 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMYSTIKO : : Cloud-Mediated, Private, Federated Gradient Descent
Dec 01, 2020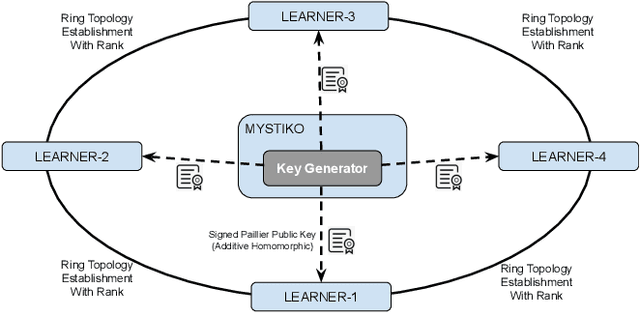
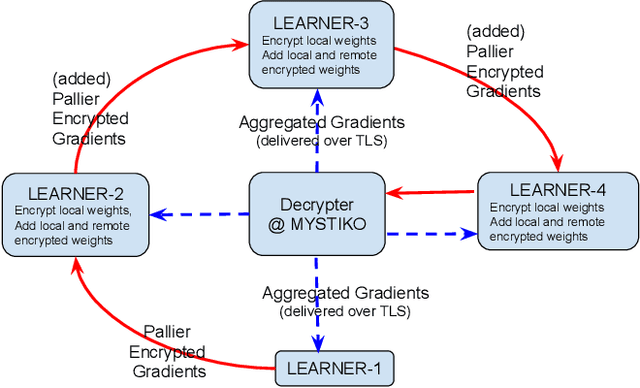

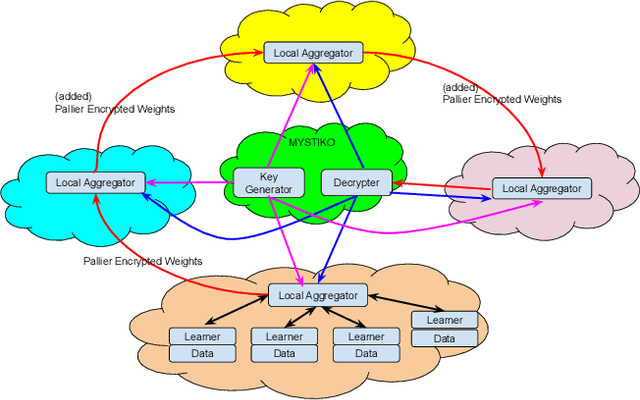
Federated learning enables multiple, distributed participants (potentially on different clouds) to collaborate and train machine/deep learning models by sharing parameters/gradients. However, sharing gradients, instead of centralizing data, may not be as private as one would expect. Reverse engineering attacks on plaintext gradients have been demonstrated to be practically feasible. Existing solutions for differentially private federated learning, while promising, lead to less accurate models and require nontrivial hyperparameter tuning. In this paper, we examine the use of additive homomorphic encryption (specifically the Paillier cipher) to design secure federated gradient descent techniques that (i) do not require addition of statistical noise or hyperparameter tuning, (ii) does not alter the final accuracy or utility of the final model, (iii) ensure that the plaintext model parameters/gradients of a participant are never revealed to any other participant or third party coordinator involved in the federated learning job, (iv) minimize the trust placed in any third party coordinator and (v) are efficient, with minimal overhead, and cost effective.
Nonparametric Deconvolution Models
Mar 17, 2020
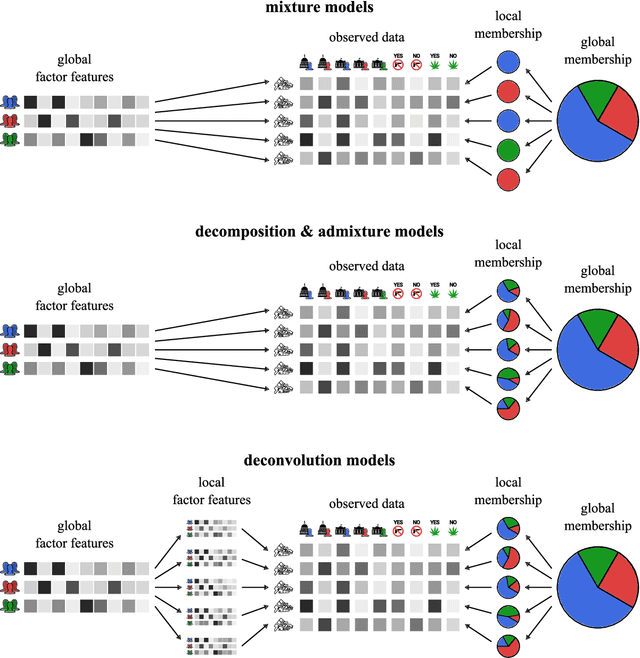
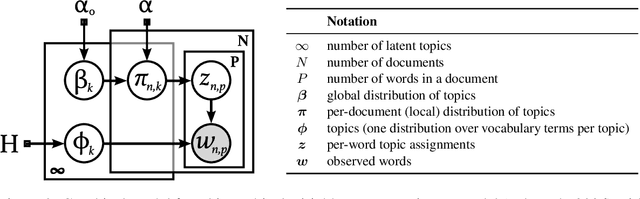

We describe nonparametric deconvolution models (NDMs), a family of Bayesian nonparametric models for collections of data in which each observation is the average over the features from heterogeneous particles. For example, these types of data are found in elections, where we observe precinct-level vote tallies (observations) of individual citizens' votes (particles) across each of the candidates or ballot measures (features), where each voter is part of a specific voter cohort or demographic (factor). Like the hierarchical Dirichlet process, NDMs rely on two tiers of Dirichlet processes to explain the data with an unknown number of latent factors; each observation is modeled as a weighted average of these latent factors. Unlike existing models, NDMs recover how factor distributions vary locally for each observation. This uniquely allows NDMs both to deconvolve each observation into its constituent factors, and also to describe how the factor distributions specific to each observation vary across observations and deviate from the corresponding global factors. We present variational inference techniques for this family of models and study its performance on simulated data and voting data from California. We show that including local factors improves estimates of global factors and provides a novel scaffold for exploring data.
FfDL : A Flexible Multi-tenant Deep Learning Platform
Sep 14, 2019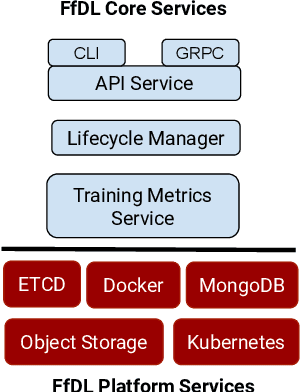

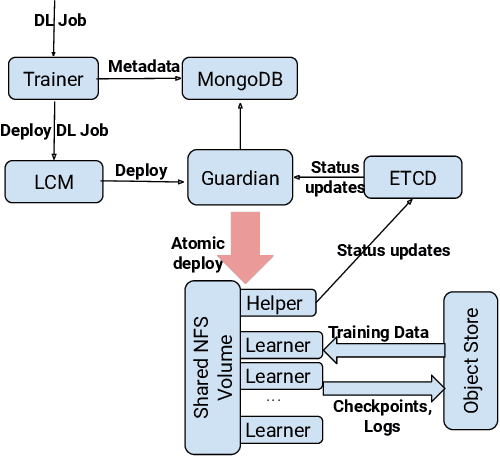
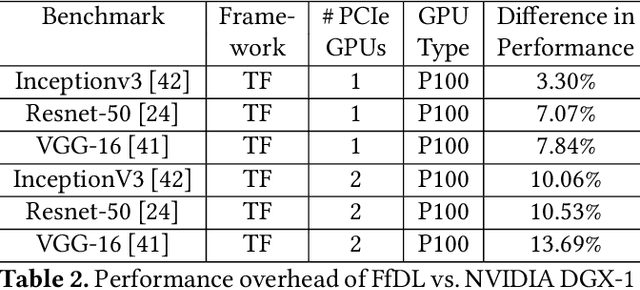
Deep learning (DL) is becoming increasingly popular in several application domains and has made several new application features involving computer vision, speech recognition and synthesis, self-driving automobiles, drug design, etc. feasible and accurate. As a result, large scale on-premise and cloud-hosted deep learning platforms have become essential infrastructure in many organizations. These systems accept, schedule, manage and execute DL training jobs at scale. This paper describes the design, implementation and our experiences with FfDL, a DL platform used at IBM. We describe how our design balances dependability with scalability, elasticity, flexibility and efficiency. We examine FfDL qualitatively through a retrospective look at the lessons learned from building, operating, and supporting FfDL; and quantitatively through a detailed empirical evaluation of FfDL, including the overheads introduced by the platform for various deep learning models, the load and performance observed in a real case study using FfDL within our organization, the frequency of various faults observed including unanticipated faults, and experiments demonstrating the benefits of various scheduling policies. FfDL has been open-sourced.