 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of Prediction Intervals Using Uncertainty Characteristics Curves
Oct 04, 2023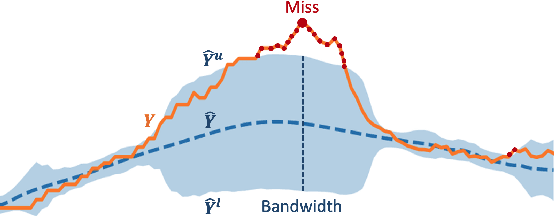
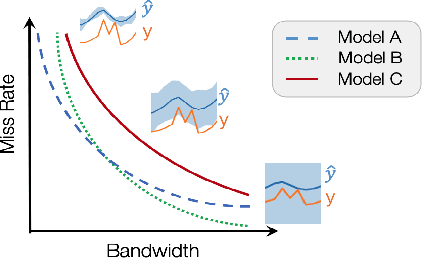
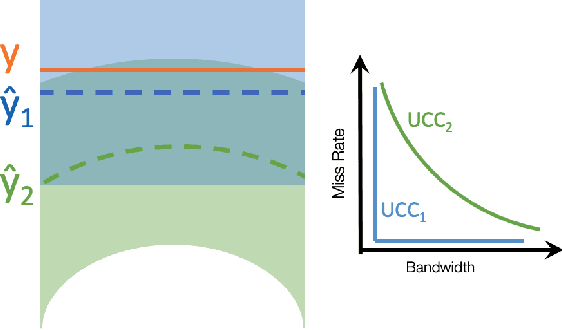
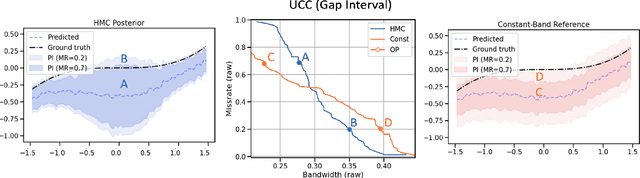
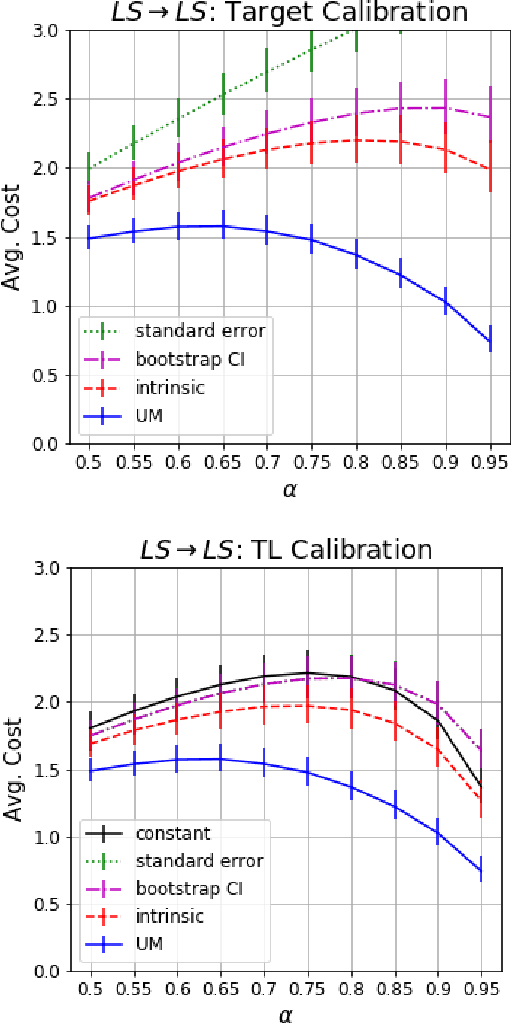
Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to an ad-hoc operating point, making evaluation and comparison across different studies relatively difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a null reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper defines the Uncertainty Characteristics Curve and demonstrates its utility in selected scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
Uncertainty Characteristics Curves: A Systematic Assessment of Prediction Intervals
Jun 01, 2021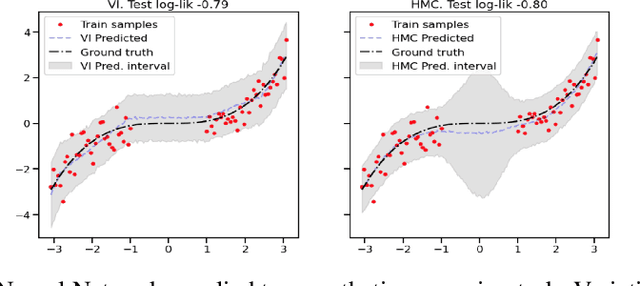


Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to a specific operating point, making evaluation and comparison across different studies difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a simple reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper describes the corresponding algorithm, provides a theoretical analysis, and demonstrates its utility in multiple scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
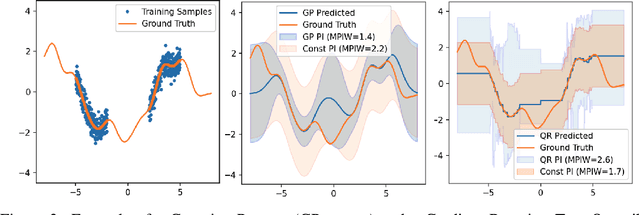
Learning Prediction Intervals for Model Performance
Dec 15, 2020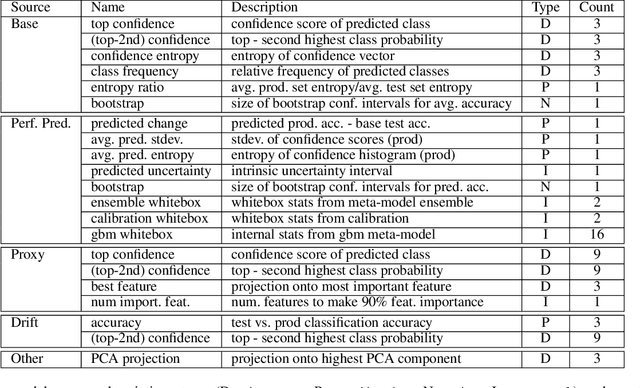
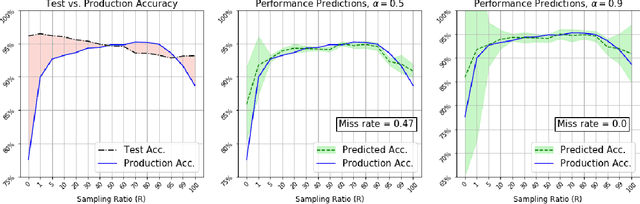

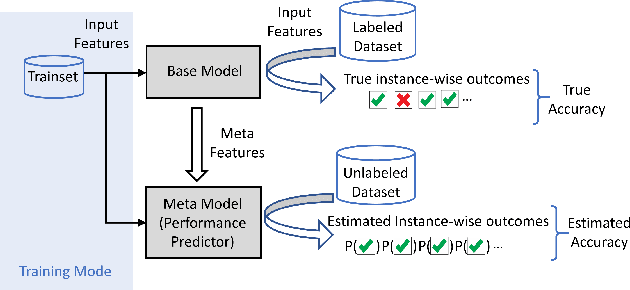
Understanding model performance on unlabeled data is a fundamental challenge of developing, deploying, and maintaining AI systems. Model performance is typically evaluated using test sets or periodic manual quality assessments, both of which require laborious manual data labeling. Automated performance prediction techniques aim to mitigate this burden, but potential inaccuracy and a lack of trust in their predictions has prevented their widespread adoption. We address this core problem of performance prediction uncertainty with a method to compute prediction intervals for model performance. Our methodology uses transfer learning to train an uncertainty model to estimate the uncertainty of model performance predictions. We evaluate our approach across a wide range of drift conditions and show substantial improvement over competitive baselines. We believe this result makes prediction intervals, and performance prediction in general, significantly more practical for real-world use.
Not Your Grandfathers Test Set: Reducing Labeling Effort for Testing
Jul 10, 2020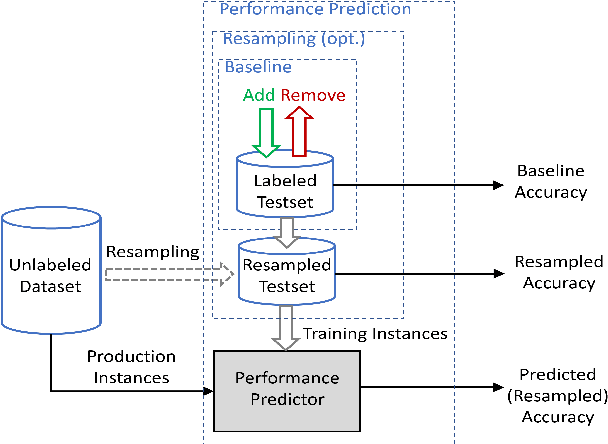


Building and maintaining high-quality test sets remains a laborious and expensive task. As a result, test sets in the real world are often not properly kept up to date and drift from the production traffic they are supposed to represent. The frequency and severity of this drift raises serious concerns over the value of manually labeled test sets in the QA process. This paper proposes a simple but effective technique that drastically reduces the effort needed to construct and maintain a high-quality test set (reducing labeling effort by 80-100% across a range of practical scenarios). This result encourages a fundamental rethinking of the testing process by both practitioners, who can use these techniques immediately to improve their testing, and researchers who can help address many of the open questions raised by this new approach.
Uncertainty Prediction for Deep Sequential Regression Using Meta Models
Jul 02, 2020

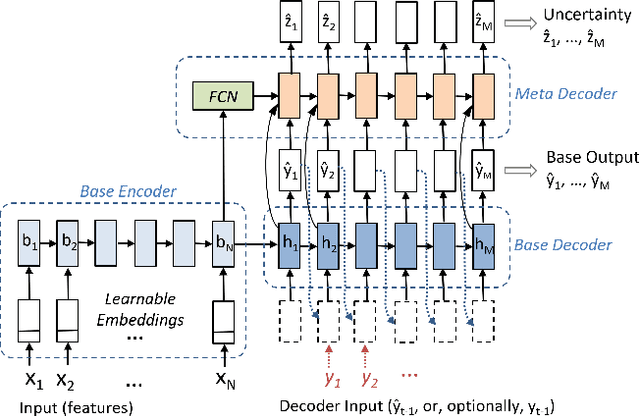
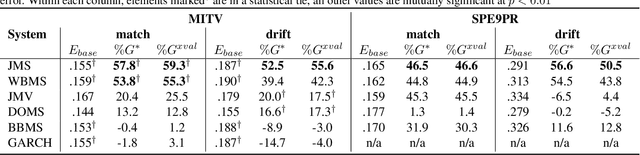
Generating high quality uncertainty estimates for sequential regression, particularly deep recurrent networks, remains a challenging and open problem. Existing approaches often make restrictive assumptions (such as stationarity) yet still perform poorly in practice, particularly in presence of real world non-stationary signals and drift. This paper describes a flexible method that can generate symmetric and asymmetric uncertainty estimates, makes no assumptions about stationarity, and outperforms competitive baselines on both drift and non drift scenarios. This work helps make sequential regression more effective and practical for use in real-world applications, and is a powerful new addition to the modeling toolbox for sequential uncertainty quantification in general.
Towards Automating the AI Operations Lifecycle
Mar 28, 2020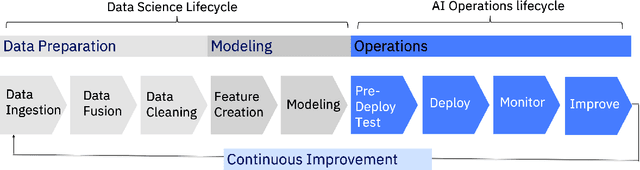
Today's AI deployments often require significant human involvement and skill in the operational stages of the model lifecycle, including pre-release testing, monitoring, problem diagnosis and model improvements. We present a set of enabling technologies that can be used to increase the level of automation in AI operations, thus lowering the human effort required. Since a common source of human involvement is the need to assess the performance of deployed models, we focus on technologies for performance prediction and KPI analysis and show how they can be used to improve automation in the key stages of a typical AI operations pipeline.