 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Lifecycle Toolkit (ALTK): Reusable Middleware Components for Robust AI Agents
Mar 16, 2026As AI agents move from demos into enterprise deployments, their failure modes become consequential: a misinterpreted tool argument can corrupt production data, a silent reasoning error can go undetected until damage is done, and outputs that violate organizational policy can create legal or compliance risk. Yet, most agent frameworks leave builders to handle these failure modes ad hoc, resulting in brittle, one-off safeguards that are hard to reuse or maintain. We present the Agent Lifecycle Toolkit (ALTK), an open-source collection of modular middleware components that systematically address these gaps across the full agent lifecycle. Across the agent lifecycle, we identify opportunities to intervene and improve, namely, post-user-request, pre-LLM prompt conditioning, post-LLM output processing, pre-tool validation, post-tool result checking, and pre-response assembly. ALTK provides modular middleware that detects, repairs, and mitigates common failure modes. It offers consistent interfaces that fit naturally into existing pipelines. It is compatible with low-code and no-code tools such as the ContextForge MCP Gateway and Langflow. Finally, it significantly reduces the effort of building reliable, production-grade agents.
Invocable APIs derived from NL2SQL datasets for LLM Tool-Calling Evaluation
Jun 12, 2025Large language models (LLMs) are routinely deployed as agentic systems, with access to tools that interact with live environments to accomplish tasks. In enterprise deployments these systems need to interact with API collections that can be extremely large and complex, often backed by databases. In order to create datasets with such characteristics, we explore how existing NL2SQL (Natural Language to SQL query) datasets can be used to automatically create NL2API datasets. Specifically, this work describes a novel data generation pipeline that exploits the syntax of SQL queries to construct a functionally equivalent sequence of API calls. We apply this pipeline to one of the largest NL2SQL datasets, BIRD-SQL to create a collection of over 2500 APIs that can be served as invocable tools or REST-endpoints. We pair natural language queries from BIRD-SQL to ground-truth API sequences based on this API pool. We use this collection to study the performance of 10 public LLMs and find that all models struggle to determine the right set of tools (consisting of tasks of intent detection, sequencing with nested function calls, and slot-filling). We find that models have extremely low task completion rates (7-47 percent - depending on the dataset) which marginally improves to 50 percent when models are employed as ReACT agents that interact with the live API environment. The best task completion rates are far below what may be required for effective general-use tool-calling agents, suggesting substantial scope for improvement in current state-of-the-art tool-calling LLMs. We also conduct detailed ablation studies, such as assessing the impact of the number of tools available as well as the impact of tool and slot-name obfuscation. We compare the performance of models on the original SQL generation tasks and find that current models are sometimes able to exploit SQL better than APIs.
Learning Prediction Intervals for Model Performance
Dec 15, 2020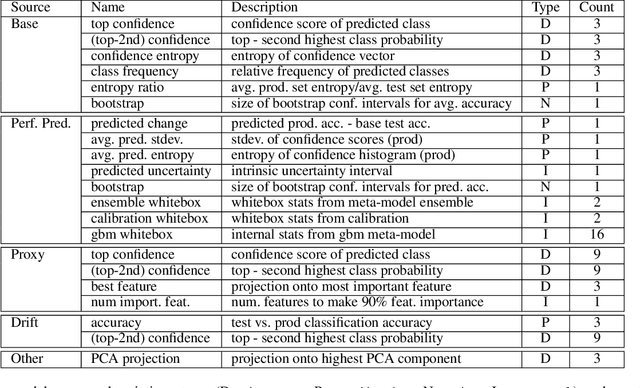
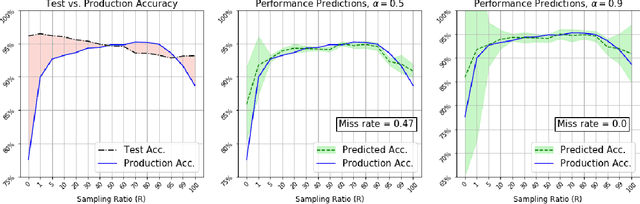

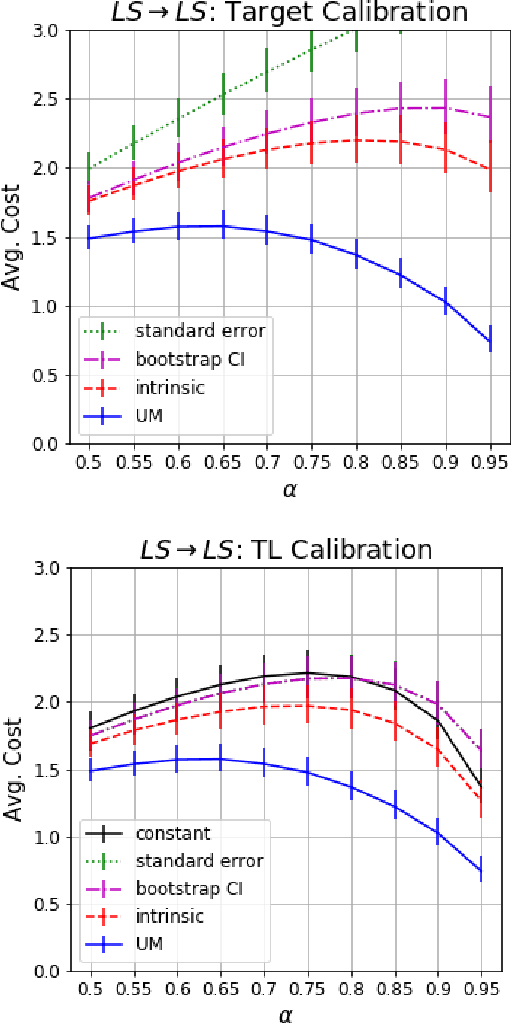
Understanding model performance on unlabeled data is a fundamental challenge of developing, deploying, and maintaining AI systems. Model performance is typically evaluated using test sets or periodic manual quality assessments, both of which require laborious manual data labeling. Automated performance prediction techniques aim to mitigate this burden, but potential inaccuracy and a lack of trust in their predictions has prevented their widespread adoption. We address this core problem of performance prediction uncertainty with a method to compute prediction intervals for model performance. Our methodology uses transfer learning to train an uncertainty model to estimate the uncertainty of model performance predictions. We evaluate our approach across a wide range of drift conditions and show substantial improvement over competitive baselines. We believe this result makes prediction intervals, and performance prediction in general, significantly more practical for real-world use.
Not Your Grandfathers Test Set: Reducing Labeling Effort for Testing
Jul 10, 2020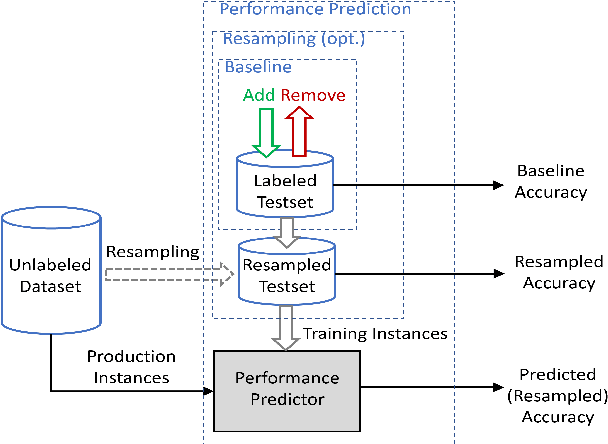

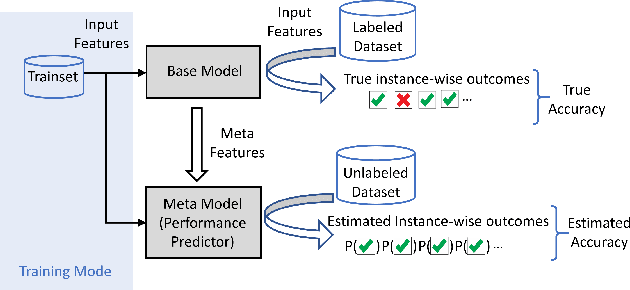

Building and maintaining high-quality test sets remains a laborious and expensive task. As a result, test sets in the real world are often not properly kept up to date and drift from the production traffic they are supposed to represent. The frequency and severity of this drift raises serious concerns over the value of manually labeled test sets in the QA process. This paper proposes a simple but effective technique that drastically reduces the effort needed to construct and maintain a high-quality test set (reducing labeling effort by 80-100% across a range of practical scenarios). This result encourages a fundamental rethinking of the testing process by both practitioners, who can use these techniques immediately to improve their testing, and researchers who can help address many of the open questions raised by this new approach.
Towards Automating the AI Operations Lifecycle
Mar 28, 2020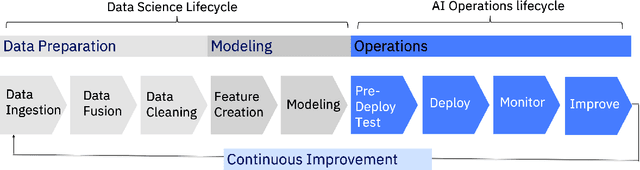
Today's AI deployments often require significant human involvement and skill in the operational stages of the model lifecycle, including pre-release testing, monitoring, problem diagnosis and model improvements. We present a set of enabling technologies that can be used to increase the level of automation in AI operations, thus lowering the human effort required. Since a common source of human involvement is the need to assess the performance of deployed models, we focus on technologies for performance prediction and KPI analysis and show how they can be used to improve automation in the key stages of a typical AI operations pipeline.
Exploring the Hyperparameter Landscape of Adversarial Robustness
May 09, 2019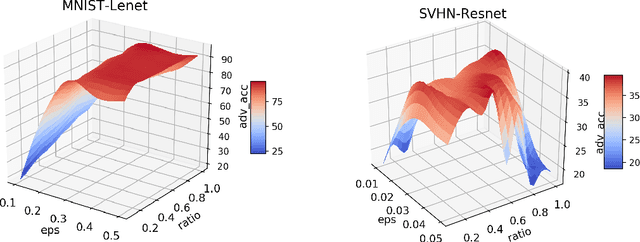
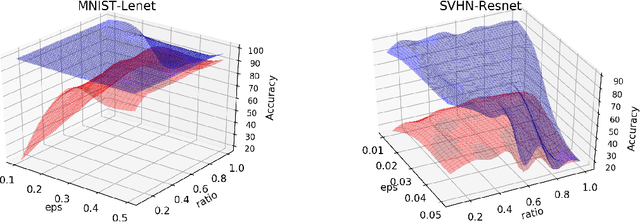
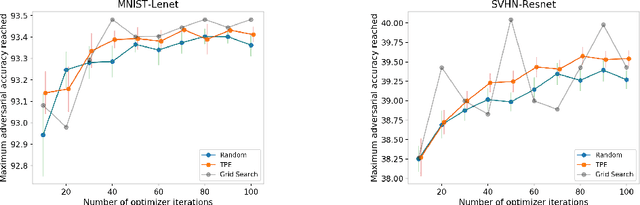
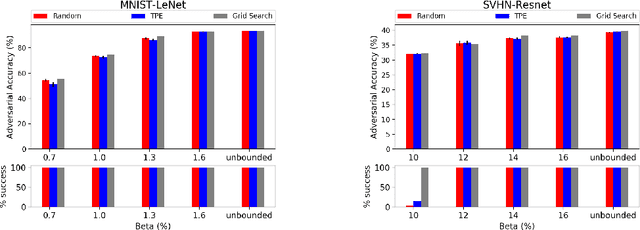
Adversarial training shows promise as an approach for training models that are robust towards adversarial perturbation. In this paper, we explore some of the practical challenges of adversarial training. We present a sensitivity analysis that illustrates that the effectiveness of adversarial training hinges on the settings of a few salient hyperparameters. We show that the robustness surface that emerges across these salient parameters can be surprisingly complex and that therefore no effective one-size-fits-all parameter settings exist. We then demonstrate that we can use the same salient hyperparameters as tuning knob to navigate the tension that can arise between robustness and accuracy. Based on these findings, we present a practical approach that leverages hyperparameter optimization techniques for tuning adversarial training to maximize robustness while keeping the loss in accuracy within a defined budget.