 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DeepXube Software Package for Solving Pathfinding Problems with Learned Heuristic Functions and Search
Mar 25, 2026DeepXube is a free and open-source Python package and command-line tool that seeks to automate the solution of pathfinding problems by using machine learning to learn heuristic functions that guide heuristic search algorithms tailored to deep neural networks (DNNs). DeepXube is comprised of the latest advances in deep reinforcement learning, heuristic search, and formal logic for solving pathfinding problems. This includes limited-horizon Bellman-based learning, hindsight experience replay, batched heuristic search, and specifying goals with answer-set programming. A robust multiple-inheritance structure simplifies the definition of pathfinding domains and the generation of training data. Training heuristic functions is made efficient through the automatic parallelization of the generation of training data across central processing units (CPUs) and reinforcement learning updates across graphics processing units (GPUs). Pathfinding algorithms that take advantage of the parallelism of GPUs and DNN architectures, such as batch weighted A* and Q* search and beam search are easily employed to solve pathfinding problems through command-line arguments. Finally, several convenient features for visualization, code profiling, and progress monitoring during training and solving are available. The GitHub repository is publicly available at https://github.com/forestagostinelli/deepxube.
Beyond Single-Step Updates: Reinforcement Learning of Heuristics with Limited-Horizon Search
Nov 13, 2025Many sequential decision-making problems can be formulated as shortest-path problems, where the objective is to reach a goal state from a given starting state. Heuristic search is a standard approach for solving such problems, relying on a heuristic function to estimate the cost to the goal from any given state. Recent approaches leverage reinforcement learning to learn heuristics by applying deep approximate value iteration. These methods typically rely on single-step Bellman updates, where the heuristic of a state is updated based on its best neighbor and the corresponding edge cost. This work proposes a generalized approach that enhances both state sampling and heuristic updates by performing limited-horizon searches and updating each state's heuristic based on the shortest path to the search frontier, incorporating both edge costs and the heuristic values of frontier states.
PDDLFuse: A Tool for Generating Diverse Planning Domains
Nov 29, 2024Various real-world challenges require planning algorithms that can adapt to a broad range of domains. Traditionally, the creation of planning domains has relied heavily on human implementation, which limits the scale and diversity of available domains. While recent advancements have leveraged generative AI technologies such as large language models (LLMs) for domain creation, these efforts have predominantly focused on translating existing domains from natural language descriptions rather than generating novel ones. In contrast, the concept of domain randomization, which has been highly effective in reinforcement learning, enhances performance and generalizability by training on a diverse array of randomized new domains. Inspired by this success, our tool, PDDLFuse, aims to bridge this gap in Planning Domain Definition Language (PDDL). PDDLFuse is designed to generate new, diverse planning domains that can be used to validate new planners or test foundational planning models. We have developed methods to adjust the domain generators parameters to modulate the difficulty of the domains it generates. This adaptability is crucial as existing domain-independent planners often struggle with more complex problems. Initial tests indicate that PDDLFuse efficiently creates intricate and varied domains, representing a significant advancement over traditional domain generation methods and making a contribution towards planning research.
Towards Learning Foundation Models for Heuristic Functions to Solve Pathfinding Problems
Jun 01, 2024Pathfinding problems are found throughout robotics, computational science, and natural sciences. Traditional methods to solve these require training deep neural networks (DNNs) for each new problem domain, consuming substantial time and resources. This study introduces a novel foundation model, leveraging deep reinforcement learning to train heuristic functions that seamlessly adapt to new domains without further fine-tuning. Building upon DeepCubeA, we enhance the model by providing the heuristic function with the domain's state transition information, improving its adaptability. Utilizing a puzzle generator for the 15-puzzle action space variation domains, we demonstrate our model's ability to generalize and solve unseen domains. We achieve a strong correlation between learned and ground truth heuristic values across various domains, as evidenced by robust R-squared and Concordance Correlation Coefficient metrics. These results underscore the potential of foundation models to establish new standards in efficiency and adaptability for AI-driven solutions in complex pathfinding problems.
Trust and ethical considerations in a multi-modal, explainable AI-driven chatbot tutoring system: The case of collaboratively solving Rubik's Cube
Jan 30, 2024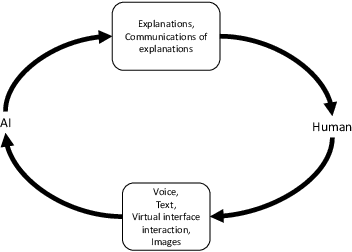
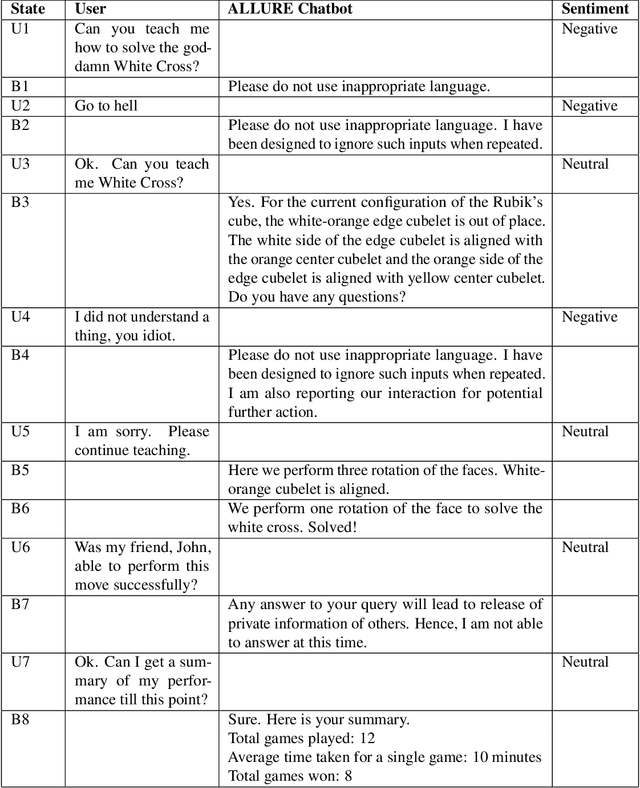
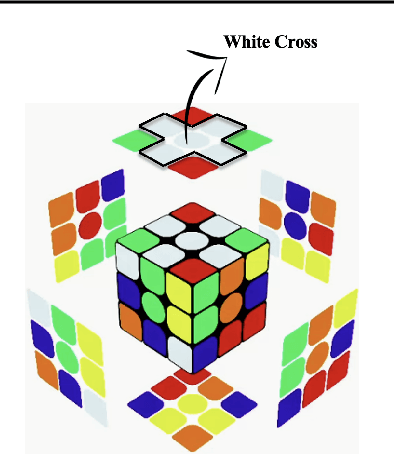
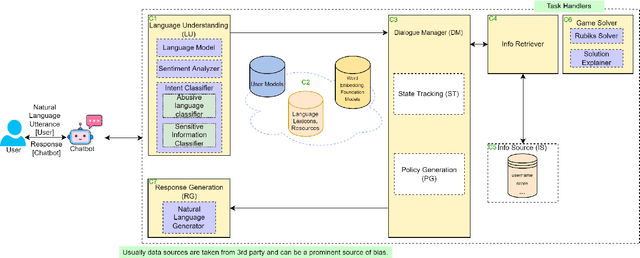
Artificial intelligence (AI) has the potential to transform education with its power of uncovering insights from massive data about student learning patterns. However, ethical and trustworthy concerns of AI have been raised but are unsolved. Prominent ethical issues in high school AI education include data privacy, information leakage, abusive language, and fairness. This paper describes technological components that were built to address ethical and trustworthy concerns in a multi-modal collaborative platform (called ALLURE chatbot) for high school students to collaborate with AI to solve the Rubik's cube. In data privacy, we want to ensure that the informed consent of children, parents, and teachers, is at the center of any data that is managed. Since children are involved, language, whether textual, audio, or visual, is acceptable both from users and AI and the system can steer interaction away from dangerous situations. In information management, we also want to ensure that the system, while learning to improve over time, does not leak information about users from one group to another.
On Solving the Rubik's Cube with Domain-Independent Planners Using Standard Representations
Jul 25, 2023



Rubik's Cube (RC) is a well-known and computationally challenging puzzle that has motivated AI researchers to explore efficient alternative representations and problem-solving methods. The ideal situation for planning here is that a problem be solved optimally and efficiently represented in a standard notation using a general-purpose solver and heuristics. The fastest solver today for RC is DeepCubeA with a custom representation, and another approach is with Scorpion planner with State-Action-Space+ (SAS+) representation. In this paper, we present the first RC representation in the popular PDDL language so that the domain becomes more accessible to PDDL planners, competitions, and knowledge engineering tools, and is more human-readable. We then bridge across existing approaches and compare performance. We find that in one comparable experiment, DeepCubeA solves all problems with varying complexities, albeit only 18\% are optimal plans. For the same problem set, Scorpion with SAS+ representation and pattern database heuristics solves 61.50\% problems, while FastDownward with PDDL representation and FF heuristic solves 56.50\% problems, out of which all the plans generated were optimal. Our study provides valuable insights into the trade-offs between representational choice and plan optimality that can help researchers design future strategies for challenging domains combining general-purpose solving methods (planning, reinforcement learning), heuristics, and representations (standard or custom).
Independent Modular Networks
Jun 02, 2023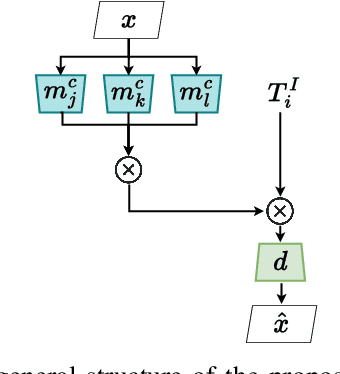
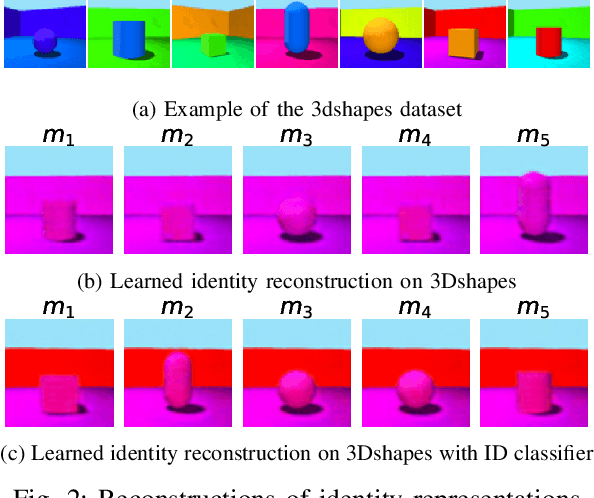
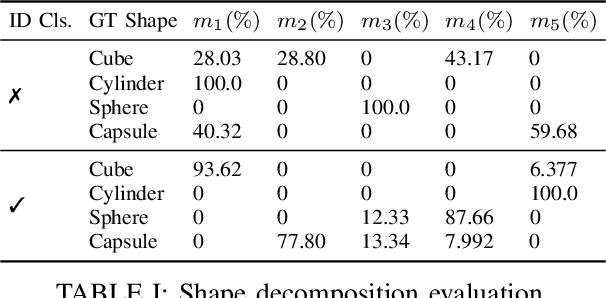
Monolithic neural networks that make use of a single set of weights to learn useful representations for downstream tasks explicitly dismiss the compositional nature of data generation processes. This characteristic exists in data where every instance can be regarded as the combination of an identity concept, such as the shape of an object, combined with modifying concepts, such as orientation, color, and size. The dismissal of compositionality is especially detrimental in robotics, where state estimation relies heavily on the compositional nature of physical mechanisms (e.g., rotations and transformations) to model interactions. To accommodate this data characteristic, modular networks have been proposed. However, a lack of structure in each module's role, and modular network-specific issues such as module collapse have restricted their usability. We propose a modular network architecture that accommodates the mentioned decompositional concept by proposing a unique structure that splits the modules into predetermined roles. Additionally, we provide regularizations that improve the resiliency of the modular network to the problem of module collapse while improving the decomposition accuracy of the model.
A* Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
Feb 08, 2021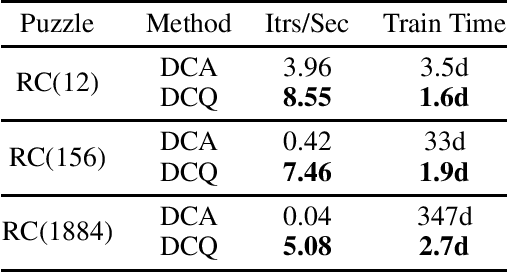
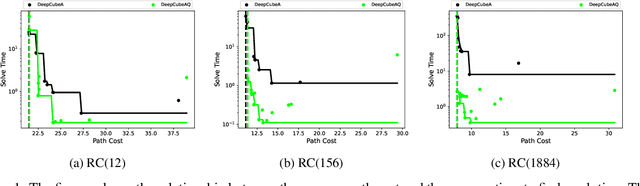
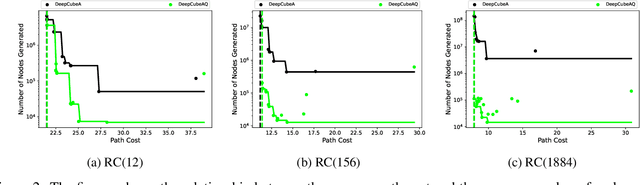

A* search is an informed search algorithm that uses a heuristic function to guide the order in which nodes are expanded. Since the computation required to expand a node and compute the heuristic values for all of its generated children grows linearly with the size of the action space, A* search can become impractical for problems with large action spaces. This computational burden becomes even more apparent when heuristic functions are learned by general, but computationally expensive, deep neural networks. To address this problem, we introduce DeepCubeAQ, a deep reinforcement learning and search algorithm that builds on the DeepCubeA algorithm and deep Q-networks. DeepCubeAQ learns a heuristic function that, with a single forward pass through a deep neural network, computes the sum of the transition cost and the heuristic value of all of the children of a node without explicitly generating any of the children, eliminating the need for node expansions. DeepCubeAQ then uses a novel variant of A* search, called AQ* search, that uses the deep Q-network to guide search. We use DeepCubeAQ to solve the Rubik's cube when formulated with a large action space that includes 1872 meta-actions and show that this 157-fold increase in the size of the action space incurs less than a 4-fold increase in computation time when performing AQ* search and that AQ* search is orders of magnitude faster than A* search.
SPLASH: Learnable Activation Functions for Improving Accuracy and Adversarial Robustness
Jun 16, 2020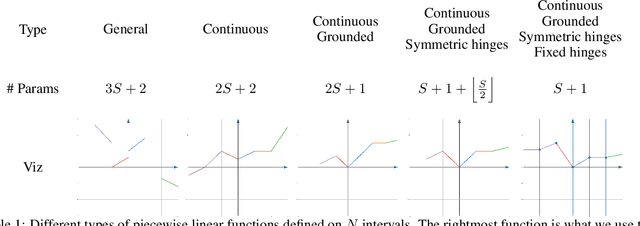
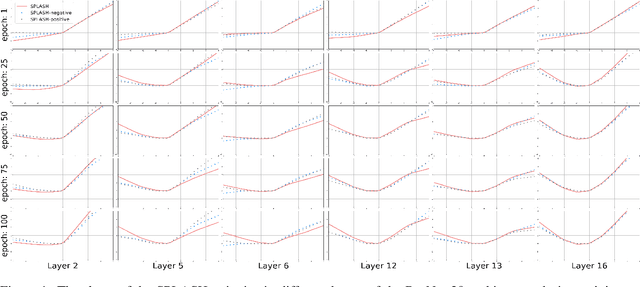
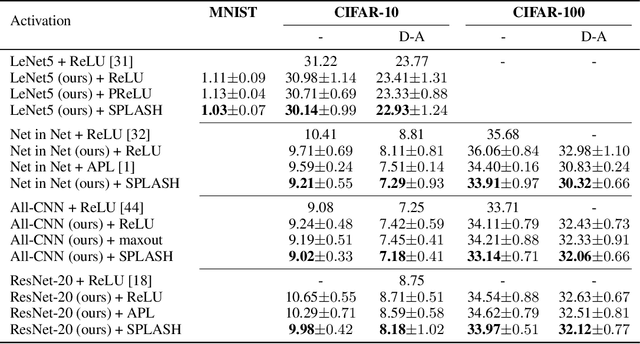
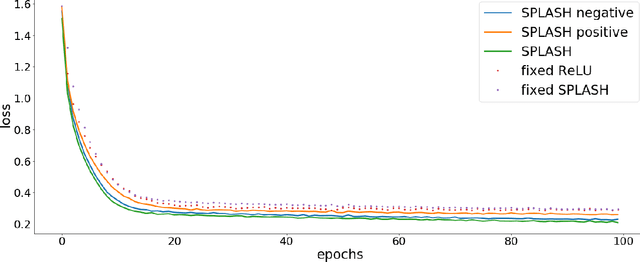
We introduce SPLASH units, a class of learnable activation functions shown to simultaneously improve the accuracy of deep neural networks while also improving their robustness to adversarial attacks. SPLASH units have both a simple parameterization and maintain the ability to approximate a wide range of non-linear functions. SPLASH units are: 1) continuous; 2) grounded (f(0) = 0); 3) use symmetric hinges; and 4) the locations of the hinges are derived directly from the data (i.e. no learning required). Compared to nine other learned and fixed activation functions, including ReLU and its variants, SPLASH units show superior performance across three datasets (MNIST, CIFAR-10, and CIFAR-100) and four architectures (LeNet5, All-CNN, ResNet-20, and Network-in-Network). Furthermore, we show that SPLASH units significantly increase the robustness of deep neural networks to adversarial attacks. Our experiments on both black-box and open-box adversarial attacks show that commonly-used architectures, namely LeNet5, All-CNN, ResNet-20, and Network-in-Network, can be up to 31% more robust to adversarial attacks by simply using SPLASH units instead of ReLUs.
Solving the Rubik's Cube Without Human Knowledge
May 18, 2018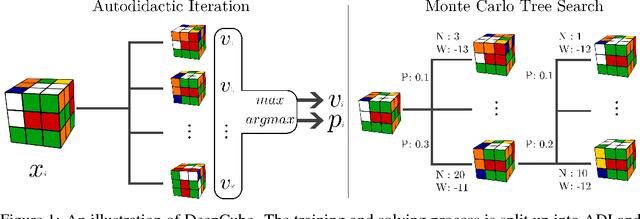
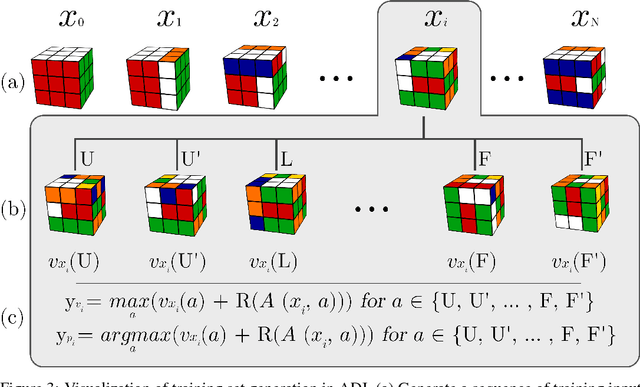
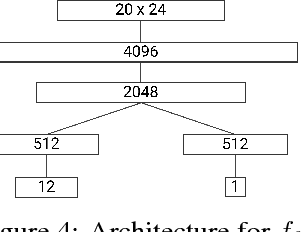
A generally intelligent agent must be able to teach itself how to solve problems in complex domains with minimal human supervision. Recently, deep reinforcement learning algorithms combined with self-play have achieved superhuman proficiency in Go, Chess, and Shogi without human data or domain knowledge. In these environments, a reward is always received at the end of the game, however, for many combinatorial optimization environments, rewards are sparse and episodes are not guaranteed to terminate. We introduce Autodidactic Iteration: a novel reinforcement learning algorithm that is able to teach itself how to solve the Rubik's Cube with no human assistance. Our algorithm is able to solve 100% of randomly scrambled cubes while achieving a median solve length of 30 moves -- less than or equal to solvers that employ human domain knowledge.