 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApollo: A Posteriori Label-Only Membership Inference Attack Towards Machine Unlearning
Jun 11, 2025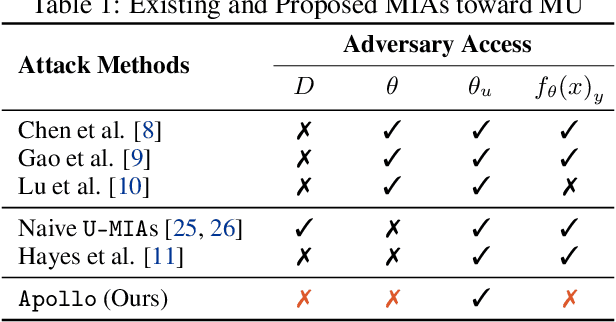
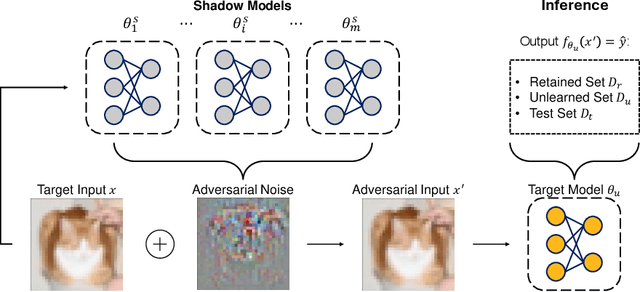
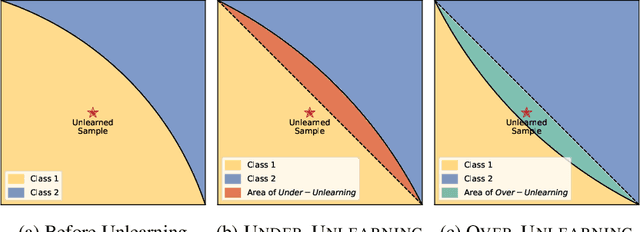

Machine Unlearning (MU) aims to update Machine Learning (ML) models following requests to remove training samples and their influences on a trained model efficiently without retraining the original ML model from scratch. While MU itself has been employed to provide privacy protection and regulatory compliance, it can also increase the attack surface of the model. Existing privacy inference attacks towards MU that aim to infer properties of the unlearned set rely on the weaker threat model that assumes the attacker has access to both the unlearned model and the original model, limiting their feasibility toward real-life scenarios. We propose a novel privacy attack, A Posteriori Label-Only Membership Inference Attack towards MU, Apollo, that infers whether a data sample has been unlearned, following a strict threat model where an adversary has access to the label-output of the unlearned model only. We demonstrate that our proposed attack, while requiring less access to the target model compared to previous attacks, can achieve relatively high precision on the membership status of the unlearned samples.
Dual Defense: Enhancing Privacy and Mitigating Poisoning Attacks in Federated Learning
Feb 08, 2025Federated learning (FL) is inherently susceptible to privacy breaches and poisoning attacks. To tackle these challenges, researchers have separately devised secure aggregation mechanisms to protect data privacy and robust aggregation methods that withstand poisoning attacks. However, simultaneously addressing both concerns is challenging; secure aggregation facilitates poisoning attacks as most anomaly detection techniques require access to unencrypted local model updates, which are obscured by secure aggregation. Few recent efforts to simultaneously tackle both challenges offen depend on impractical assumption of non-colluding two-server setups that disrupt FL's topology, or three-party computation which introduces scalability issues, complicating deployment and application. To overcome this dilemma, this paper introduce a Dual Defense Federated learning (DDFed) framework. DDFed simultaneously boosts privacy protection and mitigates poisoning attacks, without introducing new participant roles or disrupting the existing FL topology. DDFed initially leverages cutting-edge fully homomorphic encryption (FHE) to securely aggregate model updates, without the impractical requirement for non-colluding two-server setups and ensures strong privacy protection. Additionally, we proposes a unique two-phase anomaly detection mechanism for encrypted model updates, featuring secure similarity computation and feedback-driven collaborative selection, with additional measures to prevent potential privacy breaches from Byzantine clients incorporated into the detection process. We conducted extensive experiments on various model poisoning attacks and FL scenarios, including both cross-device and cross-silo FL. Experiments on publicly available datasets demonstrate that DDFed successfully protects model privacy and effectively defends against model poisoning threats.
Privacy-Preserving Machine Learning: Methods, Challenges and Directions
Aug 10, 2021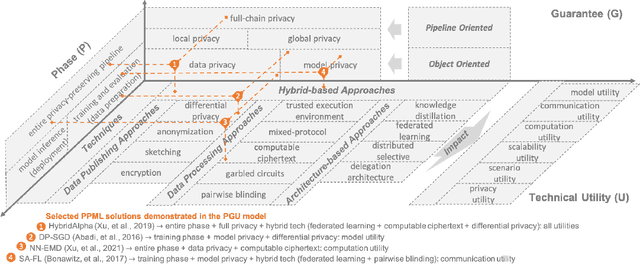
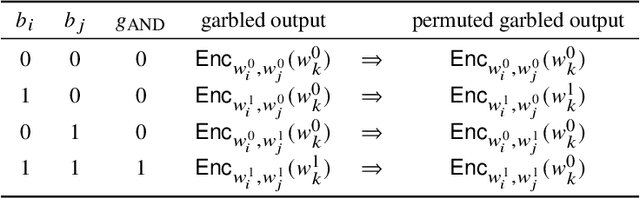
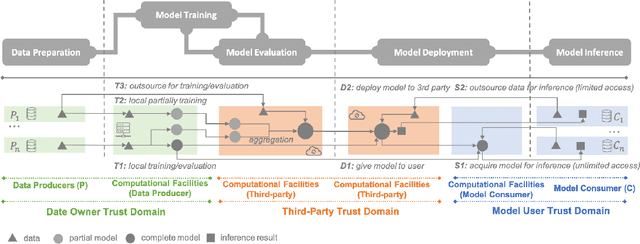

Machine learning (ML) is increasingly being adopted in a wide variety of application domains. Usually, a well-performing ML model, especially, emerging deep neural network model, relies on a large volume of training data and high-powered computational resources. The need for a vast volume of available data raises serious privacy concerns because of the risk of leakage of highly privacy-sensitive information and the evolving regulatory environments that increasingly restrict access to and use of privacy-sensitive data. Furthermore, a trained ML model may also be vulnerable to adversarial attacks such as membership/property inference attacks and model inversion attacks. Hence, well-designed privacy-preserving ML (PPML) solutions are crucial and have attracted increasing research interest from academia and industry. More and more efforts of PPML are proposed via integrating privacy-preserving techniques into ML algorithms, fusing privacy-preserving approaches into ML pipeline, or designing various privacy-preserving architectures for existing ML systems. In particular, existing PPML arts cross-cut ML, system, security, and privacy; hence, there is a critical need to understand state-of-art studies, related challenges, and a roadmap for future research. This paper systematically reviews and summarizes existing privacy-preserving approaches and proposes a PGU model to guide evaluation for various PPML solutions through elaborately decomposing their privacy-preserving functionalities. The PGU model is designed as the triad of Phase, Guarantee, and technical Utility. Furthermore, we also discuss the unique characteristics and challenges of PPML and outline possible directions of future work that benefit a wide range of research communities among ML, distributed systems, security, and privacy areas.
Adaptive ABAC Policy Learning: A Reinforcement Learning Approach
May 18, 2021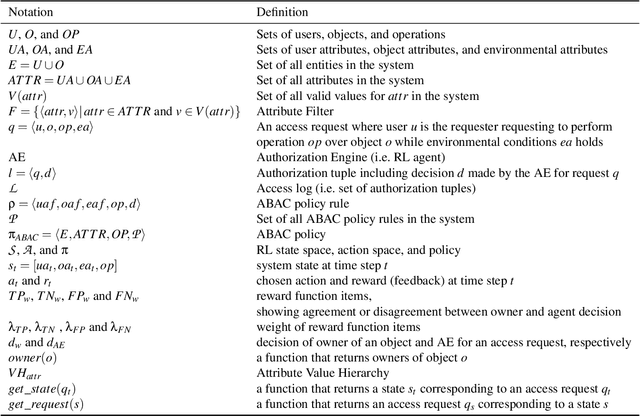
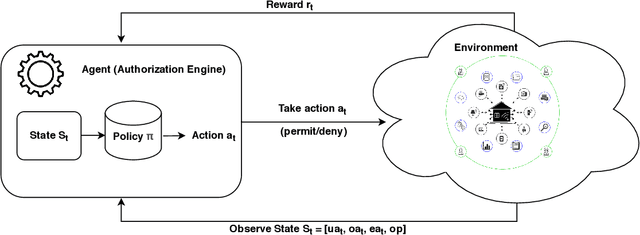

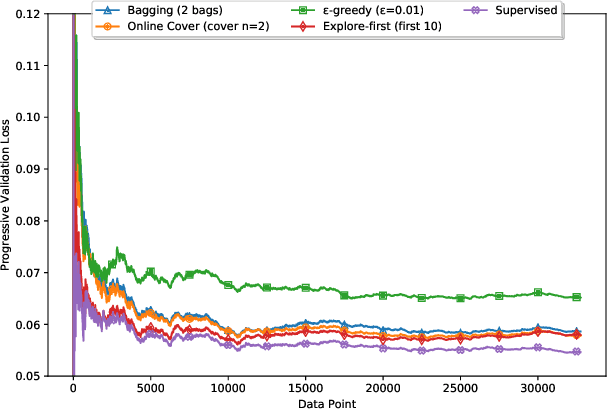
With rapid advances in computing systems, there is an increasing demand for more effective and efficient access control (AC) approaches. Recently, Attribute Based Access Control (ABAC) approaches have been shown to be promising in fulfilling the AC needs of such emerging complex computing environments. An ABAC model grants access to a requester based on attributes of entities in a system and an authorization policy; however, its generality and flexibility come with a higher cost. Further, increasing complexities of organizational systems and the need for federated accesses to their resources make the task of AC enforcement and management much more challenging. In this paper, we propose an adaptive ABAC policy learning approach to automate the authorization management task. We model ABAC policy learning as a reinforcement learning problem. In particular, we propose a contextual bandit system, in which an authorization engine adapts an ABAC model through a feedback control loop; it relies on interacting with users/administrators of the system to receive their feedback that assists the model in making authorization decisions. We propose four methods for initializing the learning model and a planning approach based on attribute value hierarchy to accelerate the learning process. We focus on developing an adaptive ABAC policy learning model for a home IoT environment as a running example. We evaluate our proposed approach over real and synthetic data. We consider both complete and sparse datasets in our evaluations. Our experimental results show that the proposed approach achieves performance that is comparable to ones based on supervised learning in many scenarios and even outperforms them in several situations.
FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data
Mar 05, 2021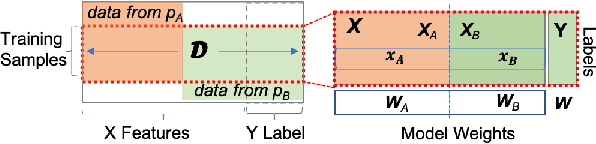


Federated learning (FL) has been proposed to allow collaborative training of machine learning (ML) models among multiple parties where each party can keep its data private. In this paradigm, only model updates, such as model weights or gradients, are shared. Many existing approaches have focused on horizontal FL, where each party has the entire feature set and labels in the training data set. However, many real scenarios follow a vertically-partitioned FL setup, where a complete feature set is formed only when all the datasets from the parties are combined, and the labels are only available to a single party. Privacy-preserving vertical FL is challenging because complete sets of labels and features are not owned by one entity. Existing approaches for vertical FL require multiple peer-to-peer communications among parties, leading to lengthy training times, and are restricted to (approximated) linear models and just two parties. To close this gap, we propose FedV, a framework for secure gradient computation in vertical settings for several widely used ML models such as linear models, logistic regression, and support vector machines. FedV removes the need for peer-to-peer communication among parties by using functional encryption schemes; this allows FedV to achieve faster training times. It also works for larger and changing sets of parties. We empirically demonstrate the applicability for multiple types of ML models and show a reduction of 10%-70% of training time and 80% to 90% in data transfer with respect to the state-of-the-art approaches.
NN-EMD: Efficiently Training Neural Networks using Encrypted Multi-sourced Datasets
Dec 18, 2020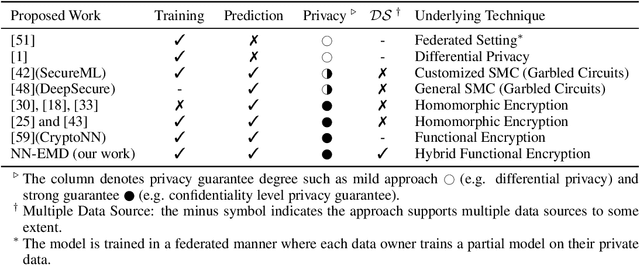
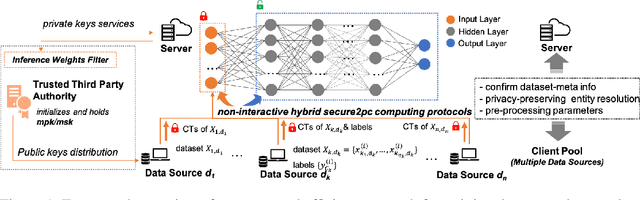
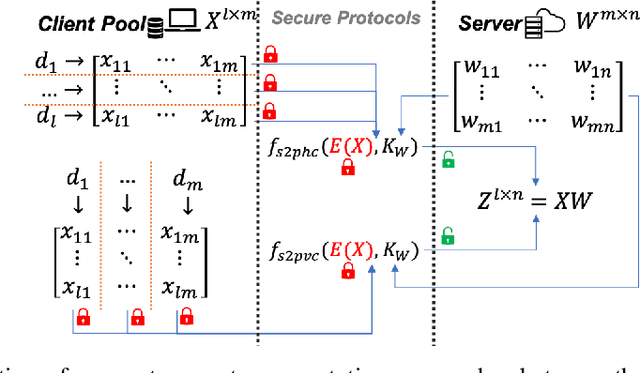
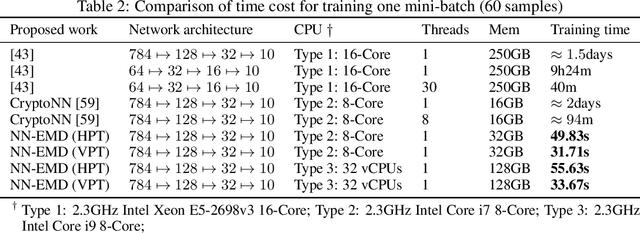
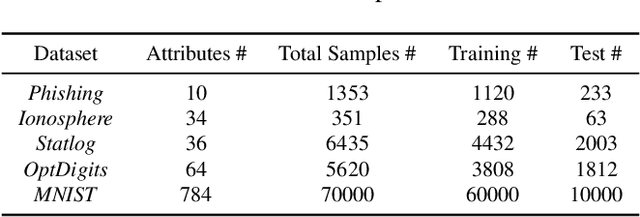
Training a machine learning model over an encrypted dataset is an existing promising approach to address the privacy-preserving machine learning task, however, it is extremely challenging to efficiently train a deep neural network (DNN) model over encrypted data for two reasons: first, it requires large-scale computation over huge datasets; second, the existing solutions for computation over encrypted data, such as homomorphic encryption, is inefficient. Further, for an enhanced performance of a DNN model, we also need to use huge training datasets composed of data from multiple data sources that may not have pre-established trust relationships among each other. We propose a novel framework, NN-EMD, to train DNN over multiple encrypted datasets collected from multiple sources. Toward this, we propose a set of secure computation protocols using hybrid functional encryption schemes. We evaluate our framework for performance with regards to the training time and model accuracy on the MNIST datasets. Compared to other existing frameworks, our proposed NN-EMD framework can significantly reduce the training time, while providing comparable model accuracy and privacy guarantees as well as supporting multiple data sources. Furthermore, the depth and complexity of neural networks do not affect the training time despite introducing a privacy-preserving NN-EMD setting.
An Automatic Attribute Based Access Control Policy Extraction from Access Logs
Mar 17, 2020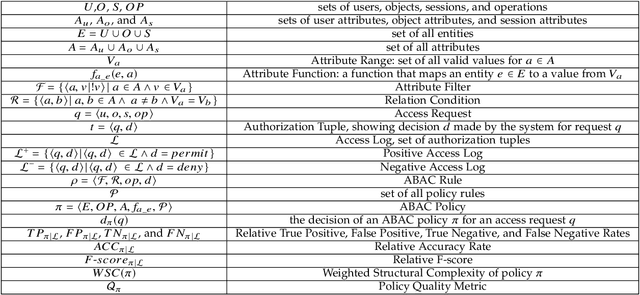


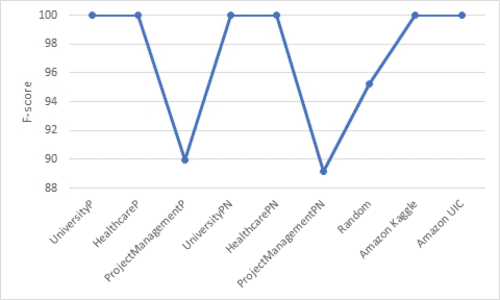
With the rapid advances in computing and information technologies, traditional access control models have become inadequate in terms of capturing fine-grained, and expressive security requirements of newly emerging applications. An attribute-based access control (ABAC) model provides a more flexible approach for addressing the authorization needs of complex and dynamic systems. While organizations are interested in employing newer authorization models, migrating to such models pose as a significant challenge. Many large-scale businesses need to grant authorization to their user populations that are potentially distributed across disparate and heterogeneous computing environments. Each of these computing environments may have its own access control model. The manual development of a single policy framework for an entire organization is tedious, costly, and error-prone. In this paper, we present a methodology for automatically learning ABAC policy rules from access logs of a system to simplify the policy development process. The proposed approach employs an unsupervised learning-based algorithm for detecting patterns in access logs and extracting ABAC authorization rules from these patterns. In addition, we present two policy improvement algorithms, including rule pruning and policy refinement algorithms to generate a higher quality mined policy. Finally, we implement a prototype of the proposed approach to demonstrate its feasibility.