 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
DExTeR: Weakly Semi-Supervised Object Detection with Class and Instance Experts for Medical Imaging
Jan 20, 2026Detecting anatomical landmarks in medical imaging is essential for diagnosis and intervention guidance. However, object detection models rely on costly bounding box annotations, limiting scalability. Weakly Semi-Supervised Object Detection (WSSOD) with point annotations proposes annotating each instance with a single point, minimizing annotation time while preserving localization signals. A Point-to-Box teacher model, trained on a small box-labeled subset, converts these point annotations into pseudo-box labels to train a student detector. Yet, medical imagery presents unique challenges, including overlapping anatomy, variable object sizes, and elusive structures, which hinder accurate bounding box inference. To overcome these challenges, we introduce DExTeR (DETR with Experts), a transformer-based Point-to-Box regressor tailored for medical imaging. Built upon Point-DETR, DExTeR encodes single-point annotations as object queries, refining feature extraction with the proposed class-guided deformable attention, which guides attention sampling using point coordinates and class labels to capture class-specific characteristics. To improve discrimination in complex structures, it introduces CLICK-MoE (CLass, Instance, and Common Knowledge Mixture of Experts), decoupling class and instance representations to reduce confusion among adjacent or overlapping instances. Finally, we implement a multi-point training strategy which promotes prediction consistency across different point placements, improving robustness to annotation variability. DExTeR achieves state-of-the-art performance across three datasets spanning different medical domains (endoscopy, chest X-rays, and endoscopic ultrasound) highlighting its potential to reduce annotation costs while maintaining high detection accuracy.
Where It Moves, It Matters: Referring Surgical Instrument Segmentation via Motion
Jan 18, 2026Enabling intuitive, language-driven interaction with surgical scenes is a critical step toward intelligent operating rooms and autonomous surgical robotic assistance. However, the task of referring segmentation, localizing surgical instruments based on natural language descriptions, remains underexplored in surgical videos, with existing approaches struggling to generalize due to reliance on static visual cues and predefined instrument names. In this work, we introduce SurgRef, a novel motion-guided framework that grounds free-form language expressions in instrument motion, capturing how tools move and interact across time, rather than what they look like. This allows models to understand and segment instruments even under occlusion, ambiguity, or unfamiliar terminology. To train and evaluate SurgRef, we present Ref-IMotion, a diverse, multi-institutional video dataset with dense spatiotemporal masks and rich motion-centric expressions. SurgRef achieves state-of-the-art accuracy and generalization across surgical procedures, setting a new benchmark for robust, language-driven surgical video segmentation.
Artificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
Dec 16, 2025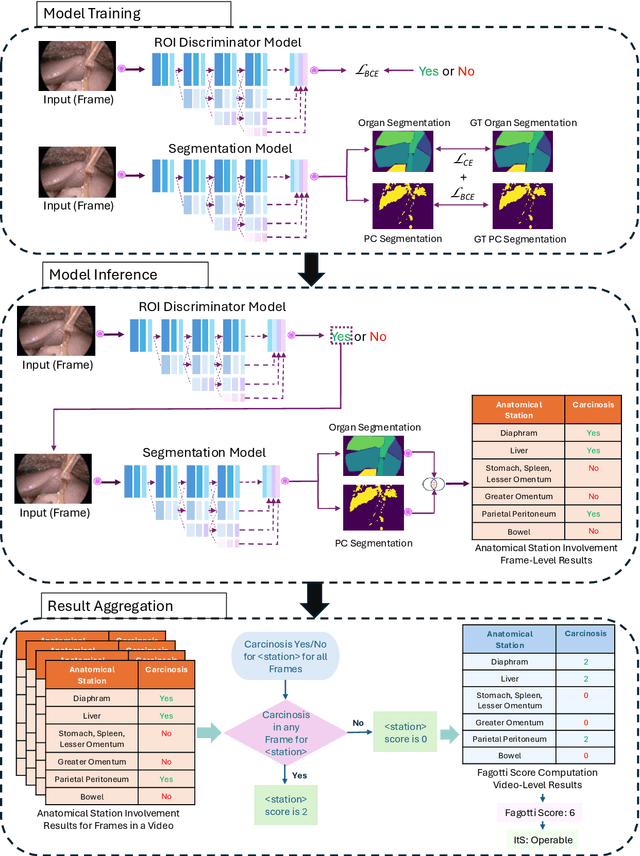
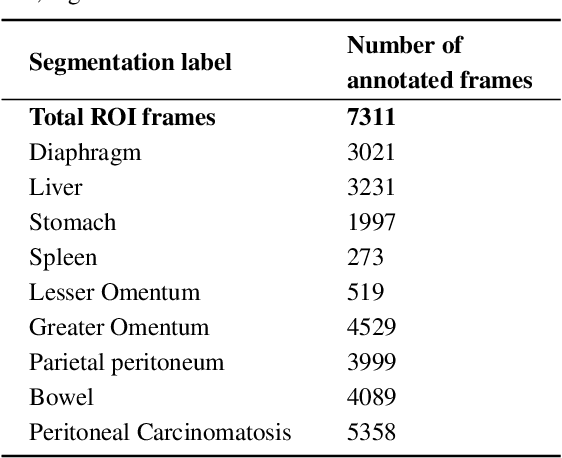


Advanced Ovarian Cancer (AOC) is often diagnosed at an advanced stage with peritoneal carcinosis (PC). Fagotti score (FS) assessment at diagnostic laparoscopy (DL) guides treatment planning by estimating surgical resectability, but its subjective and operator-dependent nature limits reproducibility and widespread use. Videos of patients undergoing DL with concomitant FS assessments at a referral center were retrospectively collected and divided into a development dataset, for data annotation, AI training and evaluation, and an independent test dataset, for internal validation. In the development dataset, FS-relevant frames were manually annotated for anatomical structures and PC. Deep learning models were trained to automatically identify FS-relevant frames, segment structures and PC, and predict video-level FS and indication to surgery (ItS). AI performance was evaluated using Dice score for segmentation, F1-scores for anatomical stations (AS) and ItS prediction, and root mean square error (RMSE) for final FS estimation. In the development dataset, the segmentation model trained on 7,311 frames, achieved Dice scores of 70$\pm$3% for anatomical structures and 56$\pm$3% for PC. Video-level AS classification achieved F1-scores of 74$\pm$3% and 73$\pm$4%, FS prediction showed normalized RMSE values of 1.39$\pm$0.18 and 1.15$\pm$0.08, and ItS reached F1-scores of 80$\pm$8% and 80$\pm$2% in the development (n=101) and independent test datasets (n=50), respectively. This is the first AI model to predict the feasibility of cytoreductive surgery providing automated FS estimation from DL videos. Its reproducible and reliable performance across datasets suggests that AI can support surgeons through standardized intraoperative tumor burden assessment and clinical decision-making in AOC.
Expert Consensus-based Video-Based Assessment Tool for Workflow Analysis in Minimally Invasive Colorectal Surgery: Development and Validation of ColoWorkflow
Nov 13, 2025



Minimally invasive colorectal surgery is characterized by procedural variability, a difficult learning curve, and complications that impact quality and outcomes. Video-based assessment (VBA) offers an opportunity to generate data-driven insights to reduce variability, optimize training, and improve surgical performance. However, existing tools for workflow analysis remain difficult to standardize and implement. This study aims to develop and validate a VBA tool for workflow analysis across minimally invasive colorectal procedures. A Delphi process was conducted to achieve consensus on generalizable workflow descriptors. The resulting framework informed the development of a new VBA tool, ColoWorkflow. Independent raters then applied ColoWorkflow to a multicentre video dataset of laparoscopic and robotic colorectal surgery (CRS). Applicability and inter-rater reliability were evaluated. Consensus was achieved for 10 procedure-agnostic phases and 34 procedure-specific steps describing CRS workflows. ColoWorkflow was developed and applied to 54 colorectal operative videos (left and right hemicolectomies, sigmoid and rectosigmoid resections, and total proctocolectomies) from five centres. The tool demonstrated broad applicability, with all but one label utilized. Inter-rater reliability was moderate, with mean Cohen's K of 0.71 for phases and 0.66 for steps. Most discrepancies arose at phase transitions and step boundary definitions. ColoWorkflow is the first consensus-based, validated VBA tool for comprehensive workflow analysis in minimally invasive CRS. It establishes a reproducible framework for video-based performance assessment, enabling benchmarking across institutions and supporting the development of artificial intelligence-driven workflow recognition. Its adoption may standardize training, accelerate competency acquisition, and advance data-informed surgical quality improvement.
Federated Learning for Surgical Vision in Appendicitis Classification: Results of the FedSurg EndoVis 2024 Challenge
Oct 06, 2025Purpose: The FedSurg challenge was designed to benchmark the state of the art in federated learning for surgical video classification. Its goal was to assess how well current methods generalize to unseen clinical centers and adapt through local fine-tuning while enabling collaborative model development without sharing patient data. Methods: Participants developed strategies to classify inflammation stages in appendicitis using a preliminary version of the multi-center Appendix300 video dataset. The challenge evaluated two tasks: generalization to an unseen center and center-specific adaptation after fine-tuning. Submitted approaches included foundation models with linear probing, metric learning with triplet loss, and various FL aggregation schemes (FedAvg, FedMedian, FedSAM). Performance was assessed using F1-score and Expected Cost, with ranking robustness evaluated via bootstrapping and statistical testing. Results: In the generalization task, performance across centers was limited. In the adaptation task, all teams improved after fine-tuning, though ranking stability was low. The ViViT-based submission achieved the strongest overall performance. The challenge highlighted limitations in generalization, sensitivity to class imbalance, and difficulties in hyperparameter tuning in decentralized training, while spatiotemporal modeling and context-aware preprocessing emerged as promising strategies. Conclusion: The FedSurg Challenge establishes the first benchmark for evaluating FL strategies in surgical video classification. Findings highlight the trade-off between local personalization and global robustness, and underscore the importance of architecture choice, preprocessing, and loss design. This benchmarking offers a reference point for future development of imbalance-aware, adaptive, and robust FL methods in clinical surgical AI.
Learning from Sparse Point Labels for Dense Carcinosis Localization in Advanced Ovarian Cancer Assessment
Jul 09, 2025Learning from sparse labels is a challenge commonplace in the medical domain. This is due to numerous factors, such as annotation cost, and is especially true for newly introduced tasks. When dense pixel-level annotations are needed, this becomes even more unfeasible. However, being able to learn from just a few annotations at the pixel-level, while extremely difficult and underutilized, can drive progress in studies where perfect annotations are not immediately available. This work tackles the challenge of learning the dense prediction task of keypoint localization from a few point annotations in the context of 2d carcinosis keypoint localization from laparoscopic video frames for diagnostic planning of advanced ovarian cancer patients. To enable this, we formulate the problem as a sparse heatmap regression from a few point annotations per image and propose a new loss function, called Crag and Tail loss, for efficient learning. Our proposed loss function effectively leverages positive sparse labels while minimizing the impact of false negatives or missed annotations. Through an extensive ablation study, we demonstrate the effectiveness of our approach in achieving accurate dense localization of carcinosis keypoints, highlighting its potential to advance research in scenarios where dense annotations are challenging to obtain.
Surgeons Awareness, Expectations, and Involvement with Artificial Intelligence: a Survey Pre and Post the GPT Era
Jun 09, 2025Artificial Intelligence (AI) is transforming medicine, with generative AI models like ChatGPT reshaping perceptions of its potential. This study examines surgeons' awareness, expectations, and involvement with AI in surgery through comparative surveys conducted in 2021 and 2024. Two cross-sectional surveys were distributed globally in 2021 and 2024, the first before an IRCAD webinar and the second during the annual EAES meeting. The surveys assessed demographics, AI awareness, expectations, involvement, and ethics (2024 only). The surveys collected a total of 671 responses from 98 countries, 522 in 2021 and 149 in 2024. Awareness of AI courses rose from 14.5% in 2021 to 44.6% in 2024, while course attendance increased from 12.9% to 23%. Despite this, familiarity with foundational AI concepts remained limited. Expectations for AI's role shifted in 2024, with hospital management gaining relevance. Ethical concerns gained prominence, with 87.2% of 2024 participants emphasizing accountability and transparency. Infrastructure limitations remained the primary obstacle to implementation. Interdisciplinary collaboration and structured training were identified as critical for successful AI adoption. Optimism about AI's transformative potential remained high, with 79.9% of respondents believing AI would positively impact surgery and 96.6% willing to integrate AI into their clinical practice. Surgeons' perceptions of AI are evolving, driven by the rise of generative AI and advancements in surgical data science. While enthusiasm for integration is strong, knowledge gaps and infrastructural challenges persist. Addressing these through education, ethical frameworks, and infrastructure development is essential.
A Skull-Adaptive Framework for AI-Based 3D Transcranial Focused Ultrasound Simulation
May 19, 2025Transcranial focused ultrasound (tFUS) is an emerging modality for non-invasive brain stimulation and therapeutic intervention, offering millimeter-scale spatial precision and the ability to target deep brain structures. However, the heterogeneous and anisotropic nature of the human skull introduces significant distortions to the propagating ultrasound wavefront, which require time-consuming patient-specific planning and corrections using numerical solvers for accurate targeting. To enable data-driven approaches in this domain, we introduce TFUScapes, the first large-scale, high-resolution dataset of tFUS simulations through anatomically realistic human skulls derived from T1-weighted MRI images. We have developed a scalable simulation engine pipeline using the k-Wave pseudo-spectral solver, where each simulation returns a steady-state pressure field generated by a focused ultrasound transducer placed at realistic scalp locations. In addition to the dataset, we present DeepTFUS, a deep learning model that estimates normalized pressure fields directly from input 3D CT volumes and transducer position. The model extends a U-Net backbone with transducer-aware conditioning, incorporating Fourier-encoded position embeddings and MLP layers to create global transducer embeddings. These embeddings are fused with U-Net encoder features via feature-wise modulation, dynamic convolutions, and cross-attention mechanisms. The model is trained using a combination of spatially weighted and gradient-sensitive loss functions, enabling it to approximate high-fidelity wavefields. The TFUScapes dataset is publicly released to accelerate research at the intersection of computational acoustics, neurotechnology, and deep learning. The project page is available at https://github.com/CAMMA-public/TFUScapes.
Feature Mixing Approach for Detecting Intraoperative Adverse Events in Laparoscopic Roux-en-Y Gastric Bypass Surgery
Apr 23, 2025Intraoperative adverse events (IAEs), such as bleeding or thermal injury, can lead to severe postoperative complications if undetected. However, their rarity results in highly imbalanced datasets, posing challenges for AI-based detection and severity quantification. We propose BetaMixer, a novel deep learning model that addresses these challenges through a Beta distribution-based mixing approach, converting discrete IAE severity scores into continuous values for precise severity regression (0-5 scale). BetaMixer employs Beta distribution-based sampling to enhance underrepresented classes and regularizes intermediate embeddings to maintain a structured feature space. A generative approach aligns the feature space with sampled IAE severity, enabling robust classification and severity regression via a transformer. Evaluated on the MultiBypass140 dataset, which we extended with IAE labels, BetaMixer achieves a weighted F1 score of 0.76, recall of 0.81, PPV of 0.73, and NPV of 0.84, demonstrating strong performance on imbalanced data. By integrating Beta distribution-based sampling, feature mixing, and generative modeling, BetaMixer offers a robust solution for IAE detection and quantification in clinical settings.