 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
FLIPS: Federated Learning using Intelligent Participant Selection
Aug 07, 2023This paper presents the design and implementation of FLIPS, a middleware system to manage data and participant heterogeneity in federated learning (FL) training workloads. In particular, we examine the benefits of label distribution clustering on participant selection in federated learning. FLIPS clusters parties involved in an FL training job based on the label distribution of their data apriori, and during FL training, ensures that each cluster is equitably represented in the participants selected. FLIPS can support the most common FL algorithms, including FedAvg, FedProx, FedDyn, FedOpt and FedYogi. To manage platform heterogeneity and dynamic resource availability, FLIPS incorporates a straggler management mechanism to handle changing capacities in distributed, smart community applications. Privacy of label distributions, clustering and participant selection is ensured through a trusted execution environment (TEE). Our comprehensive empirical evaluation compares FLIPS with random participant selection, as well as two other "smart" selection mechanisms - Oort and gradient clustering using two real-world datasets, two different non-IID distributions and three common FL algorithms (FedYogi, FedProx and FedAvg). We demonstrate that FLIPS significantly improves convergence, achieving higher accuracy by 17 - 20 % with 20 - 60 % lower communication costs, and these benefits endure in the presence of straggler participants.
MYSTIKO : : Cloud-Mediated, Private, Federated Gradient Descent
Dec 01, 2020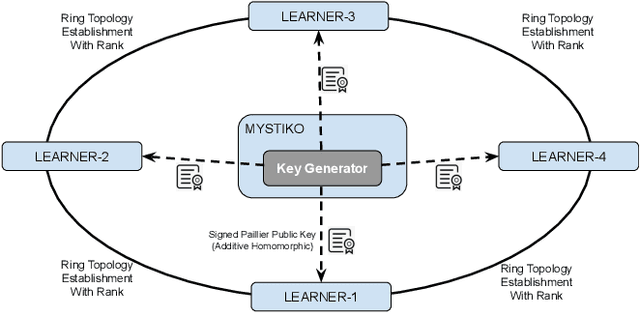
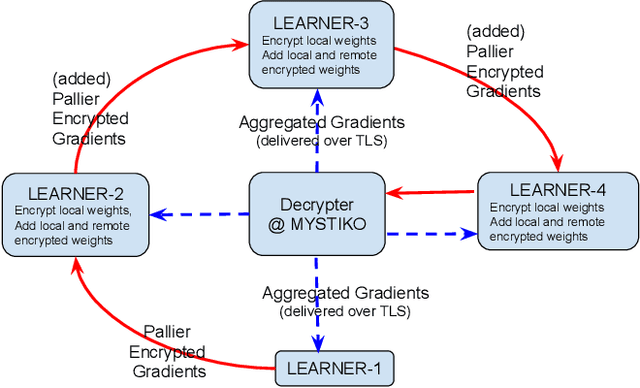

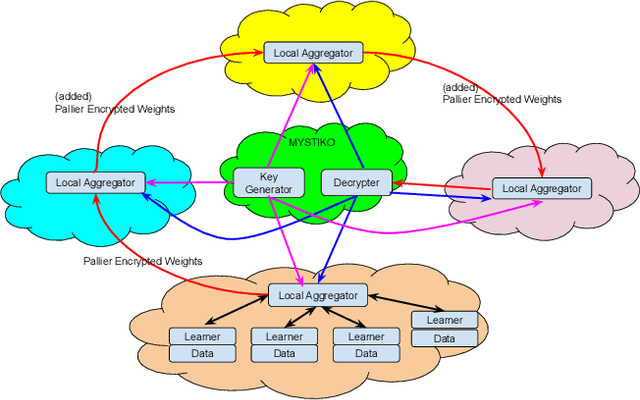
Federated learning enables multiple, distributed participants (potentially on different clouds) to collaborate and train machine/deep learning models by sharing parameters/gradients. However, sharing gradients, instead of centralizing data, may not be as private as one would expect. Reverse engineering attacks on plaintext gradients have been demonstrated to be practically feasible. Existing solutions for differentially private federated learning, while promising, lead to less accurate models and require nontrivial hyperparameter tuning. In this paper, we examine the use of additive homomorphic encryption (specifically the Paillier cipher) to design secure federated gradient descent techniques that (i) do not require addition of statistical noise or hyperparameter tuning, (ii) does not alter the final accuracy or utility of the final model, (iii) ensure that the plaintext model parameters/gradients of a participant are never revealed to any other participant or third party coordinator involved in the federated learning job, (iv) minimize the trust placed in any third party coordinator and (v) are efficient, with minimal overhead, and cost effective.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020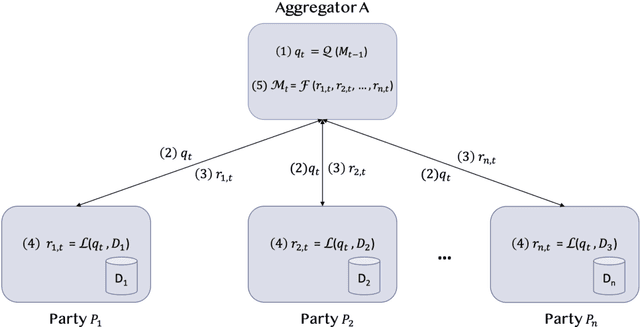
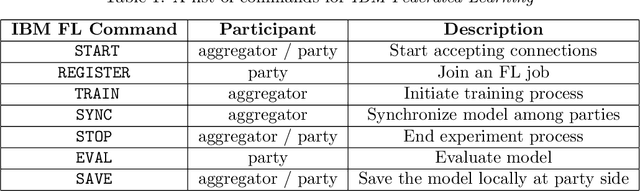
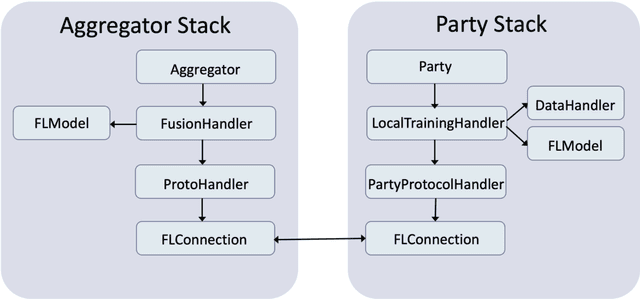
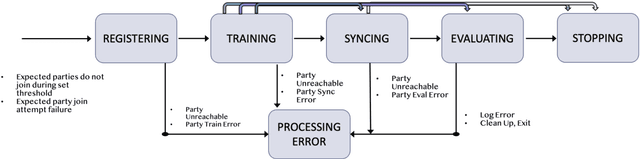
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019
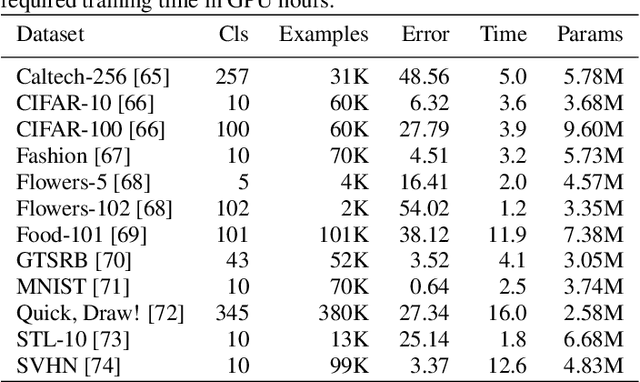
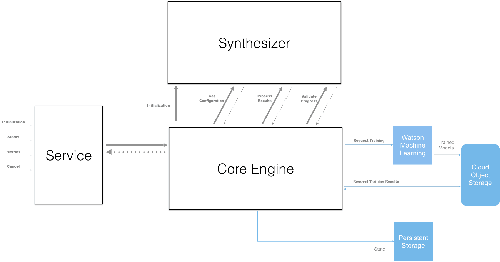
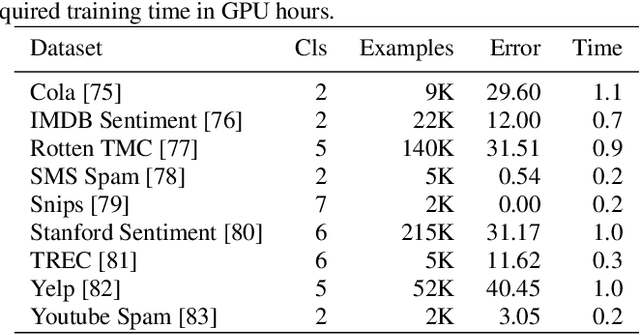
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.