 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
DiSTRICT: Dialogue State Tracking with Retriever Driven In-Context Tuning
Dec 06, 2022



Dialogue State Tracking (DST), a key component of task-oriented conversation systems, represents user intentions by determining the values of pre-defined slots in an ongoing dialogue. Existing approaches use hand-crafted templates and additional slot information to fine-tune and prompt large pre-trained language models and elicit slot values from the dialogue context. Significant manual effort and domain knowledge is required to design effective prompts, limiting the generalizability of these approaches to new domains and tasks. In this work, we propose DiSTRICT, a generalizable in-context tuning approach for DST that retrieves highly relevant training examples for a given dialogue to fine-tune the model without any hand-crafted templates. Experiments with the MultiWOZ benchmark datasets show that DiSTRICT outperforms existing approaches in various zero-shot and few-shot settings using a much smaller model, thereby providing an important advantage for real-world deployments that often have limited resource availability.
A No-Code Low-Code Paradigm for Authoring Business Automations Using Natural Language
Jul 15, 2022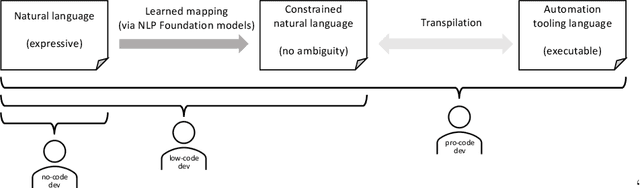
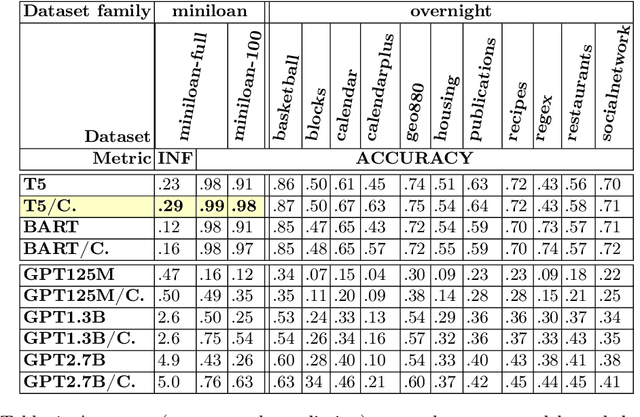

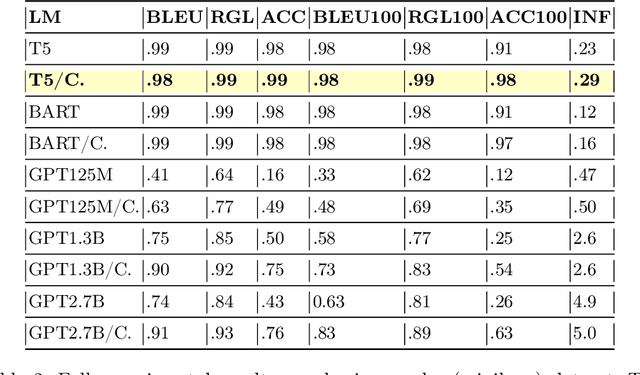
Most business process automation is still developed using traditional automation technologies such as workflow engines. These systems provide domain specific languages that require both business knowledge and programming skills to effectively use. As such, business users often lack adequate programming skills to fully leverage these code oriented environments. We propose a paradigm for the construction of business automations using natural language. The approach applies a large language model to translate business rules and automations described in natural language, into a domain specific language interpretable by a business rule engine. We compare the performance of various language model configurations, across various target domains, and explore the use of constrained decoding to ensure syntactically correct generation of output.
Towards Automating the AI Operations Lifecycle
Mar 28, 2020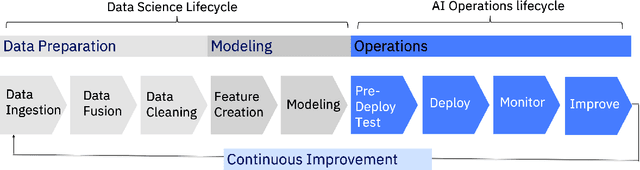
Today's AI deployments often require significant human involvement and skill in the operational stages of the model lifecycle, including pre-release testing, monitoring, problem diagnosis and model improvements. We present a set of enabling technologies that can be used to increase the level of automation in AI operations, thus lowering the human effort required. Since a common source of human involvement is the need to assess the performance of deployed models, we focus on technologies for performance prediction and KPI analysis and show how they can be used to improve automation in the key stages of a typical AI operations pipeline.
One Size Does Not Fit All: Quantifying and Exposing the Accuracy-Latency Trade-off in Machine Learning Cloud Service APIs via Tolerance Tiers
Jun 26, 2019
Today's cloud service architectures follow a "one size fits all" deployment strategy where the same service version instantiation is provided to the end users. However, consumers are broad and different applications have different accuracy and responsiveness requirements, which as we demonstrate renders the "one size fits all" approach inefficient in practice. We use a production-grade speech recognition engine, which serves several thousands of users, and an open source computer vision based system, to explain our point. To overcome the limitations of the "one size fits all" approach, we recommend Tolerance Tiers where each MLaaS tier exposes an accuracy/responsiveness characteristic, and consumers can programmatically select a tier. We evaluate our proposal on the CPU-based automatic speech recognition (ASR) engine and cutting-edge neural networks for image classification deployed on both CPUs and GPUs. The results show that our proposed approach provides an MLaaS cloud service architecture that can be tuned by the end API user or consumer to outperform the conventional "one size fits all" approach.
Exploring the Hyperparameter Landscape of Adversarial Robustness
May 09, 2019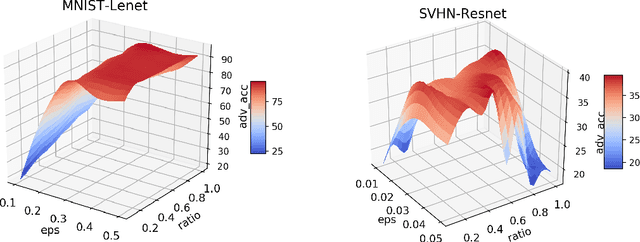
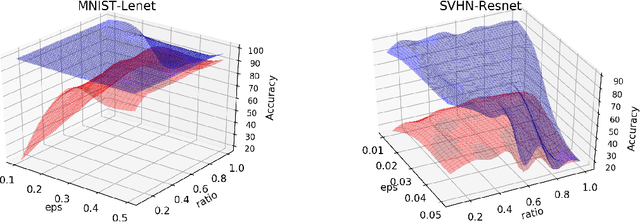
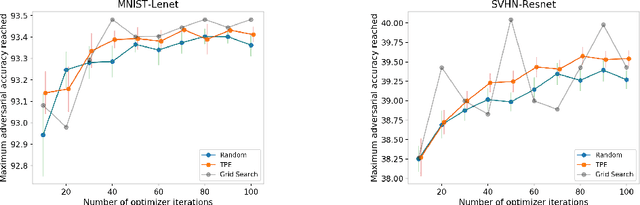
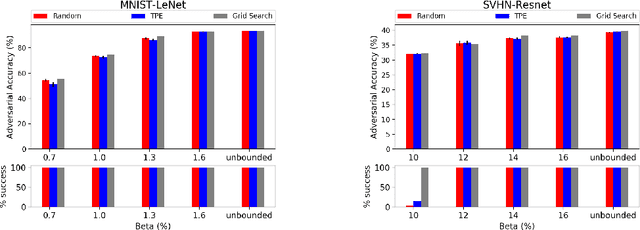
Adversarial training shows promise as an approach for training models that are robust towards adversarial perturbation. In this paper, we explore some of the practical challenges of adversarial training. We present a sensitivity analysis that illustrates that the effectiveness of adversarial training hinges on the settings of a few salient hyperparameters. We show that the robustness surface that emerges across these salient parameters can be surprisingly complex and that therefore no effective one-size-fits-all parameter settings exist. We then demonstrate that we can use the same salient hyperparameters as tuning knob to navigate the tension that can arise between robustness and accuracy. Based on these findings, we present a practical approach that leverages hyperparameter optimization techniques for tuning adversarial training to maximize robustness while keeping the loss in accuracy within a defined budget.