 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Data is the Algorithm: A Systematic Study and Curation of Preference Optimization Datasets
Nov 14, 2025Aligning large language models (LLMs) is a central objective of post-training, often achieved through reward modeling and reinforcement learning methods. Among these, direct preference optimization (DPO) has emerged as a widely adopted technique that fine-tunes LLMs on preferred completions over less favorable ones. While most frontier LLMs do not disclose their curated preference pairs, the broader LLM community has released several open-source DPO datasets, including TuluDPO, ORPO, UltraFeedback, HelpSteer, and Code-Preference-Pairs. However, systematic comparisons remain scarce, largely due to the high computational cost and the lack of rich quality annotations, making it difficult to understand how preferences were selected, which task types they span, and how well they reflect human judgment on a per-sample level. In this work, we present the first comprehensive, data-centric analysis of popular open-source DPO corpora. We leverage the Magpie framework to annotate each sample for task category, input quality, and preference reward, a reward-model-based signal that validates the preference order without relying on human annotations. This enables a scalable, fine-grained inspection of preference quality across datasets, revealing structural and qualitative discrepancies in reward margins. Building on these insights, we systematically curate a new DPO mixture, UltraMix, that draws selectively from all five corpora while removing noisy or redundant samples. UltraMix is 30% smaller than the best-performing individual dataset yet exceeds its performance across key benchmarks. We publicly release all annotations, metadata, and our curated mixture to facilitate future research in data-centric preference optimization.
Fixing It in Post: A Comparative Study of LLM Post-Training Data Quality and Model Performance
Jun 06, 2025


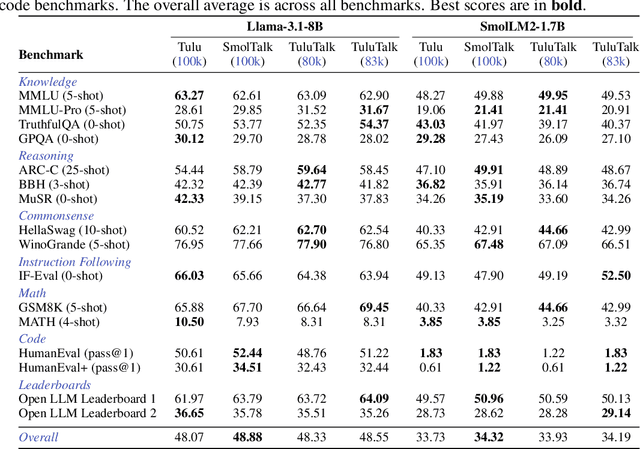
Recent work on large language models (LLMs) has increasingly focused on post-training and alignment with datasets curated to enhance instruction following, world knowledge, and specialized skills. However, most post-training datasets used in leading open- and closed-source LLMs remain inaccessible to the public, with limited information about their construction process. This lack of transparency has motivated the recent development of open-source post-training corpora. While training on these open alternatives can yield performance comparable to that of leading models, systematic comparisons remain challenging due to the significant computational cost of conducting them rigorously at scale, and are therefore largely absent. As a result, it remains unclear how specific samples, task types, or curation strategies influence downstream performance when assessing data quality. In this work, we conduct the first comprehensive side-by-side analysis of two prominent open post-training datasets: Tulu-3-SFT-Mix and SmolTalk. Using the Magpie framework, we annotate each sample with detailed quality metrics, including turn structure (single-turn vs. multi-turn), task category, input quality, and response quality, and we derive statistics that reveal structural and qualitative similarities and differences between the two datasets. Based on these insights, we design a principled curation recipe that produces a new data mixture, TuluTalk, which contains 14% fewer samples than either source dataset while matching or exceeding their performance on key benchmarks. Our findings offer actionable insights for constructing more effective post-training datasets that improve model performance within practical resource limits. To support future research, we publicly release both the annotated source datasets and our curated TuluTalk mixture.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.
Single-shot Hyper-parameter Optimization for Federated Learning: A General Algorithm & Analysis
Feb 16, 2022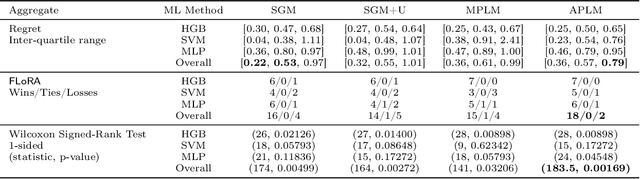
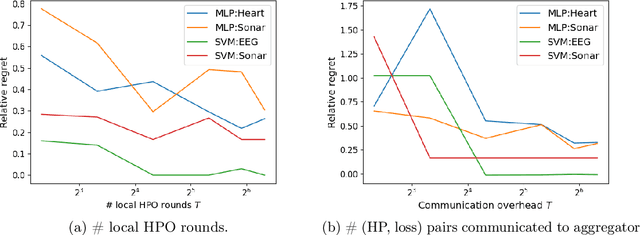
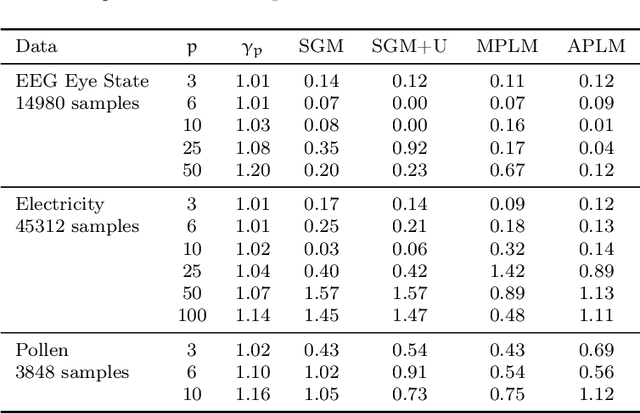

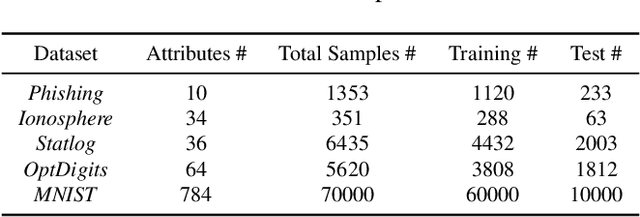
We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss SuRface Aggregation (FLoRA), a general FL-HPO solution framework that can address use cases of tabular data and any Machine Learning (ML) model including gradient boosting training algorithms and therefore further expands the scope of FL-HPO. FLoRA enables single-shot FL-HPO: identifying a single set of good hyper-parameters that are subsequently used in a single FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. We theoretically characterize the optimality gap of FL-HPO, which explicitly accounts for the heterogeneous non-IID nature of the parties' local data distributions, a dominant characteristic of FL systems. Our empirical evaluation of FLoRA for multiple ML algorithms on seven OpenML datasets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
FLoRA: Single-shot Hyper-parameter Optimization for Federated Learning
Dec 15, 2021
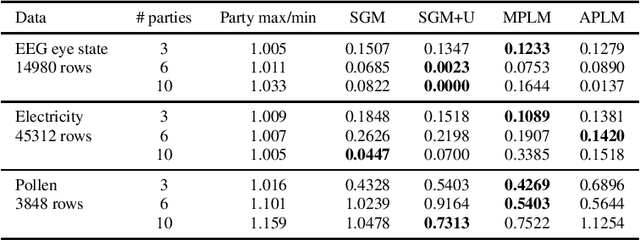

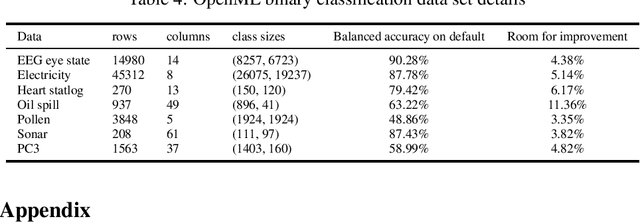
We address the relatively unexplored problem of hyper-parameter optimization (HPO) for federated learning (FL-HPO). We introduce Federated Loss suRface Aggregation (FLoRA), the first FL-HPO solution framework that can address use cases of tabular data and gradient boosting training algorithms in addition to stochastic gradient descent/neural networks commonly addressed in the FL literature. The framework enables single-shot FL-HPO, by first identifying a good set of hyper-parameters that are used in a **single** FL training. Thus, it enables FL-HPO solutions with minimal additional communication overhead compared to FL training without HPO. Our empirical evaluation of FLoRA for Gradient Boosted Decision Trees on seven OpenML data sets demonstrates significant model accuracy improvements over the considered baseline, and robustness to increasing number of parties involved in FL-HPO training.
FedV: Privacy-Preserving Federated Learning over Vertically Partitioned Data
Mar 05, 2021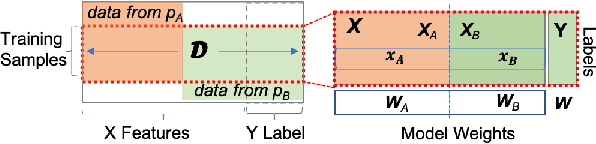


Federated learning (FL) has been proposed to allow collaborative training of machine learning (ML) models among multiple parties where each party can keep its data private. In this paradigm, only model updates, such as model weights or gradients, are shared. Many existing approaches have focused on horizontal FL, where each party has the entire feature set and labels in the training data set. However, many real scenarios follow a vertically-partitioned FL setup, where a complete feature set is formed only when all the datasets from the parties are combined, and the labels are only available to a single party. Privacy-preserving vertical FL is challenging because complete sets of labels and features are not owned by one entity. Existing approaches for vertical FL require multiple peer-to-peer communications among parties, leading to lengthy training times, and are restricted to (approximated) linear models and just two parties. To close this gap, we propose FedV, a framework for secure gradient computation in vertical settings for several widely used ML models such as linear models, logistic regression, and support vector machines. FedV removes the need for peer-to-peer communication among parties by using functional encryption schemes; this allows FedV to achieve faster training times. It also works for larger and changing sets of parties. We empirically demonstrate the applicability for multiple types of ML models and show a reduction of 10%-70% of training time and 80% to 90% in data transfer with respect to the state-of-the-art approaches.
Adaptive Histogram-Based Gradient Boosted Trees for Federated Learning
Dec 11, 2020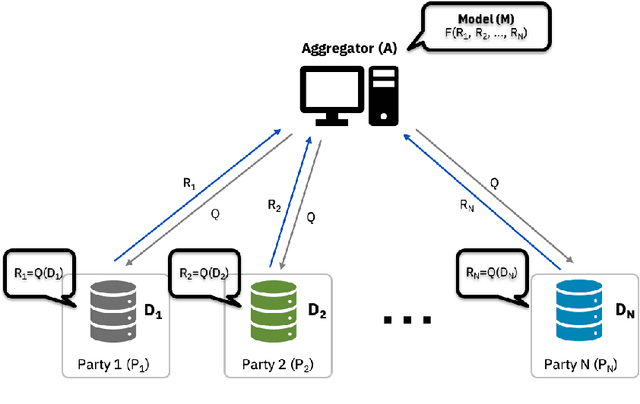
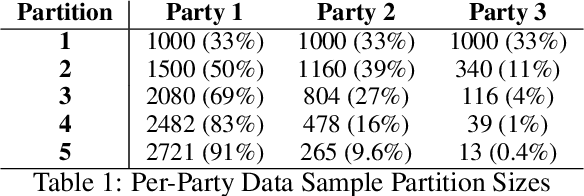


Federated Learning (FL) is an approach to collaboratively train a model across multiple parties without sharing data between parties or an aggregator. It is used both in the consumer domain to protect personal data as well as in enterprise settings, where dealing with data domicile regulation and the pragmatics of data silos are the main drivers. While gradient boosted tree implementations such as XGBoost have been very successful for many use cases, its federated learning adaptations tend to be very slow due to using cryptographic and privacy methods and have not experienced widespread use. We propose the Party-Adaptive XGBoost (PAX) for federated learning, a novel implementation of gradient boosting which utilizes a party adaptive histogram aggregation method, without the need for data encryption. It constructs a surrogate representation of the data distribution for finding splits of the decision tree. Our experimental results demonstrate strong model performance, especially on non-IID distributions, and significantly faster training run-time across different data sets than existing federated implementations. This approach makes the use of gradient boosted trees practical in enterprise federated learning.
Mitigating Bias in Federated Learning
Dec 04, 2020
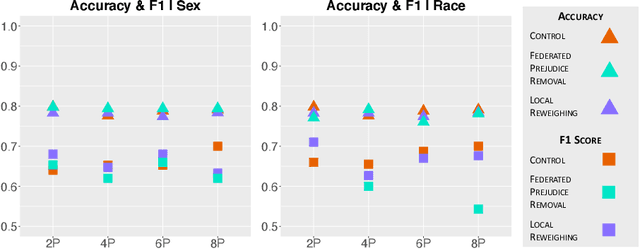
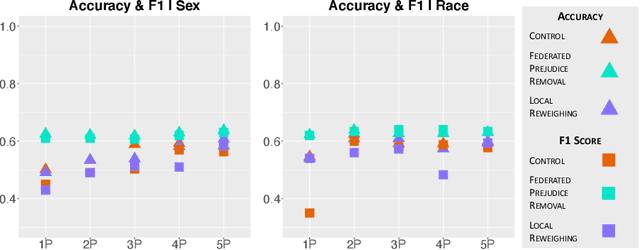
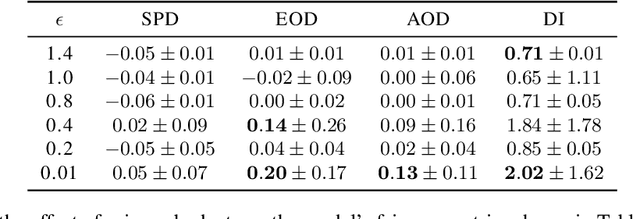
As methods to create discrimination-aware models develop, they focus on centralized ML, leaving federated learning (FL) unexplored. FL is a rising approach for collaborative ML, in which an aggregator orchestrates multiple parties to train a global model without sharing their training data. In this paper, we discuss causes of bias in FL and propose three pre-processing and in-processing methods to mitigate bias, without compromising data privacy, a key FL requirement. As data heterogeneity among parties is one of the challenging characteristics of FL, we conduct experiments over several data distributions to analyze their effects on model performance, fairness metrics, and bias learning patterns. We conduct a comprehensive analysis of our proposed techniques, the results demonstrating that these methods are effective even when parties have skewed data distributions or as little as 20% of parties employ the methods.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020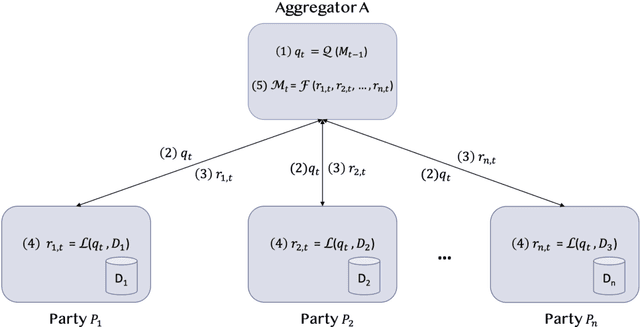
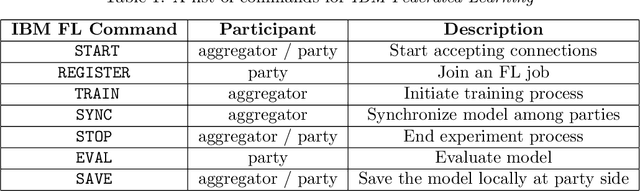
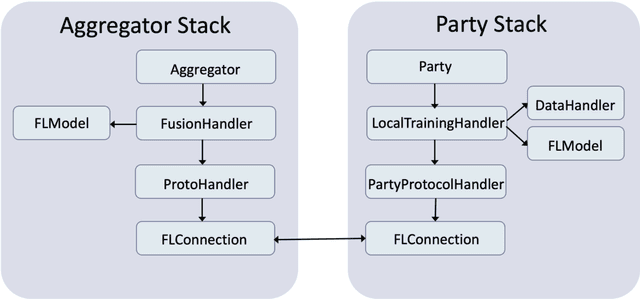
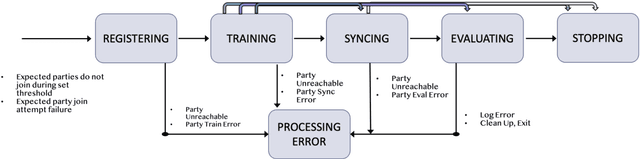
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.