 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
Apr 13, 2026Frontier coding agents solve complex tasks when given complete context but collapse when specifications are incomplete or ambiguous. The bottleneck is not raw capability, but judgment: knowing when to act autonomously and when to ask for help. Current benchmarks are blind to this failure mode. They supply unambiguous detailed instructions and solely reward execution correctness, so an agent that makes a lucky guess for a missing requirement will score identically to one that would have asked to be certain. We present HiL-Bench (Human-in-the-Loop Benchmark) to measure this selective escalation skill. Each task contains human-validated blockers (missing information, ambiguous requests, contradictory information) that surface only through progressive exploration, not upfront inspection. Our core metric, Ask-F1, the harmonic mean of question precision and blocker recall, captures the tension between over-asking and silent guessing; its structure architecturally prevents gaming through question spam. Evaluation across SWE and text-to-SQL domains reveals a large universal judgment gap: no frontier model recovers more than a fraction of its full-information performance when deciding whether to ask. Failure analysis identifies three key help-seeking patterns: overconfident wrong beliefs with no gap detection; high uncertainty detection yet persistent errors; broad, imprecise escalation without self-correction. These consistent patterns confirm poor help-seeking is a model-level flaw, not task-specific. RL training on shaped Ask-F1 reward shows judgment is trainable: a 32B model improves both help-seeking quality and task pass rate, with gains that transfer across domains. The model does not learn domain-specific heuristics for when to ask; it learns to detect unresolvable uncertainty and act on it.
Return of the Encoder: Maximizing Parameter Efficiency for SLMs
Jan 27, 2025The dominance of large decoder-only language models has overshadowed encoder-decoder architectures, despite their fundamental efficiency advantages in sequence processing. For small language models (SLMs) - those with 1 billion parameters or fewer - our systematic analysis across GPU, CPU, and NPU platforms reveals that encoder-decoder architectures achieve 47% lower first-token latency and 4.7x higher throughput compared to decoder-only models on edge devices. These gains may be attributed to encoder-decoder's one-time input processing and efficient separation of understanding and generation phases. We introduce a novel knowledge distillation framework that enables encoder-decoder models to leverage capabilities from large scalable decoder-only teachers while preserving their architectural advantages, achieving up to 6 average performance points improvement across diverse tasks, with significant gains in asymmetric sequence tasks where input and output distributions can benefit from different processing approaches. When combined with modern advances like Rotary Positional Embeddings (RoPE) and Vision encoders, our systematic investigation demonstrates that encoder-decoder architectures provide a more practical path toward deploying capable language models in resource-constrained environments. Our findings challenge the prevailing trend toward decoder-only scaling, showing that architectural choices become increasingly crucial as parameter budgets decrease, particularly for on-device and edge deployments where computational efficiency is paramount.
CIZSL++: Creativity Inspired Generative Zero-Shot Learning
Jan 01, 2021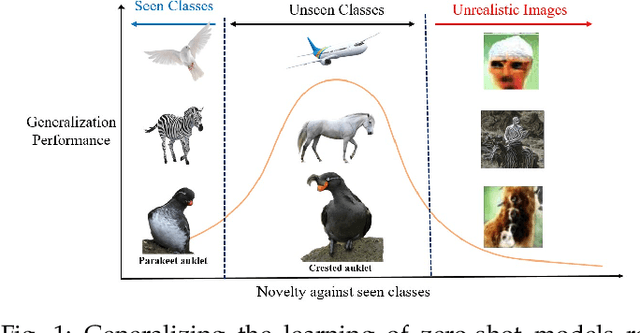
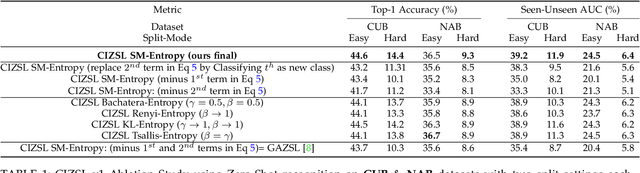
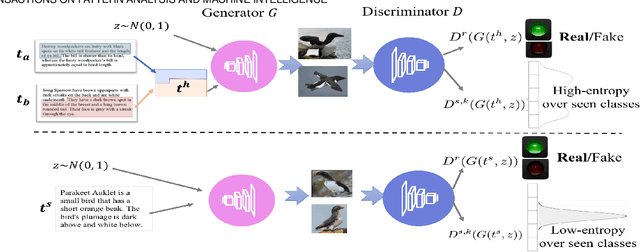
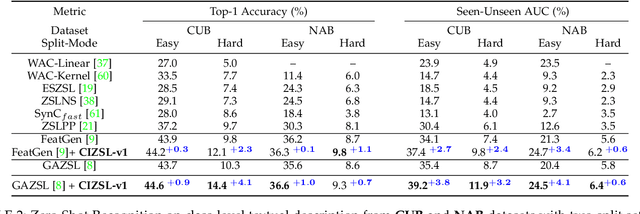
Zero-shot learning (ZSL) aims at understanding unseen categories with no training examples from class-level descriptions. To improve the discriminative power of ZSL, we model the visual learning process of unseen categories with inspiration from the psychology of human creativity for producing novel art. First, we propose CIZSL-v1 as a creativity inspired model for generative ZSL. We relate ZSL to human creativity by observing that ZSL is about recognizing the unseen, and creativity is about creating a likable unseen. We introduce a learning signal inspired by creativity literature that explores the unseen space with hallucinated class-descriptions and encourages careful deviation of their visual feature generations from seen classes while allowing knowledge transfer from seen to unseen classes. Second, CIZSL-v2 is proposed as an improved version of CIZSL-v1 for generative zero-shot learning. CIZSL-v2 consists of an investigation of additional inductive losses for unseen classes along with a semantic guided discriminator. Empirically, we show consistently that CIZSL losses can improve generative ZSL models on the challenging task of generalized ZSL from a noisy text on CUB and NABirds datasets. We also show the advantage of our approach to Attribute-based ZSL on AwA2, aPY, and SUN datasets. We also show that CIZSL-v2 has improved performance compared to CIZSL-v1.
* This paper is an extended version of a paper published on the International Conference on Computer Vision (ICCV), held in Seoul, Republic of Korea, October 27-Nov 2nd, 2019 CIZSL-v2 code is available here https://github.com/Elhoseiny-VisionCAIR-Lab/CIZSL.v2/. arXiv admin note: substantial text overlap with arXiv:1904.01109
Creativity Inspired Zero-Shot Learning
Apr 17, 2019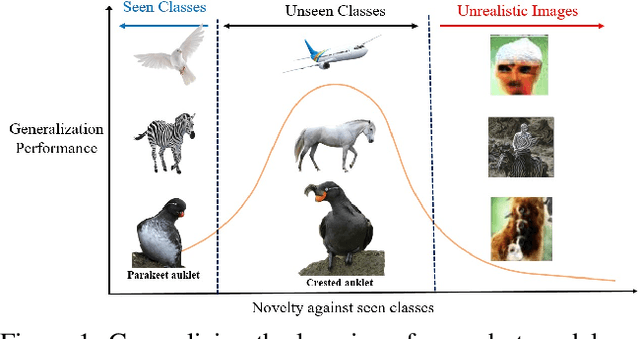

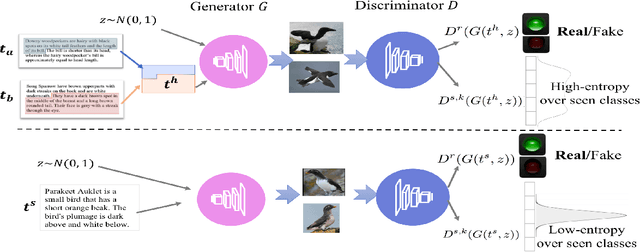
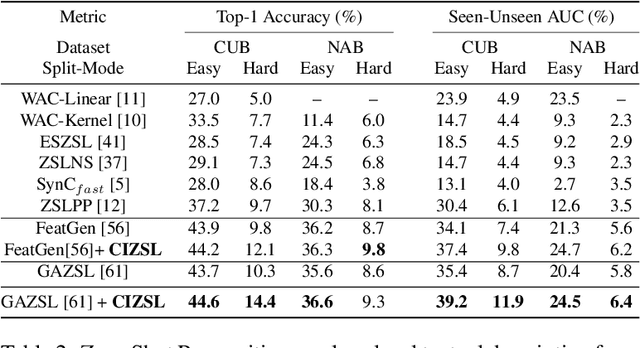
Zero-shot learning (ZSL) aims at understanding unseen categories with no training examples from class-level descriptions. To improve the discriminative power of zero-shot learning, we model the visual learning process of unseen categories with an inspiration from the psychology of human creativity for producing novel art. We relate ZSL to human creativity by observing that zero-shot learning is about recognizing the unseen and creativity is about creating a likable unseen. We introduce a learning signal inspired by creativity literature that explores the unseen space with hallucinated class-descriptions and encourages careful deviation of their visual feature generations from seen classes while allowing knowledge transfer from seen to unseen classes. Empirically, we show consistent improvement over the state of the art of several percents on the largest available benchmarks on the challenging task or generalized ZSL from a noisy text that we focus on, using the CUB and NABirds datasets. We also show the advantage of our approach on Attribute-based ZSL on three additional datasets (AwA2, aPY, and SUN).
Video Summarization via Actionness Ranking
Mar 01, 2019


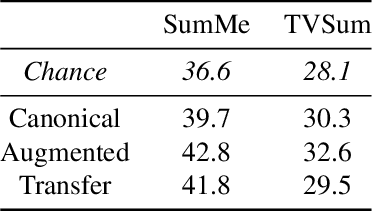
To automatically produce a brief yet expressive summary of a long video, an automatic algorithm should start by resembling the human process of summary generation. Prior work proposed supervised and unsupervised algorithms to train models for learning the underlying behavior of humans by increasing modeling complexity or craft-designing better heuristics to simulate human summary generation process. In this work, we take a different approach by analyzing a major cue that humans exploit for the summary generation; the nature and intensity of actions. We empirically observed that a frame is more likely to be included in human-generated summaries if it contains a substantial amount of deliberate motion performed by an agent, which is referred to as actionness. Therefore, we hypothesize that learning to automatically generate summaries involves an implicit knowledge of actionness estimation and ranking. We validate our hypothesis by running a user study that explores the correlation between human-generated summaries and actionness ranks. We also run a consensus and behavioral analysis between human subjects to ensure reliable and consistent results. The analysis exhibits a considerable degree of agreement among subjects within obtained data and verifying our initial hypothesis. Based on the study findings, we develop a method to incorporate actionness data to explicitly regulate a learning algorithm that is trained for summary generation. We assess the performance of our approach to four summarization benchmark datasets and demonstrate an evident advantage compared to state-of-the-art summarization methods.
GDPP: Learning Diverse Generations Using Determinantal Point Process
Dec 05, 2018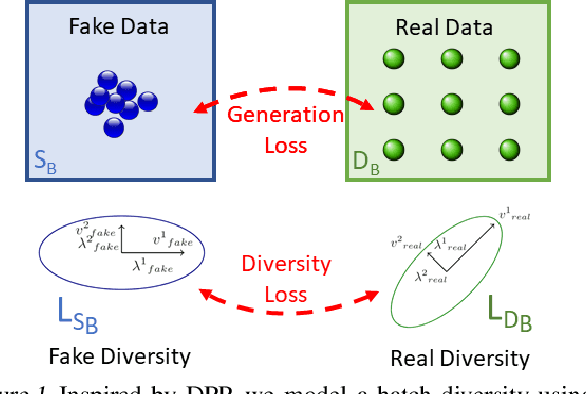
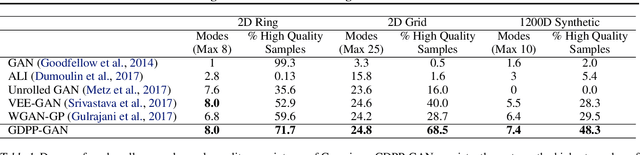
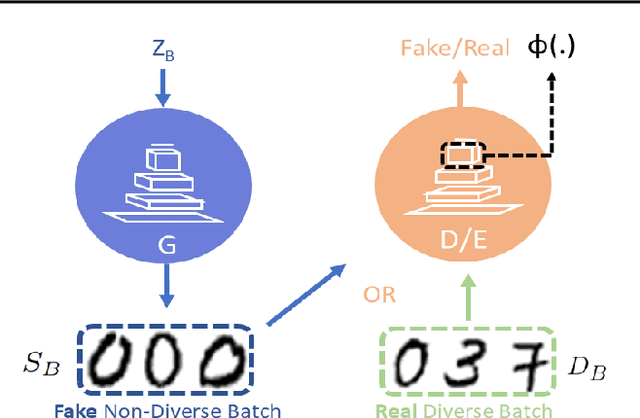
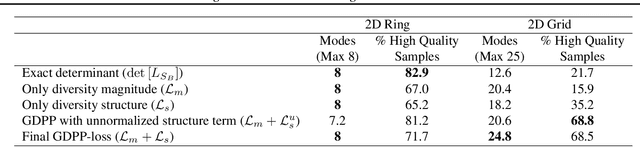
Generative models have proven to be an outstanding tool for representing high-dimensional probability distributions and generating realistic looking images. A fundamental characteristic of generative models is their ability to produce multi-modal outputs. However, while training, they are often susceptible to mode collapse, which means that the model is limited in mapping the input noise to only a few modes of the true data distribution. In this paper, we draw inspiration from Determinantal Point Process (DPP) to devise a generative model that alleviates mode collapse while producing higher quality samples. DPP is an elegant probabilistic measure used to model negative correlations within a subset and hence quantify its diversity. We use DPP kernel to model the diversity in real data as well as in synthetic data. Then, we devise a generation penalty term that encourages the generator to synthesize data with a similar diversity to real data. In contrast to previous state-of-the-art generative models that tend to use additional trainable parameters or complex training paradigms, our method does not change the original training scheme. Embedded in an adversarial training and variational autoencoder, our Generative DPP approach shows a consistent resistance to mode-collapse on a wide-variety of synthetic data and natural image datasets including MNIST, CIFAR10, and CelebA, while outperforming state-of-the-art methods for data-efficiency, convergence-time, and generation quality. Our code is publicly available.
Multi-View Egocentric Video Summarization
Dec 01, 2018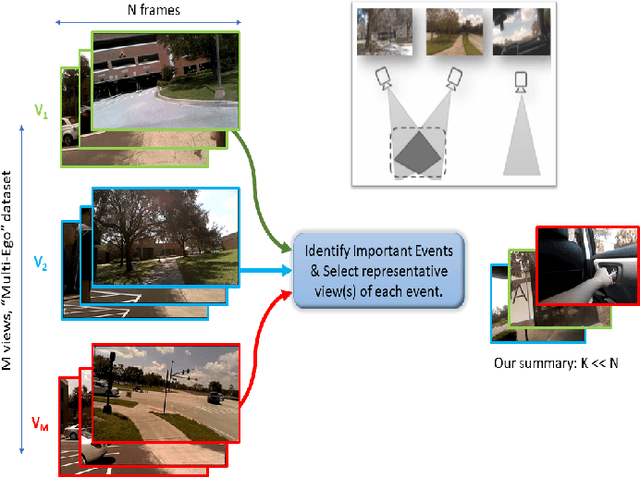
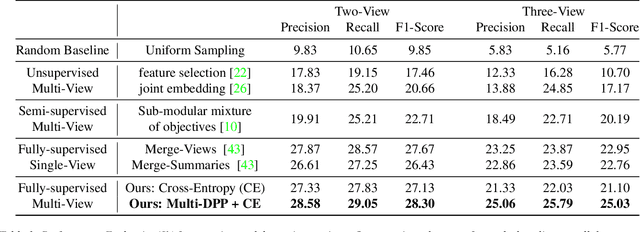
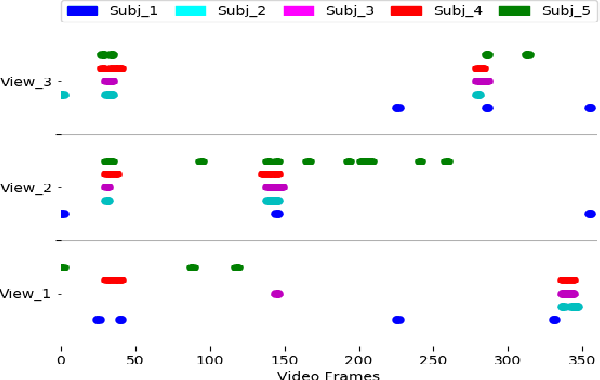
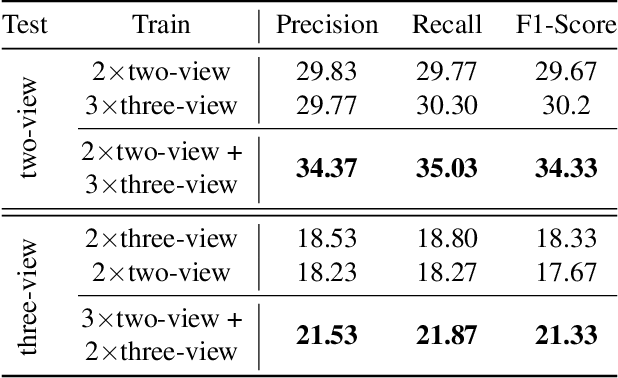
With vast amounts of video content being uploaded to the Internet every minute, video summarization becomes critical for efficient browsing, searching, and indexing of visual content. Nonetheless, the spread of social and egocentric cameras tends to create an abundance of sparse scenarios captured by several devices, and ultimately required to be jointly summarized. In this paper, we propose the problem of summarizing videos recorded simultaneously by several egocentric cameras that intermittently share the field of view. We present a supervised-learning framework that (a) identifies a diverse set of important events among dynamically moving cameras that often are not capturing the same scene, and (b) selects the most representative view(s) at each event to be included in the universal summary. A key contribution of our work is collecting a new multi-view egocentric dataset, Multi-Ego, due to the lack of an applicable and relevant alternative. Our dataset consists of 41 sequences, each recorded simultaneously by 3 cameras and covering a wide variety of real-life scenarios. The footage is annotated comprehensively by multiple individuals under various summarization settings: (a) single view, (b) two view, and (c) three view, with a consensus analysis ensuring a reliable ground truth. We conduct extensive experiments on the compiled dataset to show the effectiveness of our approach over several state-of-the-art baselines. We also show that it can learn from data of varied number-of-views, deeming it a scalable and a generic summarization approach. Our dataset and materials are publicly available.
From Third Person to First Person: Dataset and Baselines for Synthesis and Retrieval
Dec 01, 2018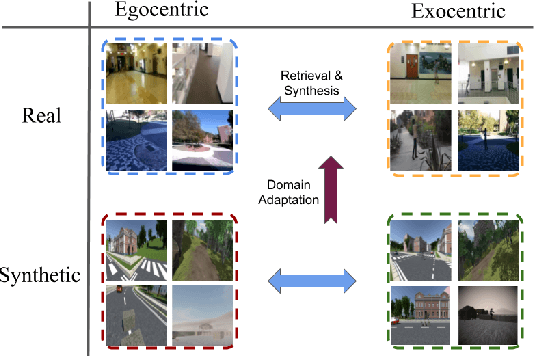



First-person (egocentric) and third person (exocentric) videos are drastically different in nature. The relationship between these two views have been studied in recent years, however, it has yet to be fully explored. In this work, we introduce two datasets (synthetic and natural/real) containing simultaneously recorded egocentric and exocentric videos. We also explore relating the two domains (egocentric and exocentric) in two aspects. First, we synthesize images in the egocentric domain from the exocentric domain using a conditional generative adversarial network (cGAN). We show that with enough training data, our network is capable of hallucinating how the world would look like from an egocentric perspective, given an exocentric video. Second, we address the cross-view retrieval problem across the two views. Given an egocentric query frame (or its momentary optical flow), we retrieve its corresponding exocentric frame (or optical flow) from a gallery set. We show that using synthetic data could be beneficial in retrieving real data. We show that performing domain adaptation from the synthetic domain to the natural/real domain, is helpful in tasks such as retrieval. We believe that the presented datasets and the proposed baselines offer new opportunities for further research in this direction. The code and dataset are publicly available.