 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning via Cluster Distance Prediction for Operating Room Context Awareness
Jul 07, 2024Semantic segmentation and activity classification are key components to creating intelligent surgical systems able to understand and assist clinical workflow. In the Operating Room, semantic segmentation is at the core of creating robots aware of clinical surroundings, whereas activity classification aims at understanding OR workflow at a higher level. State-of-the-art semantic segmentation and activity recognition approaches are fully supervised, which is not scalable. Self-supervision can decrease the amount of annotated data needed. We propose a new 3D self-supervised task for OR scene understanding utilizing OR scene images captured with ToF cameras. Contrary to other self-supervised approaches, where handcrafted pretext tasks are focused on 2D image features, our proposed task consists of predicting the relative 3D distance of image patches by exploiting the depth maps. Learning 3D spatial context generates discriminative features for our downstream tasks. Our approach is evaluated on two tasks and datasets containing multi-view data captured from clinical scenarios. We demonstrate a noteworthy improvement of performance on both tasks, specifically on low-regime data where utility of self-supervised learning is the highest.
Adaptation of Surgical Activity Recognition Models Across Operating Rooms
Jul 07, 2022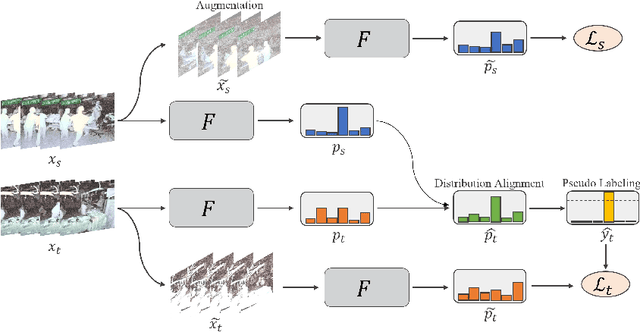


Automatic surgical activity recognition enables more intelligent surgical devices and a more efficient workflow. Integration of such technology in new operating rooms has the potential to improve care delivery to patients and decrease costs. Recent works have achieved a promising performance on surgical activity recognition; however, the lack of generalizability of these models is one of the critical barriers to the wide-scale adoption of this technology. In this work, we study the generalizability of surgical activity recognition models across operating rooms. We propose a new domain adaptation method to improve the performance of the surgical activity recognition model in a new operating room for which we only have unlabeled videos. Our approach generates pseudo labels for unlabeled video clips that it is confident about and trains the model on the augmented version of the clips. We extend our method to a semi-supervised domain adaptation setting where a small portion of the target domain is also labeled. In our experiments, our proposed method consistently outperforms the baselines on a dataset of more than 480 long surgical videos collected from two operating rooms.
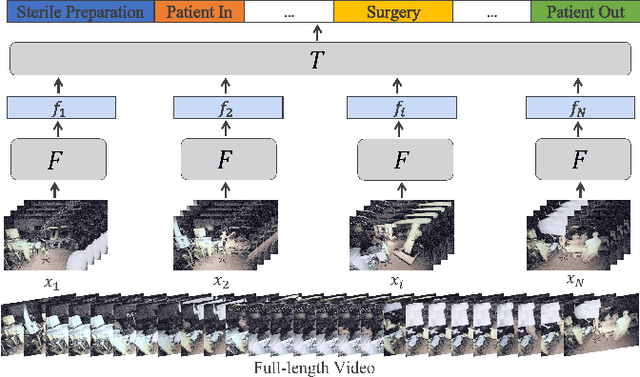
Activity Detection in Long Surgical Videos using Spatio-Temporal Models
May 05, 2022



Automatic activity detection is an important component for developing technologies that enable next generation surgical devices and workflow monitoring systems. In many application, the videos of interest are long and include several activities; hence, the deep models designed for such purposes consist of a backbone and a temporal sequence modeling architecture. In this paper, we investigate both the state-of-the-art activity recognition and temporal models to find the architectures that yield the highest performance. We first benchmark these models on a large-scale activity recognition dataset in the operating room with over 800 full-length surgical videos. However, since most other medical applications lack such a large dataset, we further evaluate our models on the Cholec80 surgical phase segmentation dataset, consisting of only 40 training videos. For backbone architectures, we investigate both 3D ConvNets and most recent transformer-based models; for temporal modeling, we include temporal ConvNets, RNNs, and transformer models for a comprehensive and thorough study. We show that even in the case of limited labeled data, we can outperform the existing work by benefiting from models pre-trained on other tasks.
Surgical Workflow Recognition: from Analysis of Challenges to Architectural Study
Mar 17, 2022


Algorithmic surgical workflow recognition is an ongoing research field and can be divided into laparoscopic (Internal) and operating room (External) analysis. So far many different works for the internal analysis have been proposed with the combination of a frame-level and an additional temporal model to address the temporal ambiguities between different workflow phases. For the External recognition task, Clip-level methods are in the focus of researchers targeting the local ambiguities present in the OR scene. In this work we evaluate combinations of different model architectures for the task of surgical workflow recognition to provide a fair comparison of the methods for both Internal and External analysis. We show that methods designed for the Internal analysis can be transferred to the external task with comparable performance gains for different architectures.
Automatic Operating Room Surgical Activity Recognition for Robot-Assisted Surgery
Jun 29, 2020
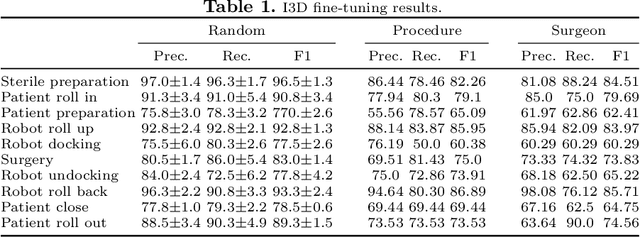
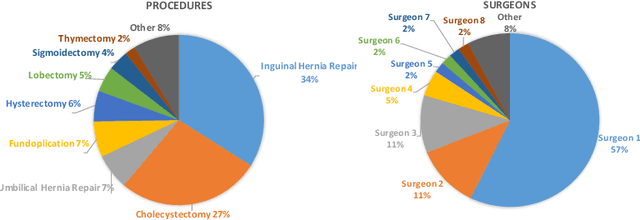

Automatic recognition of surgical activities in the operating room (OR) is a key technology for creating next generation intelligent surgical devices and workflow monitoring/support systems. Such systems can potentially enhance efficiency in the OR, resulting in lower costs and improved care delivery to the patients. In this paper, we investigate automatic surgical activity recognition in robot-assisted operations. We collect the first large-scale dataset including 400 full-length multi-perspective videos from a variety of robotic surgery cases captured using Time-of-Flight cameras. We densely annotate the videos with 10 most recognized and clinically relevant classes of activities. Furthermore, we investigate state-of-the-art computer vision action recognition techniques and adapt them for the OR environment and the dataset. First, we fine-tune the Inflated 3D ConvNet (I3D) for clip-level activity recognition on our dataset and use it to extract features from the videos. These features are then fed to a stack of 3 Temporal Gaussian Mixture layers which extracts context from neighboring clips, and eventually go through a Long Short Term Memory network to learn the order of activities in full-length videos. We extensively assess the model and reach a peak performance of 88% mean Average Precision.
Text Synopsis Generation for Egocentric Videos
May 08, 2020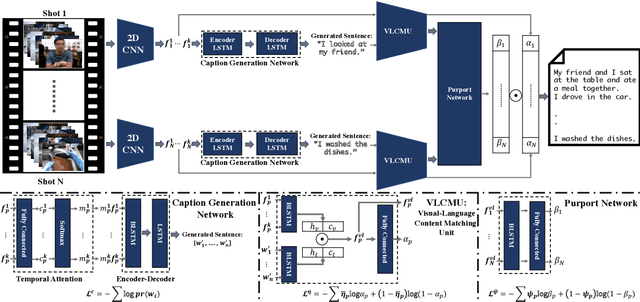
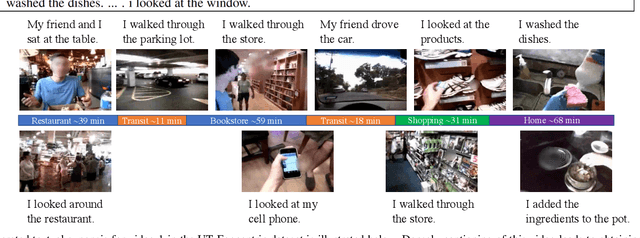


Mass utilization of body-worn cameras has led to a huge corpus of available egocentric video. Existing video summarization algorithms can accelerate browsing such videos by selecting (visually) interesting shots from them. Nonetheless, since the system user still has to watch the summary videos, browsing large video databases remain a challenge. Hence, in this work, we propose to generate a textual synopsis, consisting of a few sentences describing the most important events in a long egocentric videos. Users can read the short text to gain insight about the video, and more importantly, efficiently search through the content of a large video database using text queries. Since egocentric videos are long and contain many activities and events, using video-to-text algorithms results in thousands of descriptions, many of which are incorrect. Therefore, we propose a multi-task learning scheme to simultaneously generate descriptions for video segments and summarize the resulting descriptions in an end-to-end fashion. We Input a set of video shots and the network generates a text description for each shot. Next, visual-language content matching unit that is trained with a weakly supervised objective, identifies the correct descriptions. Finally, the last component of our network, called purport network, evaluates the descriptions all together to select the ones containing crucial information. Out of thousands of descriptions generated for the video, a few informative sentences are returned to the user. We validate our framework on the challenging UT Egocentric video dataset, where each video is between 3 to 5 hours long, associated with over 3000 textual descriptions on average. The generated textual summaries, including only 5 percent (or less) of the generated descriptions, are compared to groundtruth summaries in text domain using well-established metrics in natural language processing.
Multi-View Egocentric Video Summarization
Dec 01, 2018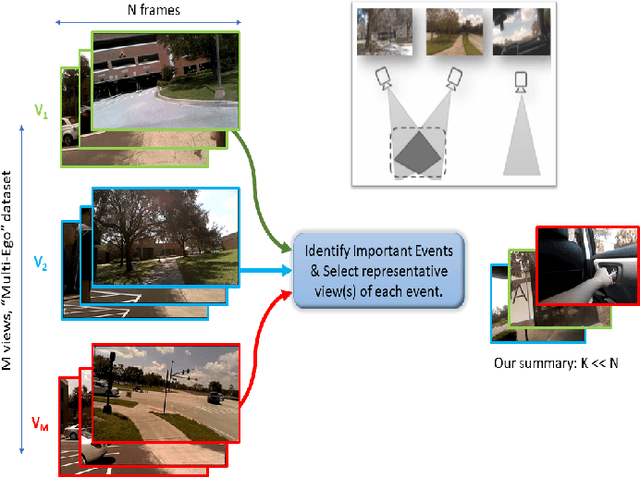
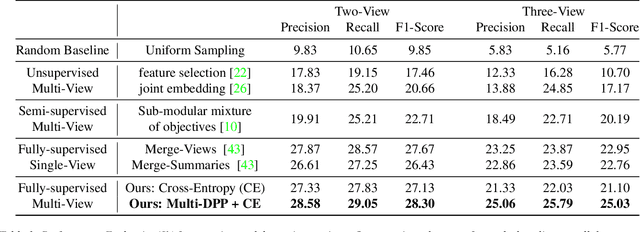
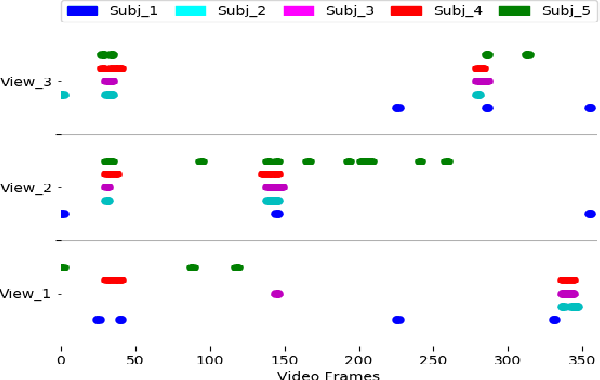
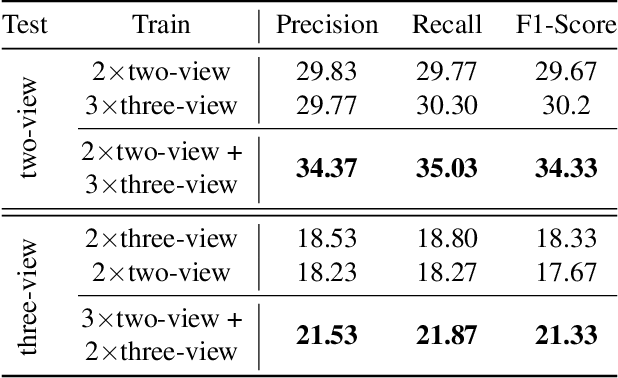
With vast amounts of video content being uploaded to the Internet every minute, video summarization becomes critical for efficient browsing, searching, and indexing of visual content. Nonetheless, the spread of social and egocentric cameras tends to create an abundance of sparse scenarios captured by several devices, and ultimately required to be jointly summarized. In this paper, we propose the problem of summarizing videos recorded simultaneously by several egocentric cameras that intermittently share the field of view. We present a supervised-learning framework that (a) identifies a diverse set of important events among dynamically moving cameras that often are not capturing the same scene, and (b) selects the most representative view(s) at each event to be included in the universal summary. A key contribution of our work is collecting a new multi-view egocentric dataset, Multi-Ego, due to the lack of an applicable and relevant alternative. Our dataset consists of 41 sequences, each recorded simultaneously by 3 cameras and covering a wide variety of real-life scenarios. The footage is annotated comprehensively by multiple individuals under various summarization settings: (a) single view, (b) two view, and (c) three view, with a consensus analysis ensuring a reliable ground truth. We conduct extensive experiments on the compiled dataset to show the effectiveness of our approach over several state-of-the-art baselines. We also show that it can learn from data of varied number-of-views, deeming it a scalable and a generic summarization approach. Our dataset and materials are publicly available.
Improving Sequential Determinantal Point Processes for Supervised Video Summarization
Oct 24, 2018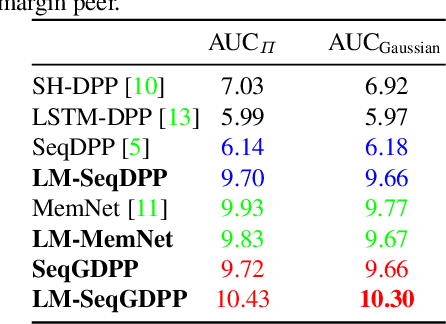
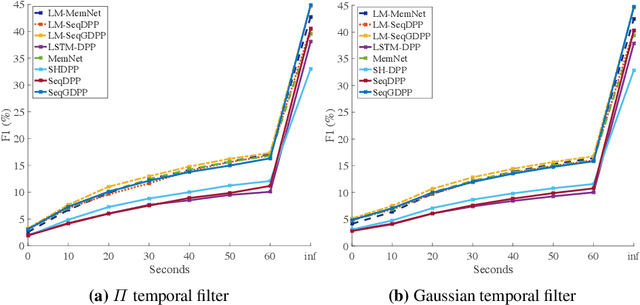
It is now much easier than ever before to produce videos. While the ubiquitous video data is a great source for information discovery and extraction, the computational challenges are unparalleled. Automatically summarizing the videos has become a substantial need for browsing, searching, and indexing visual content. This paper is in the vein of supervised video summarization using sequential determinantal point process (SeqDPP), which models diversity by a probabilistic distribution. We improve this model in two folds. In terms of learning, we propose a large-margin algorithm to address the exposure bias problem in SeqDPP. In terms of modeling, we design a new probabilistic distribution such that, when it is integrated into SeqDPP, the resulting model accepts user input about the expected length of the summary. Moreover, we also significantly extend a popular video summarization dataset by 1) more egocentric videos, 2) dense user annotations, and 3) a refined evaluation scheme. We conduct extensive experiments on this dataset (about 60 hours of videos in total) and compare our approach to several competitive baselines.
Fully-Coupled Two-Stream Spatiotemporal Networks for Extremely Low Resolution Action Recognition
Jan 11, 2018

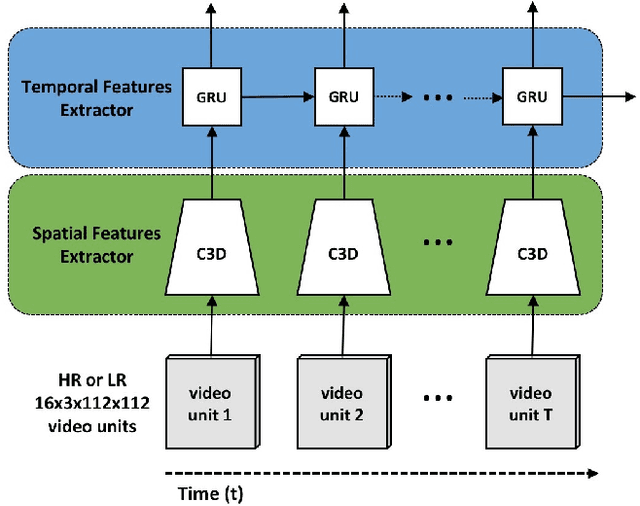

A major emerging challenge is how to protect people's privacy as cameras and computer vision are increasingly integrated into our daily lives, including in smart devices inside homes. A potential solution is to capture and record just the minimum amount of information needed to perform a task of interest. In this paper, we propose a fully-coupled two-stream spatiotemporal architecture for reliable human action recognition on extremely low resolution (e.g., 12x16 pixel) videos. We provide an efficient method to extract spatial and temporal features and to aggregate them into a robust feature representation for an entire action video sequence. We also consider how to incorporate high resolution videos during training in order to build better low resolution action recognition models. We evaluate on two publicly-available datasets, showing significant improvements over the state-of-the-art.
Query-Focused Video Summarization: Dataset, Evaluation, and A Memory Network Based Approach
Jul 16, 2017

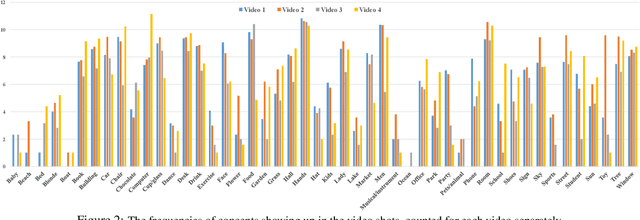
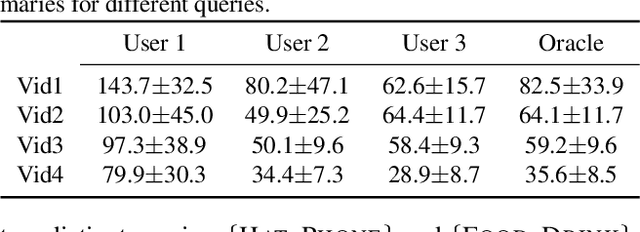
Recent years have witnessed a resurgence of interest in video summarization. However, one of the main obstacles to the research on video summarization is the user subjectivity - users have various preferences over the summaries. The subjectiveness causes at least two problems. First, no single video summarizer fits all users unless it interacts with and adapts to the individual users. Second, it is very challenging to evaluate the performance of a video summarizer. To tackle the first problem, we explore the recently proposed query-focused video summarization which introduces user preferences in the form of text queries about the video into the summarization process. We propose a memory network parameterized sequential determinantal point process in order to attend the user query onto different video frames and shots. To address the second challenge, we contend that a good evaluation metric for video summarization should focus on the semantic information that humans can perceive rather than the visual features or temporal overlaps. To this end, we collect dense per-video-shot concept annotations, compile a new dataset, and suggest an efficient evaluation method defined upon the concept annotations. We conduct extensive experiments contrasting our video summarizer to existing ones and present detailed analyses about the dataset and the new evaluation method.