 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Informed Memory Generation for Self-Improving Agent Systems
Mar 11, 2026LLM-powered agents face a persistent challenge: learning from their execution experiences to improve future performance. While agents can successfully complete many tasks, they often repeat inefficient patterns, fail to recover from similar errors, and miss opportunities to apply successful strategies from past executions. We present a novel framework for automatically extracting actionable learnings from agent execution trajectories and utilizing them to improve future performance through contextual memory retrieval. Our approach comprises four components: (1) a Trajectory Intelligence Extractor that performs semantic analysis of agent reasoning patterns, (2) a Decision Attribution Analyzer that identifies which decisions and reasoning steps led to failures, recoveries, or inefficiencies, (3) a Contextual Learning Generator that produces three types of guidance -- strategy tips from successful patterns, recovery tips from failure handling, and optimization tips from inefficient but successful executions, and (4) an Adaptive Memory Retrieval System that injects relevant learnings into agent prompts based on multi-dimensional similarity. Unlike existing memory systems that store generic conversational facts, our framework understands execution patterns, extracts structured learnings with provenance, and retrieves guidance tailored to specific task contexts. Evaluation on the AppWorld benchmark demonstrates consistent improvements, with up to 14.3 percentage point gains in scenario goal completion on held-out tasks and particularly strong benefits on complex tasks (28.5~pp scenario goal improvement, a 149\% relative increase).
VOILA: Value-of-Information Guided Fidelity Selection for Cost-Aware Multimodal Question Answering
Feb 03, 2026Despite significant costs from retrieving and processing high-fidelity visual inputs, most multimodal vision-language systems operate at fixed fidelity levels. We introduce VOILA, a framework for Value-Of-Information-driven adaptive fidelity selection in Visual Question Answering (VQA) that optimizes what information to retrieve before model execution. Given a query, VOILA uses a two-stage pipeline: a gradient-boosted regressor estimates correctness likelihood at each fidelity from question features alone, then an isotonic calibrator refines these probabilities for reliable decision-making. The system selects the minimum-cost fidelity maximizing expected utility given predicted accuracy and retrieval costs. We evaluate VOILA across three deployment scenarios using five datasets (VQA-v2, GQA, TextVQA, LoCoMo, FloodNet) and six Vision-Language Models (VLMs) with 7B-235B parameters. VOILA consistently achieves 50-60% cost reductions while retaining 90-95% of full-resolution accuracy across diverse query types and model architectures, demonstrating that pre-retrieval fidelity selection is vital to optimize multimodal inference under resource constraints.
Shift Happens: Mixture of Experts based Continual Adaptation in Federated Learning
Jun 23, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing raw data, yet faces significant challenges in real-world settings where client data distributions evolve dynamically over time. This paper tackles the critical problem of covariate and label shifts in streaming FL environments, where non-stationary data distributions degrade model performance and require adaptive middleware solutions. We introduce ShiftEx, a shift-aware mixture of experts framework that dynamically creates and trains specialized global models in response to detected distribution shifts using Maximum Mean Discrepancy for covariate shifts. The framework employs a latent memory mechanism for expert reuse and implements facility location-based optimization to jointly minimize covariate mismatch, expert creation costs, and label imbalance. Through theoretical analysis and comprehensive experiments on benchmark datasets, we demonstrate 5.5-12.9 percentage point accuracy improvements and 22-95 % faster adaptation compared to state-of-the-art FL baselines across diverse shift scenarios. The proposed approach offers a scalable, privacy-preserving middleware solution for FL systems operating in non-stationary, real-world conditions while minimizing communication and computational overhead.
On Automating Security Policies with Contemporary LLMs
Jun 05, 2025The complexity of modern computing environments and the growing sophistication of cyber threats necessitate a more robust, adaptive, and automated approach to security enforcement. In this paper, we present a framework leveraging large language models (LLMs) for automating attack mitigation policy compliance through an innovative combination of in-context learning and retrieval-augmented generation (RAG). We begin by describing how our system collects and manages both tool and API specifications, storing them in a vector database to enable efficient retrieval of relevant information. We then detail the architectural pipeline that first decomposes high-level mitigation policies into discrete tasks and subsequently translates each task into a set of actionable API calls. Our empirical evaluation, conducted using publicly available CTI policies in STIXv2 format and Windows API documentation, demonstrates significant improvements in precision, recall, and F1-score when employing RAG compared to a non-RAG baseline.
FLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
OptiSeq: Optimizing Example Ordering for In-Context Learning
Jan 25, 2025Developers using LLMs in their applications and agents have provided plenty of anecdotal evidence that in-context-learning (ICL) is fragile. In addition to the quantity and quality of examples, we show that the order in which the in-context examples are listed in the prompt affects the output of the LLM and, consequently, their performance. In this paper, we present OptiSeq, which introduces a score based on log probabilities of LLM outputs to prune the universe of possible example orderings in few-shot ICL and recommend the best order(s) by distinguishing between correct and incorrect outputs resulting from different order permutations. Through a detailed empirical evaluation on multiple LLMs, datasets and prompts, we demonstrate that OptiSeq improves accuracy by 6 - 10.5 percentage points across multiple tasks.
FLIPS: Federated Learning using Intelligent Participant Selection
Aug 07, 2023This paper presents the design and implementation of FLIPS, a middleware system to manage data and participant heterogeneity in federated learning (FL) training workloads. In particular, we examine the benefits of label distribution clustering on participant selection in federated learning. FLIPS clusters parties involved in an FL training job based on the label distribution of their data apriori, and during FL training, ensures that each cluster is equitably represented in the participants selected. FLIPS can support the most common FL algorithms, including FedAvg, FedProx, FedDyn, FedOpt and FedYogi. To manage platform heterogeneity and dynamic resource availability, FLIPS incorporates a straggler management mechanism to handle changing capacities in distributed, smart community applications. Privacy of label distributions, clustering and participant selection is ensured through a trusted execution environment (TEE). Our comprehensive empirical evaluation compares FLIPS with random participant selection, as well as two other "smart" selection mechanisms - Oort and gradient clustering using two real-world datasets, two different non-IID distributions and three common FL algorithms (FedYogi, FedProx and FedAvg). We demonstrate that FLIPS significantly improves convergence, achieving higher accuracy by 17 - 20 % with 20 - 60 % lower communication costs, and these benefits endure in the presence of straggler participants.
Separation of Powers in Federated Learning
May 19, 2021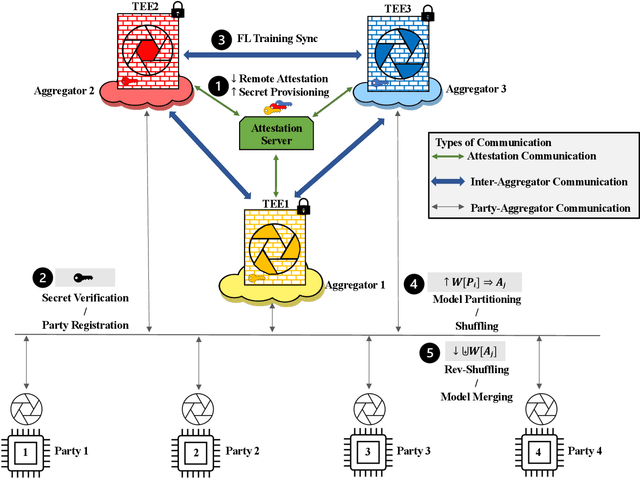
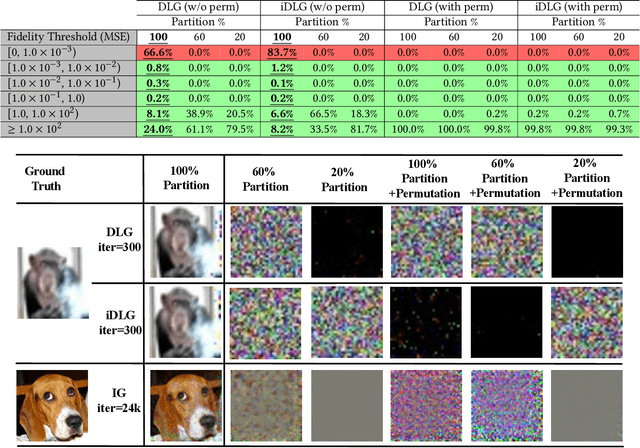
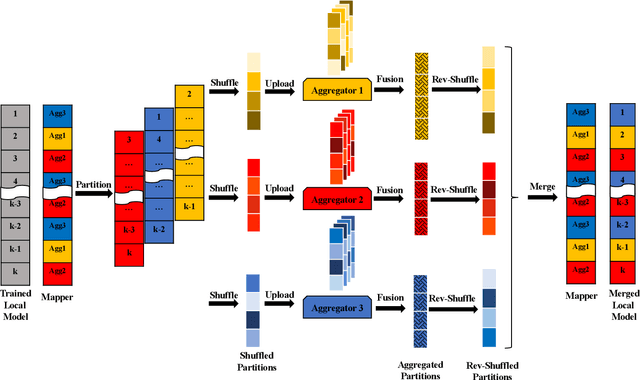

Federated Learning (FL) enables collaborative training among mutually distrusting parties. Model updates, rather than training data, are concentrated and fused in a central aggregation server. A key security challenge in FL is that an untrustworthy or compromised aggregation process might lead to unforeseeable information leakage. This challenge is especially acute due to recently demonstrated attacks that have reconstructed large fractions of training data from ostensibly "sanitized" model updates. In this paper, we introduce TRUDA, a new cross-silo FL system, employing a trustworthy and decentralized aggregation architecture to break down information concentration with regard to a single aggregator. Based on the unique computational properties of model-fusion algorithms, all exchanged model updates in TRUDA are disassembled at the parameter-granularity and re-stitched to random partitions designated for multiple TEE-protected aggregators. Thus, each aggregator only has a fragmentary and shuffled view of model updates and is oblivious to the model architecture. Our new security mechanisms can fundamentally mitigate training reconstruction attacks, while still preserving the final accuracy of trained models and keeping performance overheads low.
MYSTIKO : : Cloud-Mediated, Private, Federated Gradient Descent
Dec 01, 2020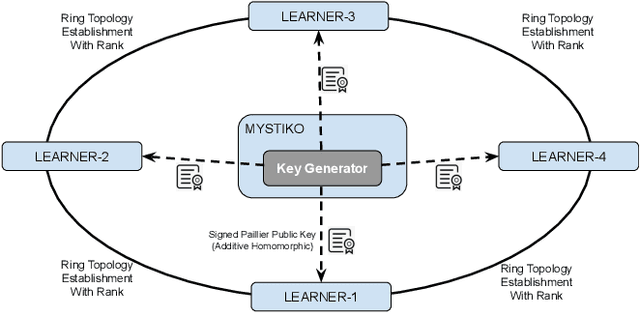
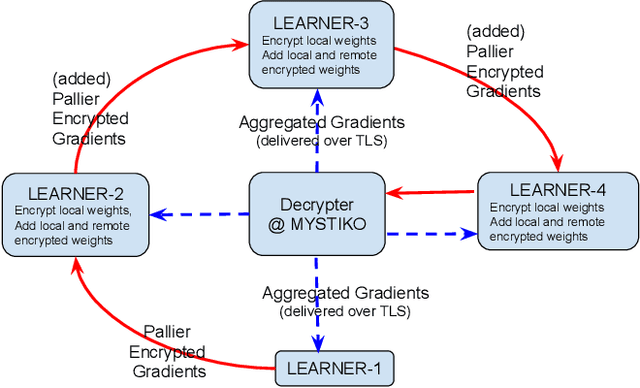

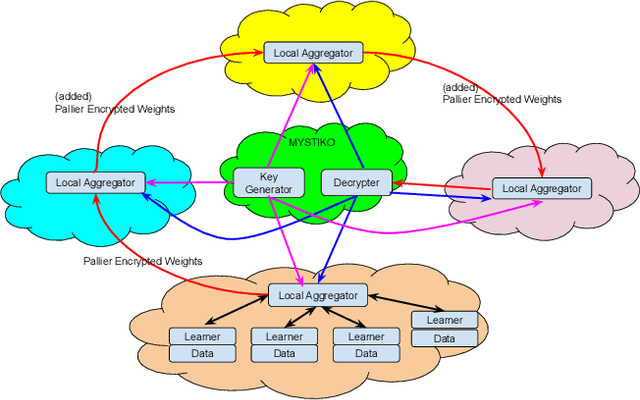
Federated learning enables multiple, distributed participants (potentially on different clouds) to collaborate and train machine/deep learning models by sharing parameters/gradients. However, sharing gradients, instead of centralizing data, may not be as private as one would expect. Reverse engineering attacks on plaintext gradients have been demonstrated to be practically feasible. Existing solutions for differentially private federated learning, while promising, lead to less accurate models and require nontrivial hyperparameter tuning. In this paper, we examine the use of additive homomorphic encryption (specifically the Paillier cipher) to design secure federated gradient descent techniques that (i) do not require addition of statistical noise or hyperparameter tuning, (ii) does not alter the final accuracy or utility of the final model, (iii) ensure that the plaintext model parameters/gradients of a participant are never revealed to any other participant or third party coordinator involved in the federated learning job, (iv) minimize the trust placed in any third party coordinator and (v) are efficient, with minimal overhead, and cost effective.
Effective Elastic Scaling of Deep Learning Workloads
Jun 24, 2020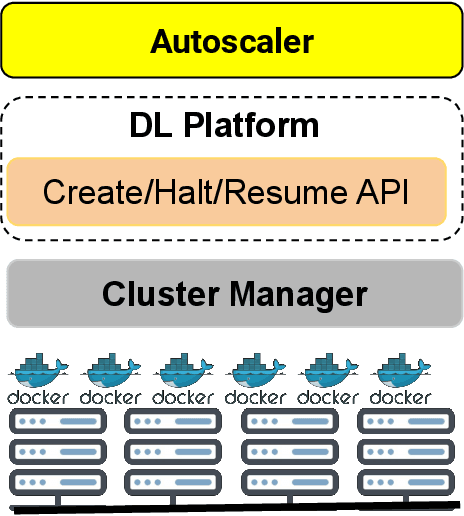
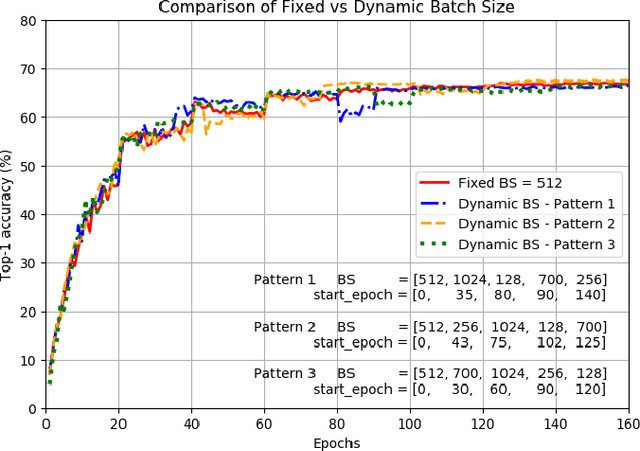
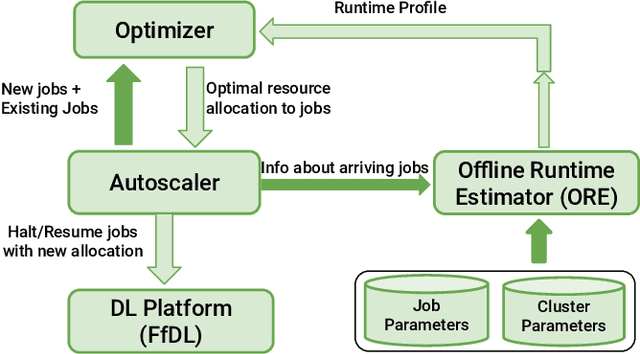

The increased use of deep learning (DL) in academia, government and industry has, in turn, led to the popularity of on-premise and cloud-hosted deep learning platforms, whose goals are to enable organizations utilize expensive resources effectively, and to share said resources among multiple teams in a fair and effective manner. In this paper, we examine the elastic scaling of Deep Learning (DL) jobs over large-scale training platforms and propose a novel resource allocation strategy for DL training jobs, resulting in improved job run time performance as well as increased cluster utilization. We begin by analyzing DL workloads and exploit the fact that DL jobs can be run with a range of batch sizes without affecting their final accuracy. We formulate an optimization problem that explores a dynamic batch size allocation to individual DL jobs based on their scaling efficiency, when running on multiple nodes. We design a fast dynamic programming based optimizer to solve this problem in real-time to determine jobs that can be scaled up/down, and use this optimizer in an autoscaler to dynamically change the allocated resources and batch sizes of individual DL jobs. We demonstrate empirically that our elastic scaling algorithm can complete up to $\approx 2 \times$ as many jobs as compared to a strong baseline algorithm that also scales the number of GPUs but does not change the batch size. We also demonstrate that the average completion time with our algorithm is up to $\approx 10 \times$ faster than that of the baseline.