 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigSpec: Profiling-Based Configuration Selection for Distributed Edge--Cloud Speculative LLM Serving
Apr 08, 2026Speculative decoding enables collaborative Large Language Model (LLM) inference across cloud and edge by separating lightweight token drafting from heavyweight verification. While prior systems show performance and cost benefits, practical deployment requires navigating a large configuration space spanning draft model variants, quantisation levels, speculative lengths, and heterogeneous edge devices. This paper presents ConfigSpec, a configurationselection framework for distributed speculative LLM serving. ConfigSpec profiles edge devices and draft-target alignment, and models drafting throughput, acceptance rate, and power to evaluate goodput, verification cost efficiency, and energy efficiency across the joint configuration space. Our analysis across three edge platforms and two LLM families reveals structurally conflicting optima. Firstly, goodput is maximised by the smallest, fastest draft model at device-dependent speculative lengths (K*=2-10). Secondly, both cost and energy efficiency converge to K=2 due to a dominant bonus-token effect-with cost favouring the largest drafter for its high acceptance rate and energy favouring the smallest for its low power draw. These conflicts confirm that no single fixed configuration can simultaneously optimise all objectives, underscoring the need for profiling-based configuration selection in disaggregated edge-cloud LLM inference.
WISP: Waste- and Interference-Suppressed Distributed Speculative LLM Serving at the Edge via Dynamic Drafting and SLO-Aware Batching
Jan 15, 2026As Large Language Models (LLMs) become increasingly accessible to end users, an ever-growing number of inference requests are initiated from edge devices and computed on centralized GPU clusters. However, the resulting exponential growth in computation workload is placing significant strain on data centers, while edge devices remain largely underutilized, leading to imbalanced workloads and resource inefficiency across the network. Integrating edge devices into the LLM inference process via speculative decoding helps balance the workload between the edge and the cloud, while maintaining lossless prediction accuracy. In this paper, we identify and formalize two critical bottlenecks that limit the efficiency and scalability of distributed speculative LLM serving: Wasted Drafting Time and Verification Interference. To address these challenges, we propose WISP, an efficient and SLO-aware distributed LLM inference system that consists of an intelligent speculation controller, a verification time estimator, and a verification batch scheduler. These components collaboratively enhance drafting efficiency and optimize verification request scheduling on the server. Extensive numerical results show that WISP improves system capacity by up to 2.1x and 4.1x, and increases system goodput by up to 1.94x and 3.7x, compared to centralized serving and SLED, respectively.
SLED: A Speculative LLM Decoding Framework for Efficient Edge Serving
Jun 11, 2025Regardless the advancements in device capabilities, efficient inferencing advanced large language models (LLMs) at the edge remains challenging due to limited device memory and power constraints. Existing strategies, such as aggressive quantization, pruning, or remote inference, trade accuracy for efficiency or lead to substantial cost burdens. This position paper introduces a new approach that leverages speculative decoding, previously viewed primarily as a decoding acceleration technique for autoregressive generation of LLMs, as a promising approach specifically adapted for edge computing by orchestrating computation across heterogeneous devices. We propose SLED, a method that allows lightweight edge devices to draft multiple candidate tokens locally using diverse draft models, while a single, shared edge server efficiently batches and verifies the tokens utilizing a more precise target model. This approach supports device heterogeneity and reduces server-side memory footprint by avoiding the need to deploy multiple target models. Our initial experiments with Jetson Orin Nano, Raspberry Pi 5, and an RTX 6000 edge server indicate substantial benefits: significantly reduced latency, improved energy efficiency, and increased concurrent inference sessions, all without sacrificing model accuracy.
IPA: Inference Pipeline Adaptation to Achieve High Accuracy and Cost-Efficiency
Aug 24, 2023Efficiently optimizing multi-model inference pipelines for fast, accurate, and cost-effective inference is a crucial challenge in ML production systems, given their tight end-to-end latency requirements. To simplify the exploration of the vast and intricate trade-off space of accuracy and cost in inference pipelines, providers frequently opt to consider one of them. However, the challenge lies in reconciling accuracy and cost trade-offs. To address this challenge and propose a solution to efficiently manage model variants in inference pipelines, we present IPA, an online deep-learning Inference Pipeline Adaptation system that efficiently leverages model variants for each deep learning task. Model variants are different versions of pre-trained models for the same deep learning task with variations in resource requirements, latency, and accuracy. IPA dynamically configures batch size, replication, and model variants to optimize accuracy, minimize costs, and meet user-defined latency SLAs using Integer Programming. It supports multi-objective settings for achieving different trade-offs between accuracy and cost objectives while remaining adaptable to varying workloads and dynamic traffic patterns. Extensive experiments on a Kubernetes implementation with five real-world inference pipelines demonstrate that IPA improves normalized accuracy by up to 35% with a minimal cost increase of less than 5%.
Reconciling High Accuracy, Cost-Efficiency, and Low Latency of Inference Serving Systems
Apr 24, 2023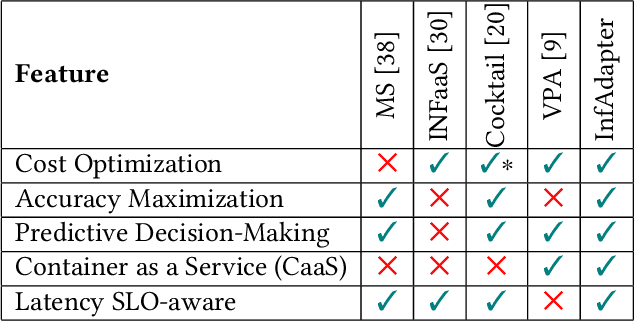
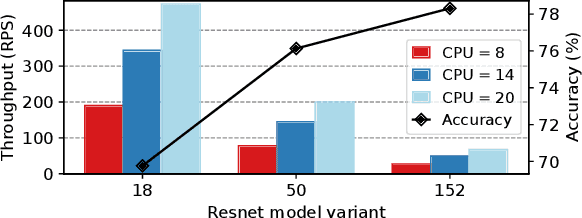
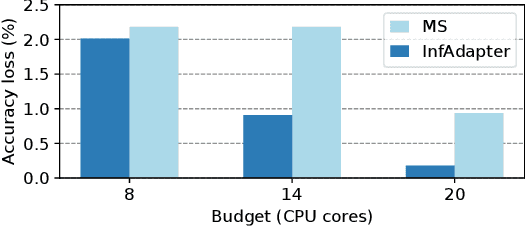

The use of machine learning (ML) inference for various applications is growing drastically. ML inference services engage with users directly, requiring fast and accurate responses. Moreover, these services face dynamic workloads of requests, imposing changes in their computing resources. Failing to right-size computing resources results in either latency service level objectives (SLOs) violations or wasted computing resources. Adapting to dynamic workloads considering all the pillars of accuracy, latency, and resource cost is challenging. In response to these challenges, we propose InfAdapter, which proactively selects a set of ML model variants with their resource allocations to meet latency SLO while maximizing an objective function composed of accuracy and cost. InfAdapter decreases SLO violation and costs up to 65% and 33%, respectively, compared to a popular industry autoscaler (Kubernetes Vertical Pod Autoscaler).
Opinion Leader Detection in Online Social Networks Based on Output and Input Links
Aug 28, 2022
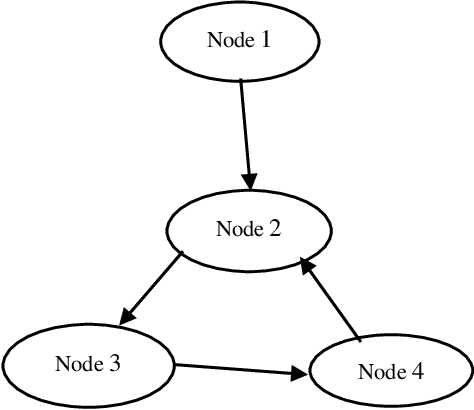


The understanding of how users in a network update their opinions based on their neighbours opinions has attracted a great deal of interest in the field of network science, and a growing body of literature recognises the significance of this issue. In this research paper, we propose a new dynamic model of opinion formation in directed networks. In this model, the opinion of each node is updated as the weighted average of its neighbours opinions, where the weights represent social influence. We define a new centrality measure as a social influence metric based on both influence and conformity. We measure this new approach using two opinion formation models: (i) the Degroot model and (ii) our own proposed model. Previously published research studies have not considered conformity, and have only considered the influence of the nodes when computing the social influence. In our definition, nodes with low in-degree and high out-degree that were connected to nodes with high out-degree and low in-degree had higher centrality. As the main contribution of this research, we propose an algorithm for finding a small subset of nodes in a social network that can have a significant impact on the opinions of other nodes. Experiments on real-world data demonstrate that the proposed algorithm significantly outperforms previously published state-of-the-art methods.