 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
SWaRL: Safeguard Code Watermarking via Reinforcement Learning
Jan 05, 2026We present SWaRL, a robust and fidelity-preserving watermarking framework designed to protect the intellectual property of code LLM owners by embedding unique and verifiable signatures in the generated output. Existing approaches rely on manually crafted transformation rules to preserve watermarked code functionality or manipulate token-generation probabilities at inference time, which are prone to compilation errors. To address these challenges, SWaRL employs a reinforcement learning-based co-training framework that uses compiler feedback for functional correctness and a jointly trained confidential verifier as a reward signal to maintain watermark detectability. Furthermore, SWaRL employs low-rank adaptation (LoRA) during fine-tuning, allowing the learned watermark information to be transferable across model updates. Extensive experiments show that SWaRL achieves higher watermark detection accuracy compared to prior methods while fully maintaining watermarked code functionality. The LoRA-based signature embedding steers the base model to generate and solve code in a watermark-specific manner without significant computational overhead. Moreover, SWaRL exhibits strong resilience against refactoring and adversarial transformation attacks.
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025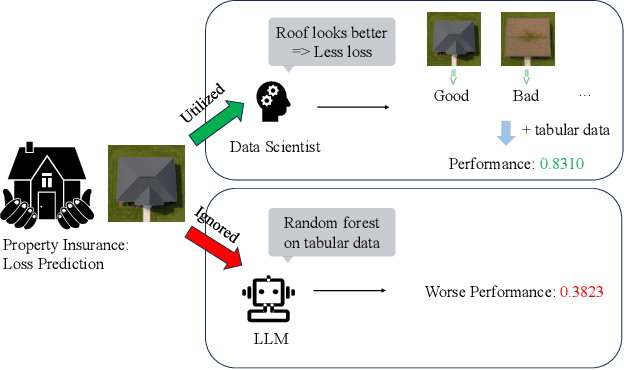

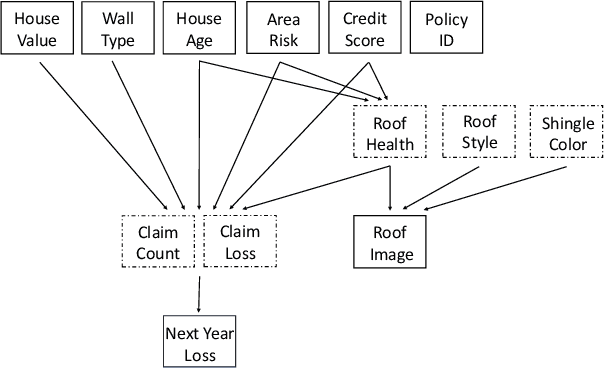

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
NetBurst: Event-Centric Forecasting of Bursty, Intermittent Time Series
Oct 25, 2025Forecasting on widely used benchmark time series data (e.g., ETT, Electricity, Taxi, and Exchange Rate, etc.) has favored smooth, seasonal series, but network telemetry time series -- traffic measurements at service, IP, or subnet granularity -- are instead highly bursty and intermittent, with heavy-tailed bursts and highly variable inactive periods. These properties place the latter in the statistical regimes made famous and popularized more than 20 years ago by B.~Mandelbrot. Yet forecasting such time series with modern-day AI architectures remains underexplored. We introduce NetBurst, an event-centric framework that reformulates forecasting as predicting when bursts occur and how large they are, using quantile-based codebooks and dual autoregressors. Across large-scale sets of production network telemetry time series and compared to strong baselines, such as Chronos, NetBurst reduces Mean Average Scaled Error (MASE) by 13--605x on service-level time series while preserving burstiness and producing embeddings that cluster 5x more cleanly than Chronos. In effect, our work highlights the benefits that modern AI can reap from leveraging Mandelbrot's pioneering studies for forecasting in bursty, intermittent, and heavy-tailed regimes, where its operational value for high-stakes decision making is of paramount interest.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
Apollo: A Posteriori Label-Only Membership Inference Attack Towards Machine Unlearning
Jun 11, 2025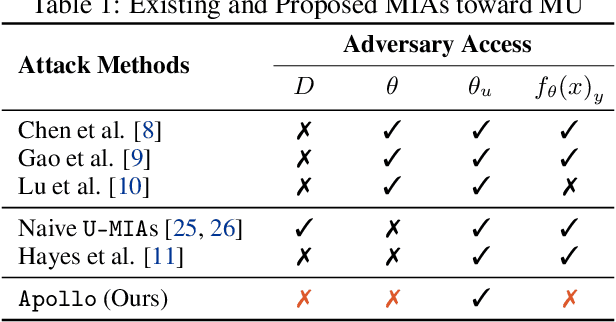
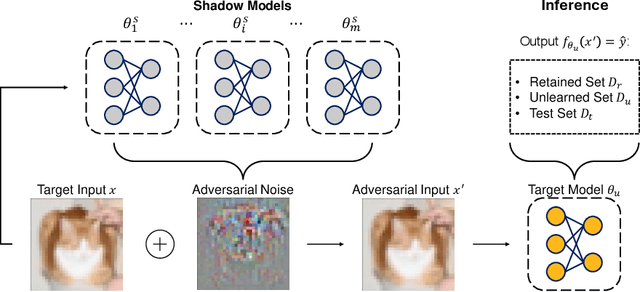
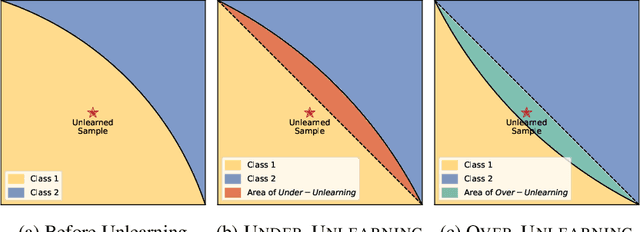

Machine Unlearning (MU) aims to update Machine Learning (ML) models following requests to remove training samples and their influences on a trained model efficiently without retraining the original ML model from scratch. While MU itself has been employed to provide privacy protection and regulatory compliance, it can also increase the attack surface of the model. Existing privacy inference attacks towards MU that aim to infer properties of the unlearned set rely on the weaker threat model that assumes the attacker has access to both the unlearned model and the original model, limiting their feasibility toward real-life scenarios. We propose a novel privacy attack, A Posteriori Label-Only Membership Inference Attack towards MU, Apollo, that infers whether a data sample has been unlearned, following a strict threat model where an adversary has access to the label-output of the unlearned model only. We demonstrate that our proposed attack, while requiring less access to the target model compared to previous attacks, can achieve relatively high precision on the membership status of the unlearned samples.
How Good LLM-Generated Password Policies Are?
Jun 10, 2025



Generative AI technologies, particularly Large Language Models (LLMs), are rapidly being adopted across industry, academia, and government sectors, owing to their remarkable capabilities in natural language processing. However, despite their strengths, the inconsistency and unpredictability of LLM outputs present substantial challenges, especially in security-critical domains such as access control. One critical issue that emerges prominently is the consistency of LLM-generated responses, which is paramount for ensuring secure and reliable operations. In this paper, we study the application of LLMs within the context of Cybersecurity Access Control Systems. Specifically, we investigate the consistency and accuracy of LLM-generated password policies, translating natural language prompts into executable pwquality.conf configuration files. Our experimental methodology adopts two distinct approaches: firstly, we utilize pre-trained LLMs to generate configuration files purely from natural language prompts without additional guidance. Secondly, we provide these models with official pwquality.conf documentation to serve as an informative baseline. We systematically assess the soundness, accuracy, and consistency of these AI-generated configurations. Our findings underscore significant challenges in the current generation of LLMs and contribute valuable insights into refining the deployment of LLMs in Access Control Systems.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
Malware Detection at the Edge with Lightweight LLMs: A Performance Evaluation
Mar 06, 2025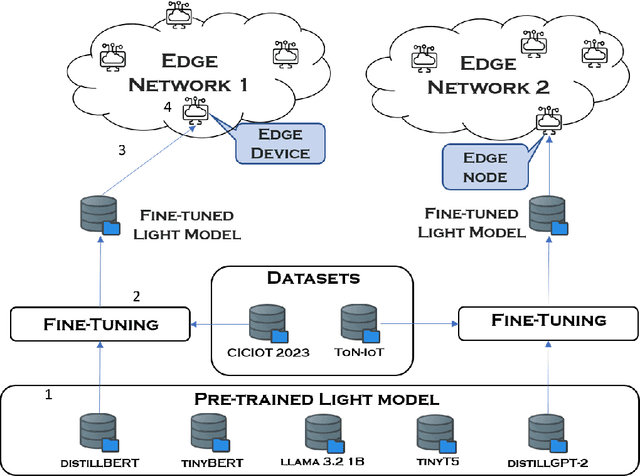
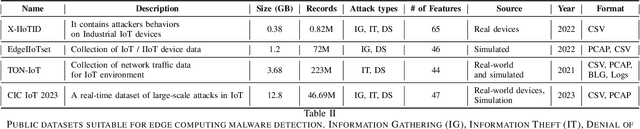


The rapid evolution of malware attacks calls for the development of innovative detection methods, especially in resource-constrained edge computing. Traditional detection techniques struggle to keep up with modern malware's sophistication and adaptability, prompting a shift towards advanced methodologies like those leveraging Large Language Models (LLMs) for enhanced malware detection. However, deploying LLMs for malware detection directly at edge devices raises several challenges, including ensuring accuracy in constrained environments and addressing edge devices' energy and computational limits. To tackle these challenges, this paper proposes an architecture leveraging lightweight LLMs' strengths while addressing limitations like reduced accuracy and insufficient computational power. To evaluate the effectiveness of the proposed lightweight LLM-based approach for edge computing, we perform an extensive experimental evaluation using several state-of-the-art lightweight LLMs. We test them with several publicly available datasets specifically designed for edge and IoT scenarios and different edge nodes with varying computational power and characteristics.