 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFfDL : A Flexible Multi-tenant Deep Learning Platform
Sep 14, 2019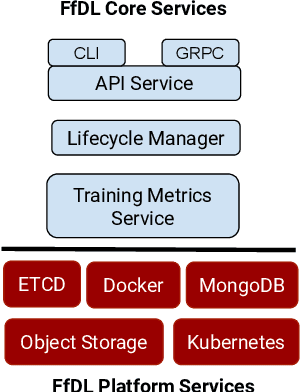

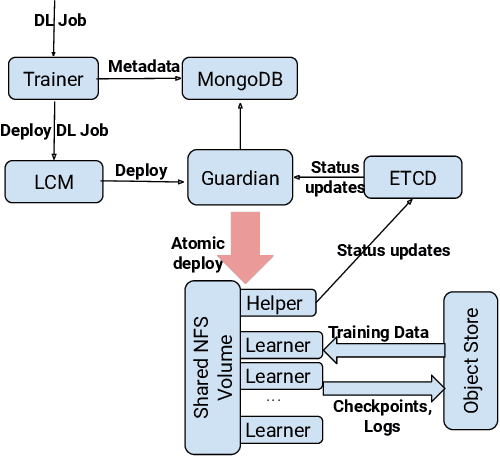
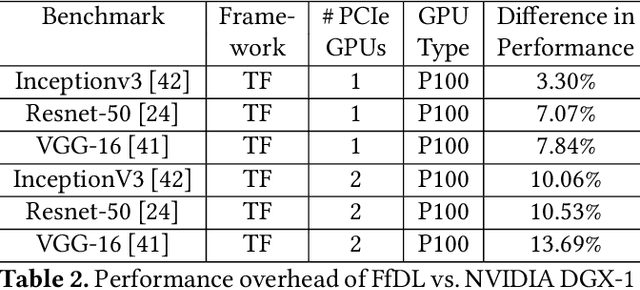
Deep learning (DL) is becoming increasingly popular in several application domains and has made several new application features involving computer vision, speech recognition and synthesis, self-driving automobiles, drug design, etc. feasible and accurate. As a result, large scale on-premise and cloud-hosted deep learning platforms have become essential infrastructure in many organizations. These systems accept, schedule, manage and execute DL training jobs at scale. This paper describes the design, implementation and our experiences with FfDL, a DL platform used at IBM. We describe how our design balances dependability with scalability, elasticity, flexibility and efficiency. We examine FfDL qualitatively through a retrospective look at the lessons learned from building, operating, and supporting FfDL; and quantitatively through a detailed empirical evaluation of FfDL, including the overheads introduced by the platform for various deep learning models, the load and performance observed in a real case study using FfDL within our organization, the frequency of various faults observed including unanticipated faults, and experiments demonstrating the benefits of various scheduling policies. FfDL has been open-sourced.