 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Video-Pose Pretraining for Operating Room Surgical Activity Recognition
Feb 19, 2025



Understanding the workflow of surgical procedures in complex operating rooms requires a deep understanding of the interactions between clinicians and their environment. Surgical activity recognition (SAR) is a key computer vision task that detects activities or phases from multi-view camera recordings. Existing SAR models often fail to account for fine-grained clinician movements and multi-view knowledge, or they require calibrated multi-view camera setups and advanced point-cloud processing to obtain better results. In this work, we propose a novel calibration-free multi-view multi-modal pretraining framework called Multiview Pretraining for Video-Pose Surgical Activity Recognition PreViPS, which aligns 2D pose and vision embeddings across camera views. Our model follows CLIP-style dual-encoder architecture: one encoder processes visual features, while the other encodes human pose embeddings. To handle the continuous 2D human pose coordinates, we introduce a tokenized discrete representation to convert the continuous 2D pose coordinates into discrete pose embeddings, thereby enabling efficient integration within the dual-encoder framework. To bridge the gap between these two modalities, we propose several pretraining objectives using cross- and in-modality geometric constraints within the embedding space and incorporating masked pose token prediction strategy to enhance representation learning. Extensive experiments and ablation studies demonstrate improvements over the strong baselines, while data-efficiency experiments on two distinct operating room datasets further highlight the effectiveness of our approach. We highlight the benefits of our approach for surgical activity recognition in both multi-view and single-view settings, showcasing its practical applicability in complex surgical environments. Code will be made available at: https://github.com/CAMMA-public/PreViPS.
Self-supervised Learning via Cluster Distance Prediction for Operating Room Context Awareness
Jul 07, 2024Semantic segmentation and activity classification are key components to creating intelligent surgical systems able to understand and assist clinical workflow. In the Operating Room, semantic segmentation is at the core of creating robots aware of clinical surroundings, whereas activity classification aims at understanding OR workflow at a higher level. State-of-the-art semantic segmentation and activity recognition approaches are fully supervised, which is not scalable. Self-supervision can decrease the amount of annotated data needed. We propose a new 3D self-supervised task for OR scene understanding utilizing OR scene images captured with ToF cameras. Contrary to other self-supervised approaches, where handcrafted pretext tasks are focused on 2D image features, our proposed task consists of predicting the relative 3D distance of image patches by exploiting the depth maps. Learning 3D spatial context generates discriminative features for our downstream tasks. Our approach is evaluated on two tasks and datasets containing multi-view data captured from clinical scenarios. We demonstrate a noteworthy improvement of performance on both tasks, specifically on low-regime data where utility of self-supervised learning is the highest.
ST(OR)2: Spatio-Temporal Object Level Reasoning for Activity Recognition in the Operating Room
Dec 19, 2023



Surgical robotics holds much promise for improving patient safety and clinician experience in the Operating Room (OR). However, it also comes with new challenges, requiring strong team coordination and effective OR management. Automatic detection of surgical activities is a key requirement for developing AI-based intelligent tools to tackle these challenges. The current state-of-the-art surgical activity recognition methods however operate on image-based representations and depend on large-scale labeled datasets whose collection is time-consuming and resource-expensive. This work proposes a new sample-efficient and object-based approach for surgical activity recognition in the OR. Our method focuses on the geometric arrangements between clinicians and surgical devices, thus utilizing the significant object interaction dynamics in the OR. We conduct experiments in a low-data regime study for long video activity recognition. We also benchmark our method againstother object-centric approaches on clip-level action classification and show superior performance.
Dissecting Self-Supervised Learning Methods for Surgical Computer Vision
Jul 01, 2022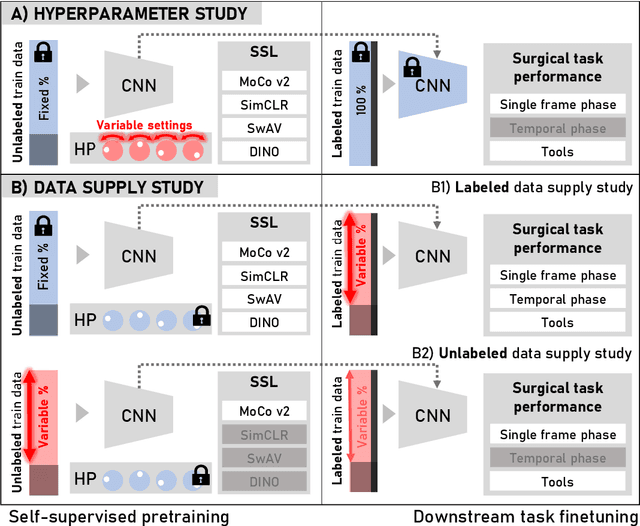
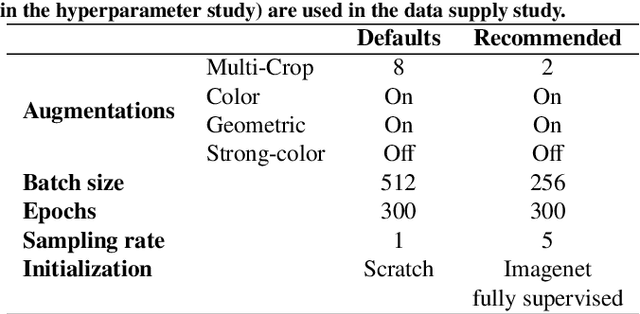
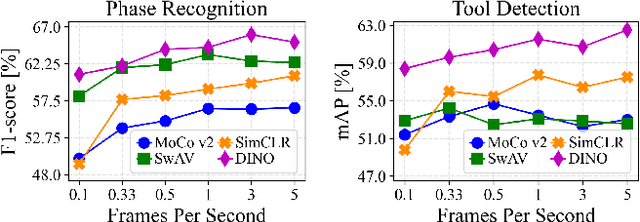
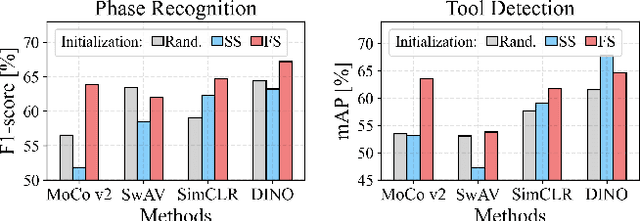
The field of surgical computer vision has undergone considerable breakthroughs in recent years with the rising popularity of deep neural network-based methods. However, standard fully-supervised approaches for training such models require vast amounts of annotated data, imposing a prohibitively high cost; especially in the clinical domain. Self-Supervised Learning (SSL) methods, which have begun to gain traction in the general computer vision community, represent a potential solution to these annotation costs, allowing to learn useful representations from only unlabeled data. Still, the effectiveness of SSL methods in more complex and impactful domains, such as medicine and surgery, remains limited and unexplored. In this work, we address this critical need by investigating four state-of-the-art SSL methods (MoCo v2, SimCLR, DINO, SwAV) in the context of surgical computer vision. We present an extensive analysis of the performance of these methods on the Cholec80 dataset for two fundamental and popular tasks in surgical context understanding, phase recognition and tool presence detection. We examine their parameterization, then their behavior with respect to training data quantities in semi-supervised settings. Correct transfer of these methods to surgery, as described and conducted in this work, leads to substantial performance gains over generic uses of SSL - up to 7% on phase recognition and 20% on tool presence detection - as well as state-of-the-art semi-supervised phase recognition approaches by up to 14%. The code will be made available at https://github.com/CAMMA-public/SelfSupSurg.