 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealix: Model Stealing via Prompt Evolution
Jun 06, 2025Model stealing poses a significant security risk in machine learning by enabling attackers to replicate a black-box model without access to its training data, thus jeopardizing intellectual property and exposing sensitive information. Recent methods that use pre-trained diffusion models for data synthesis improve efficiency and performance but rely heavily on manually crafted prompts, limiting automation and scalability, especially for attackers with little expertise. To assess the risks posed by open-source pre-trained models, we propose a more realistic threat model that eliminates the need for prompt design skills or knowledge of class names. In this context, we introduce Stealix, the first approach to perform model stealing without predefined prompts. Stealix uses two open-source pre-trained models to infer the victim model's data distribution, and iteratively refines prompts through a genetic algorithm, progressively improving the precision and diversity of synthetic images. Our experimental results demonstrate that Stealix significantly outperforms other methods, even those with access to class names or fine-grained prompts, while operating under the same query budget. These findings highlight the scalability of our approach and suggest that the risks posed by pre-trained generative models in model stealing may be greater than previously recognized.
Medical Multimodal Model Stealing Attacks via Adversarial Domain Alignment
Feb 04, 2025Medical multimodal large language models (MLLMs) are becoming an instrumental part of healthcare systems, assisting medical personnel with decision making and results analysis. Models for radiology report generation are able to interpret medical imagery, thus reducing the workload of radiologists. As medical data is scarce and protected by privacy regulations, medical MLLMs represent valuable intellectual property. However, these assets are potentially vulnerable to model stealing, where attackers aim to replicate their functionality via black-box access. So far, model stealing for the medical domain has focused on classification; however, existing attacks are not effective against MLLMs. In this paper, we introduce Adversarial Domain Alignment (ADA-STEAL), the first stealing attack against medical MLLMs. ADA-STEAL relies on natural images, which are public and widely available, as opposed to their medical counterparts. We show that data augmentation with adversarial noise is sufficient to overcome the data distribution gap between natural images and the domain-specific distribution of the victim MLLM. Experiments on the IU X-RAY and MIMIC-CXR radiology datasets demonstrate that Adversarial Domain Alignment enables attackers to steal the medical MLLM without any access to medical data.
Stealthy Imitation: Reward-guided Environment-free Policy Stealing
May 11, 2024Deep reinforcement learning policies, which are integral to modern control systems, represent valuable intellectual property. The development of these policies demands considerable resources, such as domain expertise, simulation fidelity, and real-world validation. These policies are potentially vulnerable to model stealing attacks, which aim to replicate their functionality using only black-box access. In this paper, we propose Stealthy Imitation, the first attack designed to steal policies without access to the environment or knowledge of the input range. This setup has not been considered by previous model stealing methods. Lacking access to the victim's input states distribution, Stealthy Imitation fits a reward model that allows to approximate it. We show that the victim policy is harder to imitate when the distribution of the attack queries matches that of the victim. We evaluate our approach across diverse, high-dimensional control tasks and consistently outperform prior data-free approaches adapted for policy stealing. Lastly, we propose a countermeasure that significantly diminishes the effectiveness of the attack.
Revisiting Neural Program Smoothing for Fuzzing
Sep 28, 2023Testing with randomly generated inputs (fuzzing) has gained significant traction due to its capacity to expose program vulnerabilities automatically. Fuzz testing campaigns generate large amounts of data, making them ideal for the application of machine learning (ML). Neural program smoothing (NPS), a specific family of ML-guided fuzzers, aims to use a neural network as a smooth approximation of the program target for new test case generation. In this paper, we conduct the most extensive evaluation of NPS fuzzers against standard gray-box fuzzers (>11 CPU years and >5.5 GPU years), and make the following contributions: (1) We find that the original performance claims for NPS fuzzers do not hold; a gap we relate to fundamental, implementation, and experimental limitations of prior works. (2) We contribute the first in-depth analysis of the contribution of machine learning and gradient-based mutations in NPS. (3) We implement Neuzz++, which shows that addressing the practical limitations of NPS fuzzers improves performance, but that standard gray-box fuzzers almost always surpass NPS-based fuzzers. (4) As a consequence, we propose new guidelines targeted at benchmarking fuzzing based on machine learning, and present MLFuzz, a platform with GPU access for easy and reproducible evaluation of ML-based fuzzers. Neuzz++, MLFuzz, and all our data are public.
Adversarial Robustness Toolbox v0.3.0
Aug 08, 2018

Adversarial examples have become an indisputable threat to the security of modern AI systems based on deep neural networks (DNNs). The Adversarial Robustness Toolbox (ART) is a Python library designed to support researchers and developers in creating novel defence techniques, as well as in deploying practical defences of real-world AI systems. Researchers can use ART to benchmark novel defences against the state-of-the-art. For developers, the library provides interfaces which support the composition of comprehensive defence systems using individual methods as building blocks. The Adversarial Robustness Toolbox supports machine learning models (and deep neural networks (DNNs) specifically) implemented in any of the most popular deep learning frameworks (TensorFlow, Keras, PyTorch and MXNet). Currently, the library is primarily intended to improve the adversarial robustness of visual recognition systems, however, future releases that will comprise adaptations to other data modes (such as speech, text or time series) are envisioned. The ART source code is released (https://github.com/IBM/adversarial-robustness-toolbox) under an MIT license. The release includes code examples and extensive documentation (http://adversarial-robustness-toolbox.readthedocs.io) to help researchers and developers get quickly started.
Adversarial Phenomenon in the Eyes of Bayesian Deep Learning
Nov 22, 2017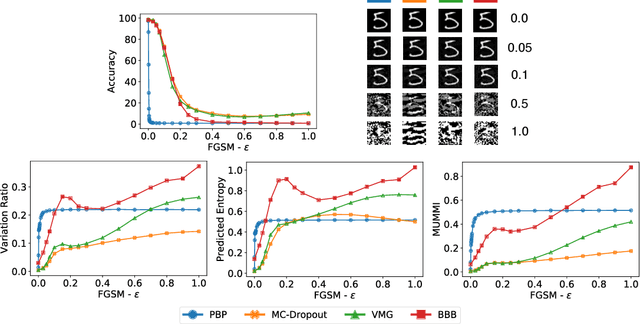
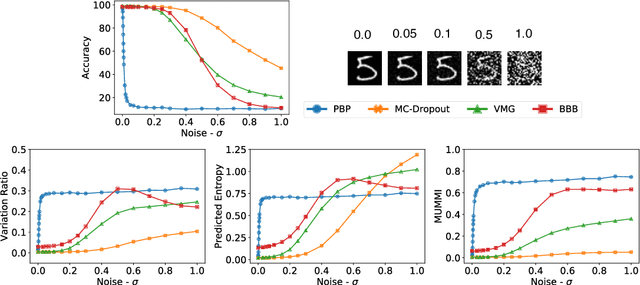
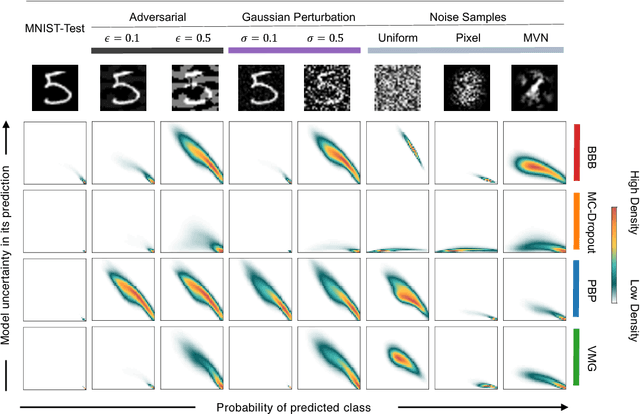
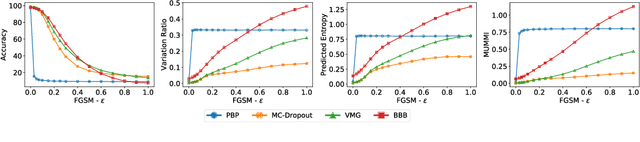
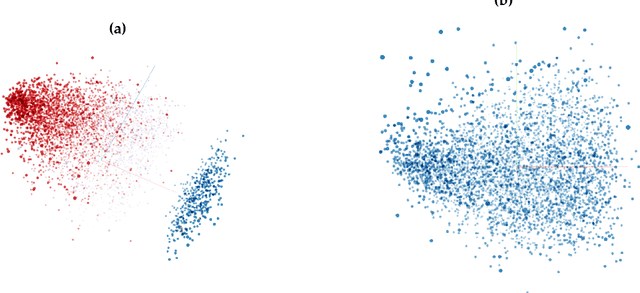
Deep Learning models are vulnerable to adversarial examples, i.e.\ images obtained via deliberate imperceptible perturbations, such that the model misclassifies them with high confidence. However, class confidence by itself is an incomplete picture of uncertainty. We therefore use principled Bayesian methods to capture model uncertainty in prediction for observing adversarial misclassification. We provide an extensive study with different Bayesian neural networks attacked in both white-box and black-box setups. The behaviour of the networks for noise, attacks and clean test data is compared. We observe that Bayesian neural networks are uncertain in their predictions for adversarial perturbations, a behaviour similar to the one observed for random Gaussian perturbations. Thus, we conclude that Bayesian neural networks can be considered for detecting adversarial examples.
Efficient Defenses Against Adversarial Attacks
Aug 30, 2017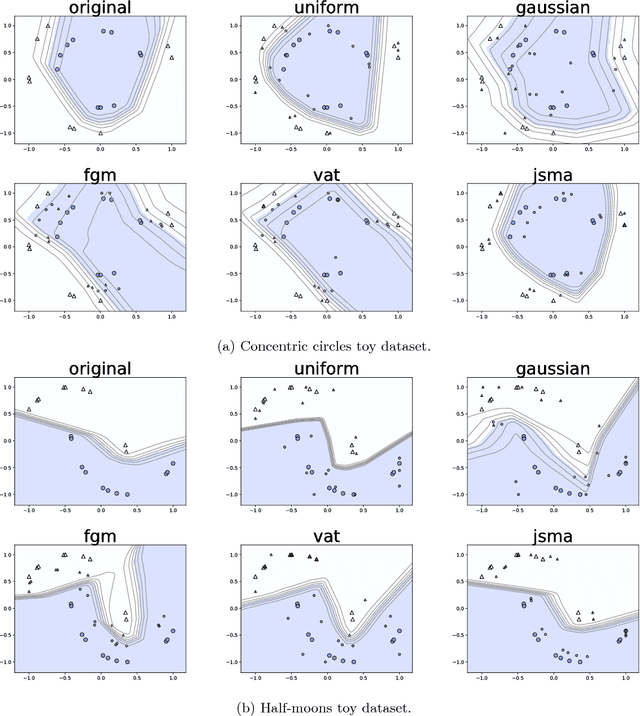

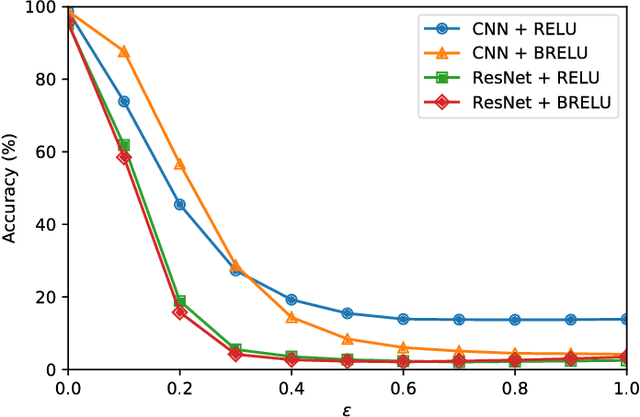
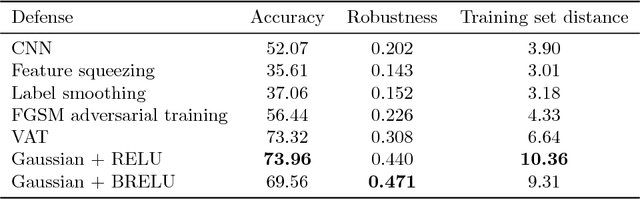
Following the recent adoption of deep neural networks (DNN) accross a wide range of applications, adversarial attacks against these models have proven to be an indisputable threat. Adversarial samples are crafted with a deliberate intention of undermining a system. In the case of DNNs, the lack of better understanding of their working has prevented the development of efficient defenses. In this paper, we propose a new defense method based on practical observations which is easy to integrate into models and performs better than state-of-the-art defenses. Our proposed solution is meant to reinforce the structure of a DNN, making its prediction more stable and less likely to be fooled by adversarial samples. We conduct an extensive experimental study proving the efficiency of our method against multiple attacks, comparing it to numerous defenses, both in white-box and black-box setups. Additionally, the implementation of our method brings almost no overhead to the training procedure, while maintaining the prediction performance of the original model on clean samples.
Open-World Visual Recognition Using Knowledge Graphs
Aug 28, 2017
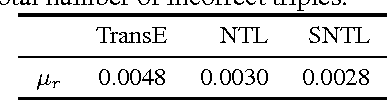
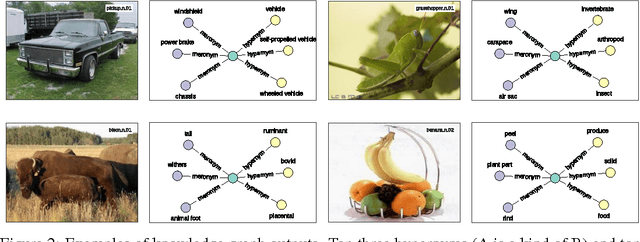
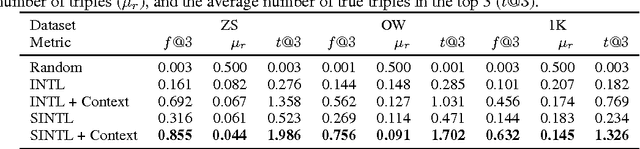
In a real-world setting, visual recognition systems can be brought to make predictions for images belonging to previously unknown class labels. In order to make semantically meaningful predictions for such inputs, we propose a two-step approach that utilizes information from knowledge graphs. First, a knowledge-graph representation is learned to embed a large set of entities into a semantic space. Second, an image representation is learned to embed images into the same space. Under this setup, we are able to predict structured properties in the form of relationship triples for any open-world image. This is true even when a set of labels has been omitted from the training protocols of both the knowledge graph and image embeddings. Furthermore, we append this learning framework with appropriate smoothness constraints and show how prior knowledge can be incorporated into the model. Both these improvements combined increase performance for visual recognition by a factor of six compared to our baseline. Finally, we propose a new, extended dataset which we use for experiments.
Similarity Learning for Time Series Classification
Oct 15, 2016
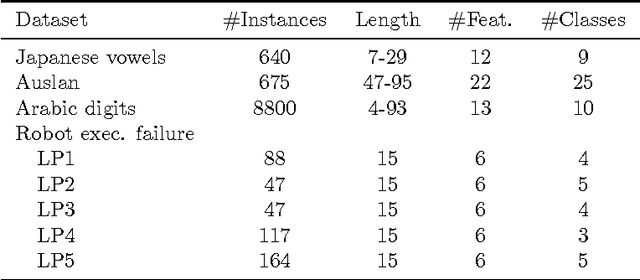
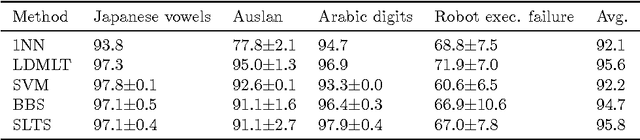
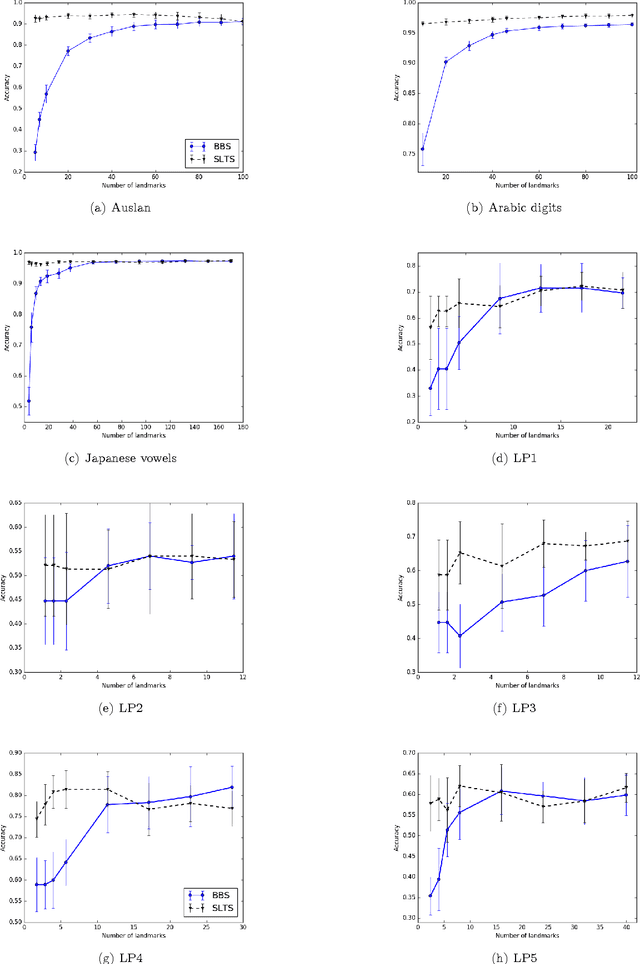
Multivariate time series naturally exist in many fields, like energy, bioinformatics, signal processing, and finance. Most of these applications need to be able to compare these structured data. In this context, dynamic time warping (DTW) is probably the most common comparison measure. However, not much research effort has been put into improving it by learning. In this paper, we propose a novel method for learning similarities based on DTW, in order to improve time series classification. Making use of the uniform stability framework, we provide the first theoretical guarantees in the form of a generalization bound for linear classification. The experimental study shows that the proposed approach is efficient, while yielding sparse classifiers.
Algorithmic Robustness for Learning via $(ε, γ, τ)$-Good Similarity Functions
Mar 31, 2015

The notion of metric plays a key role in machine learning problems such as classification, clustering or ranking. However, it is worth noting that there is a severe lack of theoretical guarantees that can be expected on the generalization capacity of the classifier associated to a given metric. The theoretical framework of $(\epsilon, \gamma, \tau)$-good similarity functions (Balcan et al., 2008) has been one of the first attempts to draw a link between the properties of a similarity function and those of a linear classifier making use of it. In this paper, we extend and complete this theory by providing a new generalization bound for the associated classifier based on the algorithmic robustness framework.