically and mathematically demonstrate the validity of our attack under different settings. Moreover, empirical results show that LLG successfully extracts labels with high accuracy at the early stages of model training. We also discuss different defense mechanisms against such leakage. Our findings suggest that gradient compression is a practical technique to prevent our attack.
DeepAlign: Alignment-based Process Anomaly Correction using Recurrent Neural Networks
Nov 29, 2019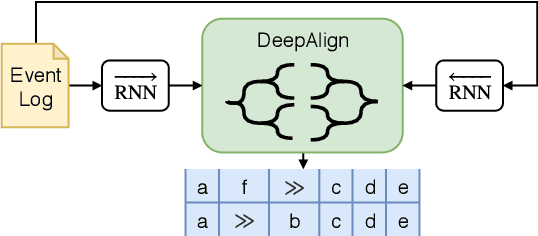
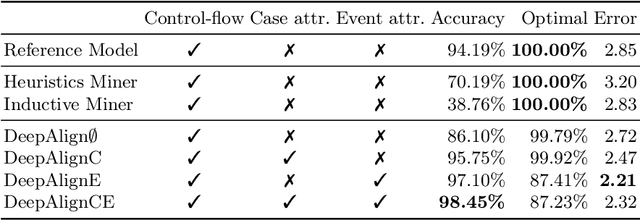
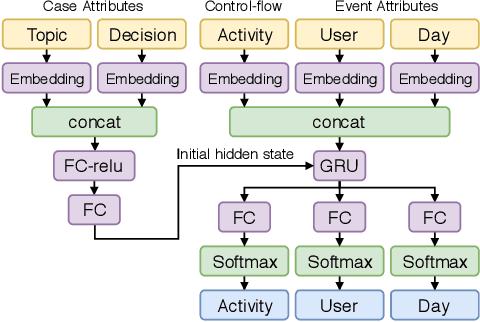

In this paper, we propose DeepAlign, a novel approach to multi-perspective process anomaly correction, based on recurrent neural networks and bidirectional beam search. At the core of the DeepAlign algorithm are two recurrent neural networks trained to predict the next event. One is reading sequences of process executions from left to right, while the other is reading the sequences from right to left. By combining the predictive capabilities of both neural networks, we show that it is possible to calculate sequence alignments, which are used to detect and correct anomalies. DeepAlign utilizes the case-level and event-level attributes to closely model the decisions within a process. We evaluate the performance of our approach on an elaborate data corpus of 30 realistic synthetic event logs and compare it to three state-of-the-art conformance checking methods. DeepAlign produces better corrections than the rest of the field reaching an overall accuracy of 98.45% across all datasets, whereas the best comparable state-of-the-art method reaches 70.19%.
BINet: Multi-perspective Business Process Anomaly Classification
Feb 08, 2019


In this paper, we introduce BINet, a neural network architecture for real-time multi-perspective anomaly detection in business process event logs. BINet is designed to handle both the control flow and the data perspective of a business process. Additionally, we propose a set of heuristics for setting the threshold of an anomaly detection algorithm automatically. We demonstrate that BINet can be used to detect anomalies in event logs not only on a case level but also on event attribute level. Finally, we demonstrate that a simple set of rules can be used to utilize the output of BINet for anomaly classification. We compare BINet to eight other state-of-the-art anomaly detection algorithms and evaluate their performance on an elaborate data corpus of 29 synthetic and 15 real-life event logs. BINet outperforms all other methods both on the synthetic as well as on the real-life datasets.