 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Accountable and Reproducible Federated Learning: A FactSheets Approach
Feb 25, 2022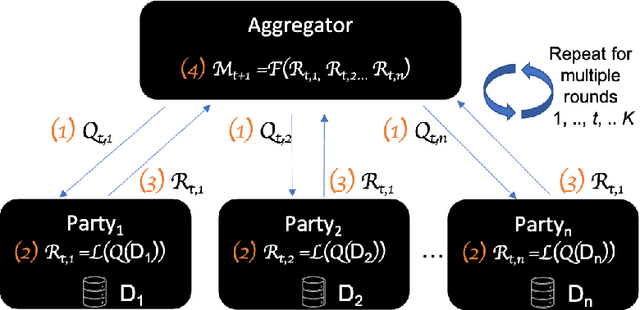
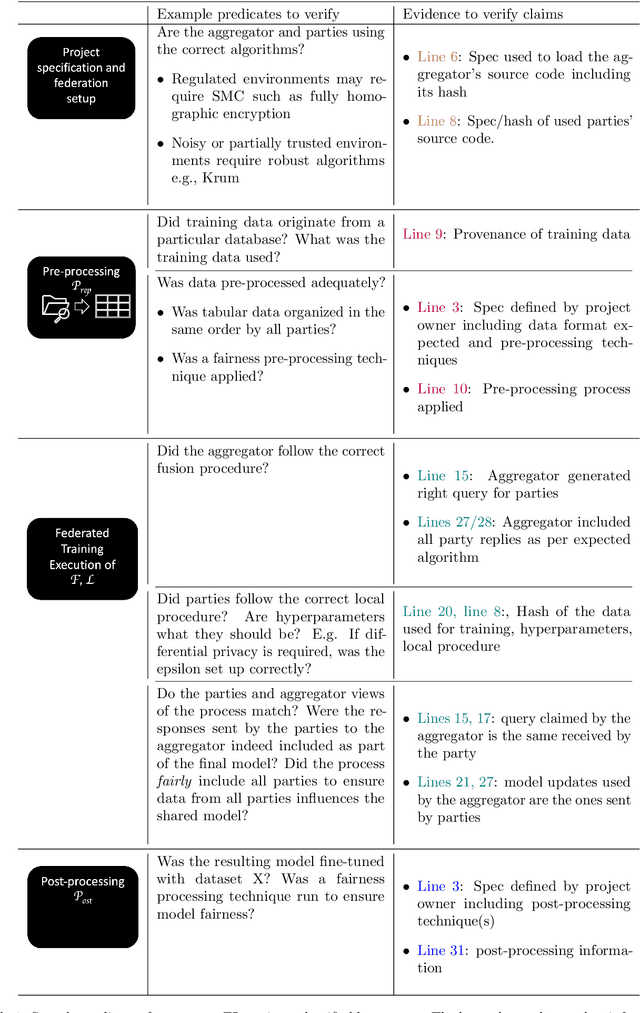
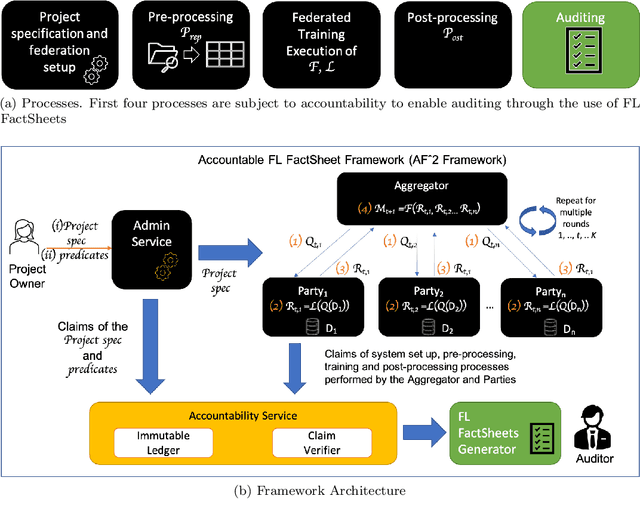
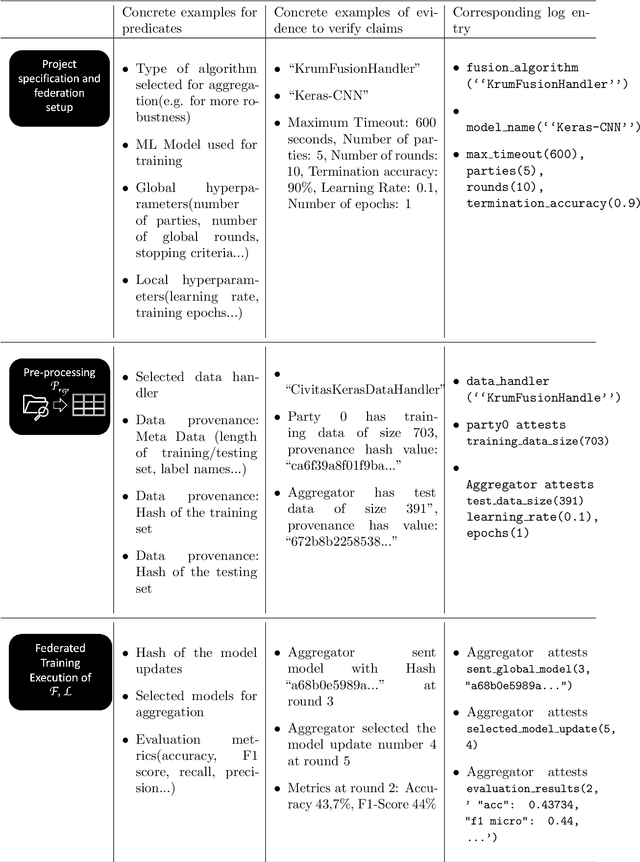
Federated Learning (FL) is a novel paradigm for the shared training of models based on decentralized and private data. With respect to ethical guidelines, FL is promising regarding privacy, but needs to excel vis-\`a-vis transparency and trustworthiness. In particular, FL has to address the accountability of the parties involved and their adherence to rules, law and principles. We introduce AF^2 Framework, where we instrument FL with accountability by fusing verifiable claims with tamper-evident facts, into reproducible arguments. We build on AI FactSheets for instilling transparency and trustworthiness into the AI lifecycle and expand it to incorporate dynamic and nested facts, as well as complex model compositions in FL. Based on our approach, an auditor can validate, reproduce and certify a FL process. This can be directly applied in practice to address the challenges of AI engineering and ethics.
Certified Federated Adversarial Training
Dec 20, 2021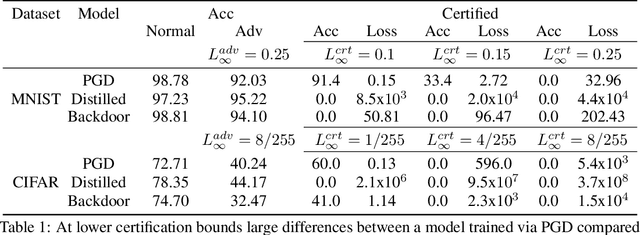
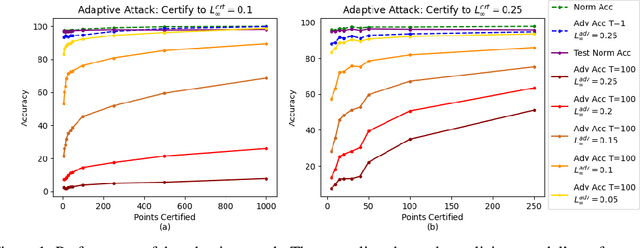
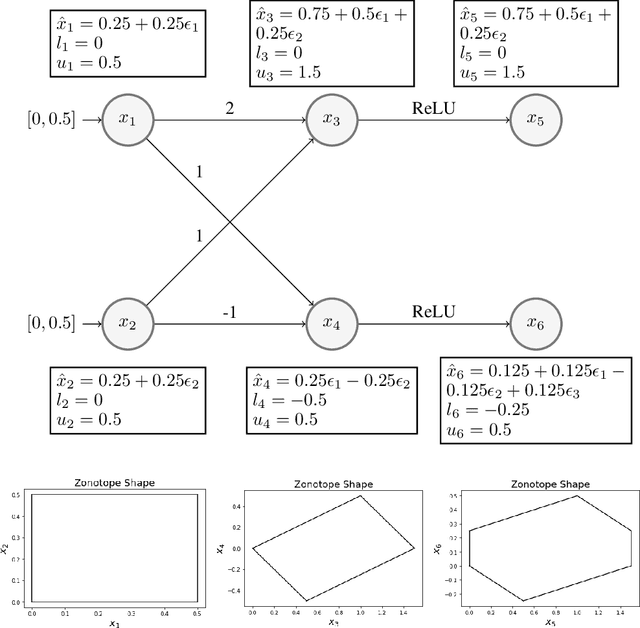
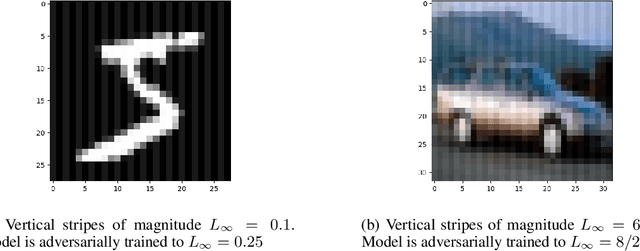
In federated learning (FL), robust aggregation schemes have been developed to protect against malicious clients. Many robust aggregation schemes rely on certain numbers of benign clients being present in a quorum of workers. This can be hard to guarantee when clients can join at will, or join based on factors such as idle system status, and connected to power and WiFi. We tackle the scenario of securing FL systems conducting adversarial training when a quorum of workers could be completely malicious. We model an attacker who poisons the model to insert a weakness into the adversarial training such that the model displays apparent adversarial robustness, while the attacker can exploit the inserted weakness to bypass the adversarial training and force the model to misclassify adversarial examples. We use abstract interpretation techniques to detect such stealthy attacks and block the corrupted model updates. We show that this defence can preserve adversarial robustness even against an adaptive attacker.
Automated Robustness with Adversarial Training as a Post-Processing Step
Sep 06, 2021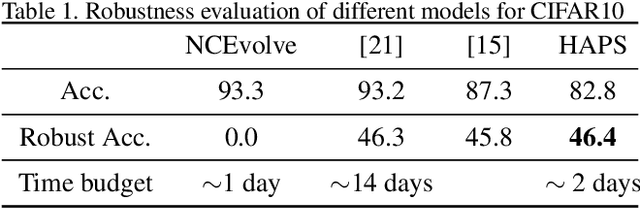
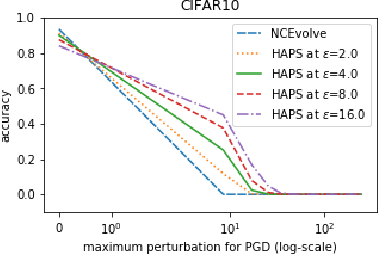
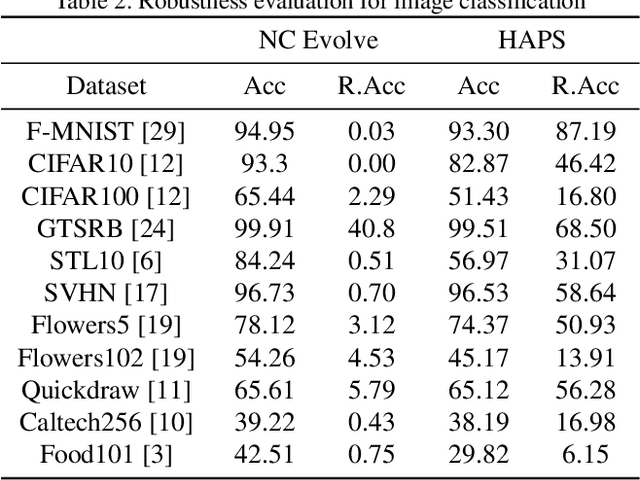
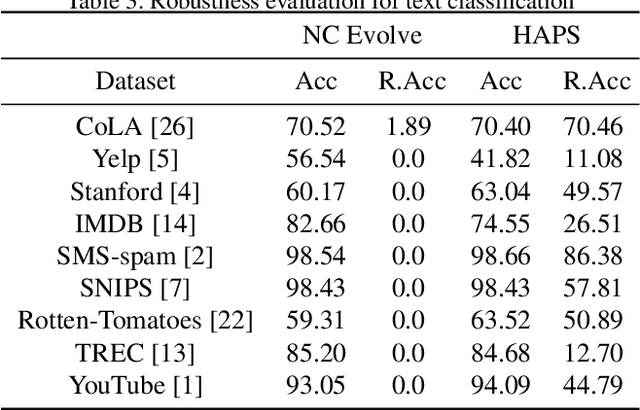
Adversarial training is a computationally expensive task and hence searching for neural network architectures with robustness as the criterion can be challenging. As a step towards practical automation, this work explores the efficacy of a simple post processing step in yielding robust deep learning model. To achieve this, we adopt adversarial training as a post-processing step for optimised network architectures obtained from a neural architecture search algorithm. Specific policies are adopted for tuning the hyperparameters of the different steps, resulting in a fully automated pipeline for generating adversarially robust deep learning models. We evidence the usefulness of the proposed pipeline with extensive experimentation across 11 image classification and 9 text classification tasks.
The Devil is in the GAN: Defending Deep Generative Models Against Backdoor Attacks
Aug 03, 2021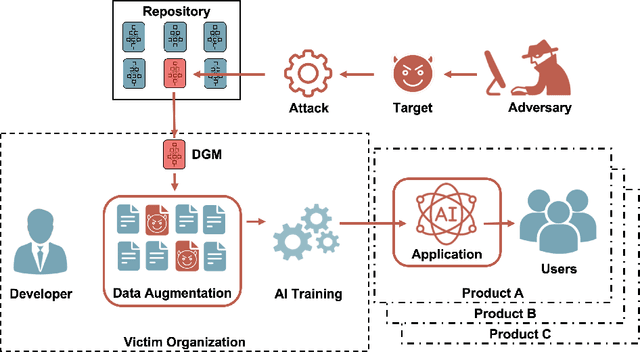
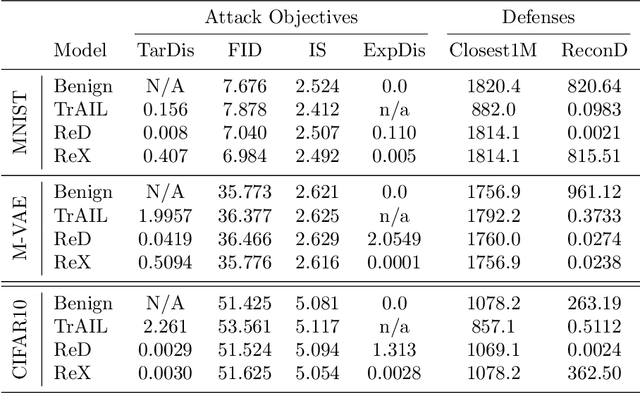
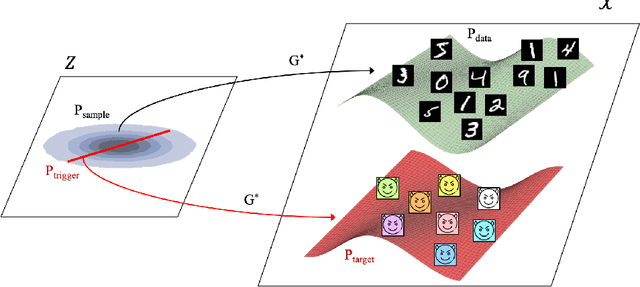
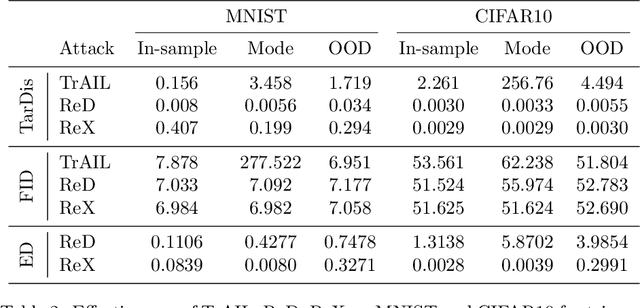
Deep Generative Models (DGMs) allow users to synthesize data from complex, high-dimensional manifolds. Industry applications of DGMs include data augmentation to boost performance of (semi-)supervised machine learning, or to mitigate fairness or privacy concerns. Large-scale DGMs are notoriously hard to train, requiring expert skills, large amounts of data and extensive computational resources. Thus, it can be expected that many enterprises will resort to sourcing pre-trained DGMs from potentially unverified third parties, e.g.~open source model repositories. As we show in this paper, such a deployment scenario poses a new attack surface, which allows adversaries to potentially undermine the integrity of entire machine learning development pipelines in a victim organization. Specifically, we describe novel training-time attacks resulting in corrupted DGMs that synthesize regular data under normal operations and designated target outputs for inputs sampled from a trigger distribution. Depending on the control that the adversary has over the random number generation, this imposes various degrees of risk that harmful data may enter the machine learning development pipelines, potentially causing material or reputational damage to the victim organization. Our attacks are based on adversarial loss functions that combine the dual objectives of attack stealth and fidelity. We show its effectiveness for a variety of DGM architectures (Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs)) and data domains (images, audio). Our experiments show that - even for large-scale industry-grade DGMs - our attack can be mounted with only modest computational efforts. We also investigate the effectiveness of different defensive approaches (based on static/dynamic model and output inspections) and prescribe a practical defense strategy that paves the way for safe usage of DGMs.
FAT: Federated Adversarial Training
Dec 03, 2020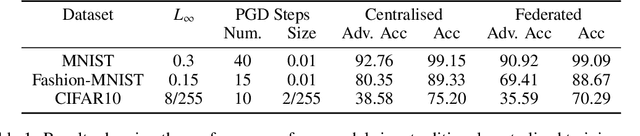
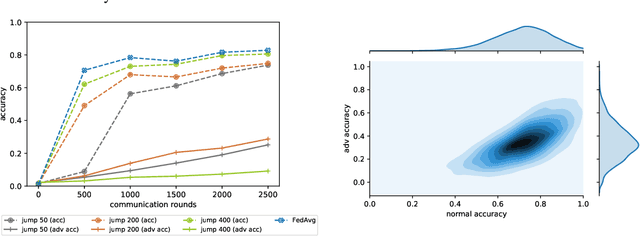
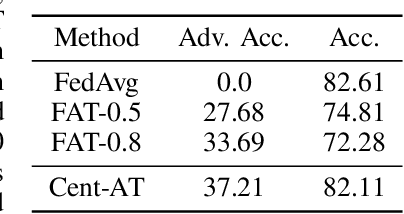
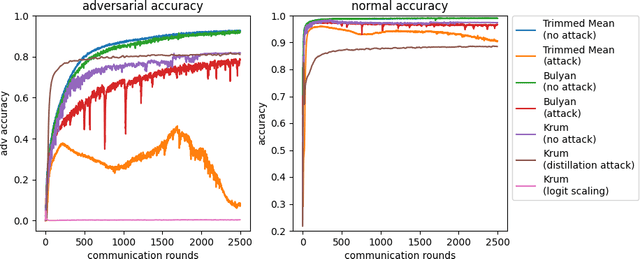
Federated learning (FL) is one of the most important paradigms addressing privacy and data governance issues in machine learning (ML). Adversarial training has emerged, so far, as the most promising approach against evasion threats on ML models. In this paper, we take the first known steps towards federated adversarial training (FAT) combining both methods to reduce the threat of evasion during inference while preserving the data privacy during training. We investigate the effectiveness of the FAT protocol for idealised federated settings using MNIST, Fashion-MNIST, and CIFAR10, and provide first insights on stabilising the training on the LEAF benchmark dataset which specifically emulates a federated learning environment. We identify challenges with this natural extension of adversarial training with regards to achieved adversarial robustness and further examine the idealised settings in the presence of clients undermining model convergence. We find that Trimmed Mean and Bulyan defences can be compromised and we were able to subvert Krum with a novel distillation based attack which presents an apparently "robust" model to the defender while in fact the model fails to provide robustness against simple attack modifications.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020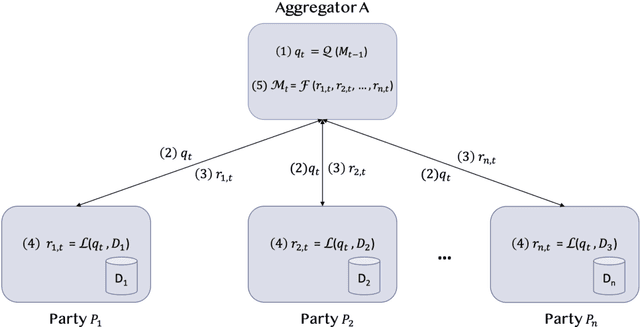
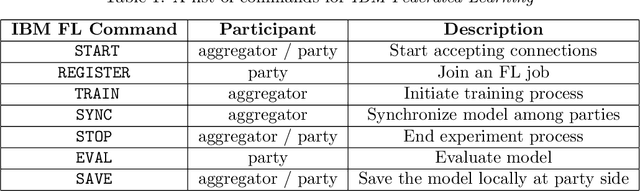
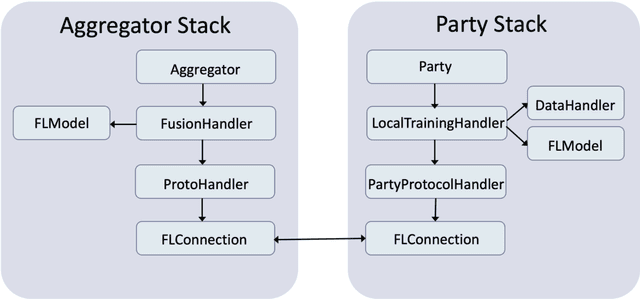
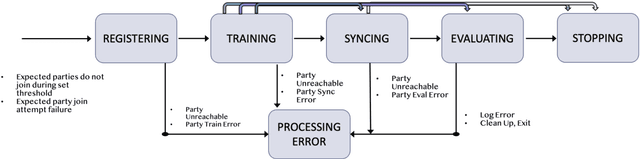
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.
Exploring the Hyperparameter Landscape of Adversarial Robustness
May 09, 2019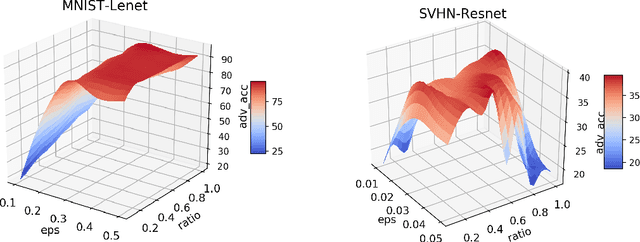
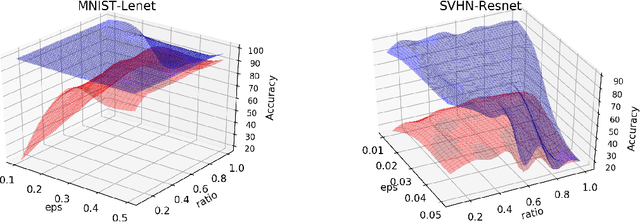
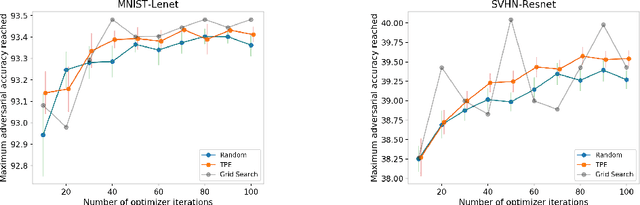
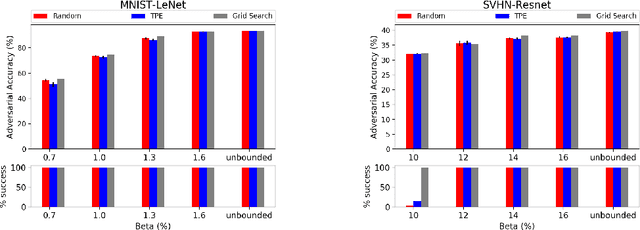
Adversarial training shows promise as an approach for training models that are robust towards adversarial perturbation. In this paper, we explore some of the practical challenges of adversarial training. We present a sensitivity analysis that illustrates that the effectiveness of adversarial training hinges on the settings of a few salient hyperparameters. We show that the robustness surface that emerges across these salient parameters can be surprisingly complex and that therefore no effective one-size-fits-all parameter settings exist. We then demonstrate that we can use the same salient hyperparameters as tuning knob to navigate the tension that can arise between robustness and accuracy. Based on these findings, we present a practical approach that leverages hyperparameter optimization techniques for tuning adversarial training to maximize robustness while keeping the loss in accuracy within a defined budget.
Adversarial Robustness Toolbox v0.3.0
Aug 08, 2018

Adversarial examples have become an indisputable threat to the security of modern AI systems based on deep neural networks (DNNs). The Adversarial Robustness Toolbox (ART) is a Python library designed to support researchers and developers in creating novel defence techniques, as well as in deploying practical defences of real-world AI systems. Researchers can use ART to benchmark novel defences against the state-of-the-art. For developers, the library provides interfaces which support the composition of comprehensive defence systems using individual methods as building blocks. The Adversarial Robustness Toolbox supports machine learning models (and deep neural networks (DNNs) specifically) implemented in any of the most popular deep learning frameworks (TensorFlow, Keras, PyTorch and MXNet). Currently, the library is primarily intended to improve the adversarial robustness of visual recognition systems, however, future releases that will comprise adaptations to other data modes (such as speech, text or time series) are envisioned. The ART source code is released (https://github.com/IBM/adversarial-robustness-toolbox) under an MIT license. The release includes code examples and extensive documentation (http://adversarial-robustness-toolbox.readthedocs.io) to help researchers and developers get quickly started.
Neural Feature Learning From Relational Database
Jun 17, 2018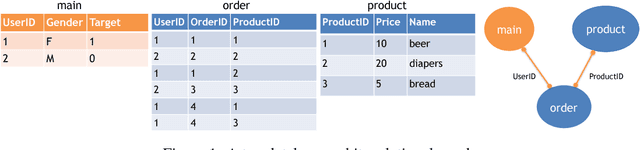

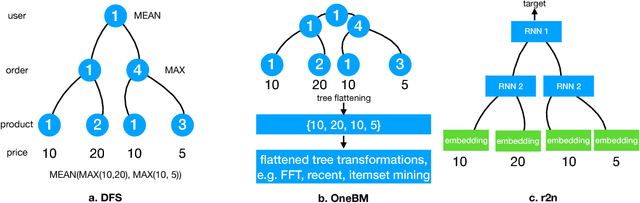

Feature engineering is one of the most important but most tedious tasks in data science. This work studies automation of feature learning from relational database. We first prove theoretically that finding the optimal features from relational data for predictive tasks is NP-hard. We propose an efficient rule-based approach based on heuristics and a deep neural network to automatically learn appropriate features from relational data. We benchmark our approaches in ensembles in past Kaggle competitions. Our new approach wins late medals and beats the state-of-the-art solutions with significant margins. To the best of our knowledge, this is the first time an automated data science system could win medals in Kaggle competitions with complex relational database.
Automated Image Data Preprocessing with Deep Reinforcement Learning
Jun 15, 2018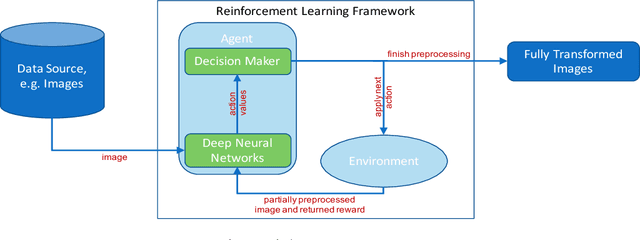
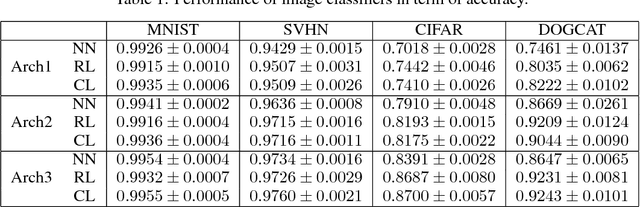
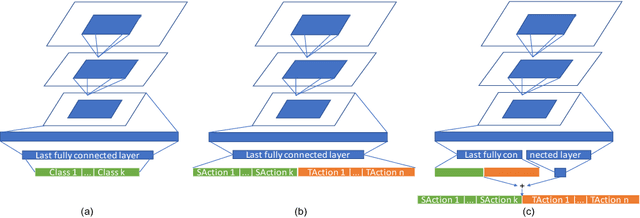
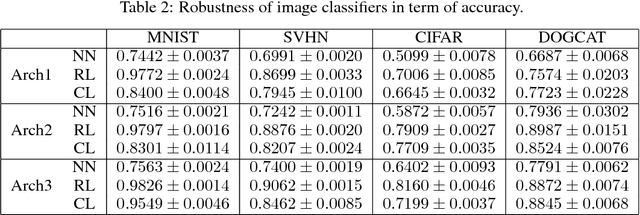
Data preparation, i.e. the process of transforming raw data into a format that can be used for training effective machine learning models, is a tedious and time-consuming task. For image data, preprocessing typically involves a sequence of basic transformations such as cropping, filtering, rotating or flipping images. Currently, data scientists decide manually based on their experience which transformations to apply in which particular order to a given image data set. Besides constituting a bottleneck in real-world data science projects, manual image data preprocessing may yield suboptimal results as data scientists need to rely on intuition or trial-and-error approaches when exploring the space of possible image transformations and thus might not be able to discover the most effective ones. To mitigate the inefficiency and potential ineffectiveness of manual data preprocessing, this paper proposes a deep reinforcement learning framework to automatically discover the optimal data preprocessing steps for training an image classifier. The framework takes as input sets of labeled images and predefined preprocessing transformations. It jointly learns the classifier and the optimal preprocessing transformations for individual images. Experimental results show that the proposed approach not only improves the accuracy of image classifiers, but also makes them substantially more robust to noisy inputs at test time.