 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommendation System Simulations: A Discussion of Two Key Challenges
Aug 25, 2021As recommendation systems become increasingly standard for online platforms, simulations provide an avenue for understanding the impacts of these systems on individuals and society. When constructing a recommendation system simulation, there are two key challenges: first, defining a model for users selecting or engaging with recommended items and second, defining a mechanism for users encountering items that are not recommended to the user directly by the platform, such as by a friend sharing specific content. This paper will delve into both of these challenges, reviewing simulation assumptions from existing research and proposing alternative assumptions. We also include a broader discussion of the limitations of simulations and outline of open questions in this area.
Nonparametric Deconvolution Models
Mar 17, 2020
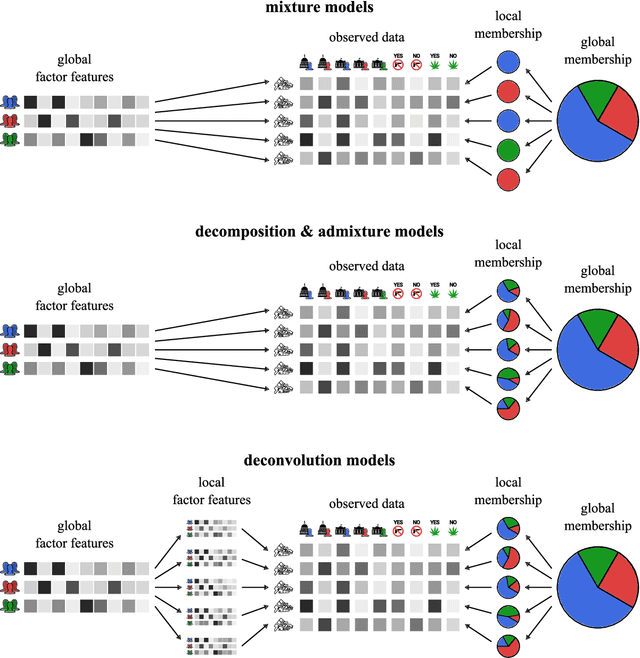
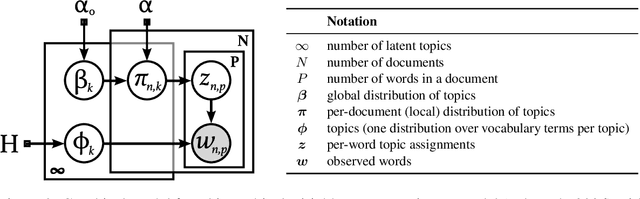

We describe nonparametric deconvolution models (NDMs), a family of Bayesian nonparametric models for collections of data in which each observation is the average over the features from heterogeneous particles. For example, these types of data are found in elections, where we observe precinct-level vote tallies (observations) of individual citizens' votes (particles) across each of the candidates or ballot measures (features), where each voter is part of a specific voter cohort or demographic (factor). Like the hierarchical Dirichlet process, NDMs rely on two tiers of Dirichlet processes to explain the data with an unknown number of latent factors; each observation is modeled as a weighted average of these latent factors. Unlike existing models, NDMs recover how factor distributions vary locally for each observation. This uniquely allows NDMs both to deconvolve each observation into its constituent factors, and also to describe how the factor distributions specific to each observation vary across observations and deviate from the corresponding global factors. We present variational inference techniques for this family of models and study its performance on simulated data and voting data from California. We show that including local factors improves estimates of global factors and provides a novel scaffold for exploring data.
How Algorithmic Confounding in Recommendation Systems Increases Homogeneity and Decreases Utility
Oct 30, 2017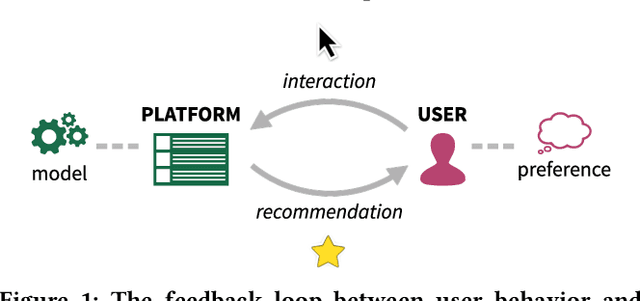
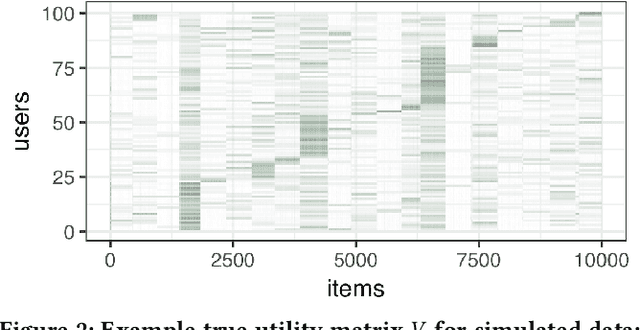
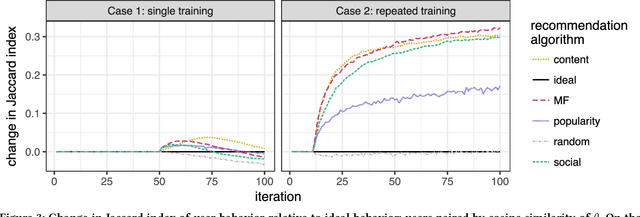
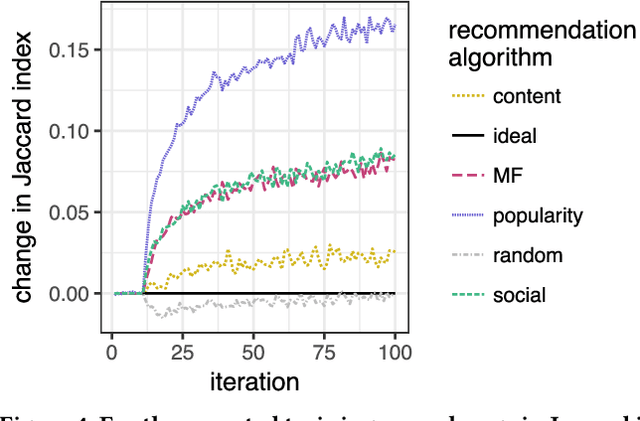
Recommendation systems occupy an expanding role in everyday decision making, from choice of movies and household goods to consequential medical and legal decisions. The data used to train and test these systems is algorithmically confounded in that it is the result of a feedback loop between human choices and an existing algorithmic recommendation system. Using simulations, we demonstrate that algorithmic confounding can disadvantage algorithms in training, bias held-out evaluation, and amplify homogenization of user behavior without gains in utility.