 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Pushing the performances of ASR models on English and Spanish accents
Dec 22, 2022



Speech to text models tend to be trained and evaluated against a single target accent. This is especially true for English for which native speakers from the United States became the main benchmark. In this work, we are going to show how two simple methods: pre-trained embeddings and auxiliary classification losses can improve the performance of ASR systems. We are looking for upgrades as universal as possible and therefore we will explore their impact on several models architectures and several languages.
Learned Force Fields Are Ready For Ground State Catalyst Discovery
Sep 26, 2022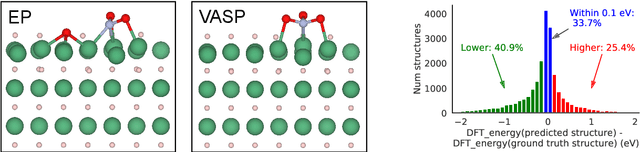
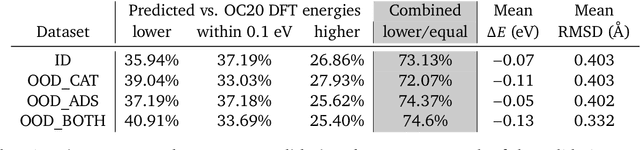
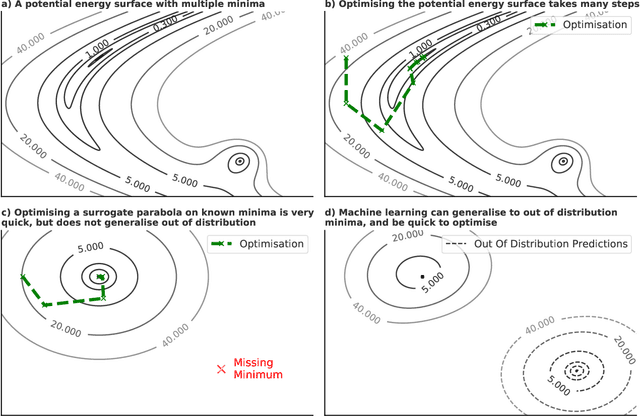
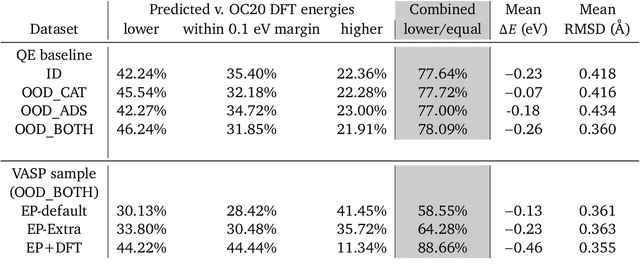
We present evidence that learned density functional theory (``DFT'') force fields are ready for ground state catalyst discovery. Our key finding is that relaxation using forces from a learned potential yields structures with similar or lower energy to those relaxed using the RPBE functional in over 50\% of evaluated systems, despite the fact that the predicted forces differ significantly from the ground truth. This has the surprising implication that learned potentials may be ready for replacing DFT in challenging catalytic systems such as those found in the Open Catalyst 2020 dataset. Furthermore, we show that a force field trained on a locally harmonic energy surface with the same minima as a target DFT energy is also able to find lower or similar energy structures in over 50\% of cases. This ``Easy Potential'' converges in fewer steps than a standard model trained on true energies and forces, which further accelerates calculations. Its success illustrates a key point: learned potentials can locate energy minima even when the model has high force errors. The main requirement for structure optimisation is simply that the learned potential has the correct minima. Since learned potentials are fast and scale linearly with system size, our results open the possibility of quickly finding ground states for large systems.
ASR4REAL: An extended benchmark for speech models
Oct 16, 2021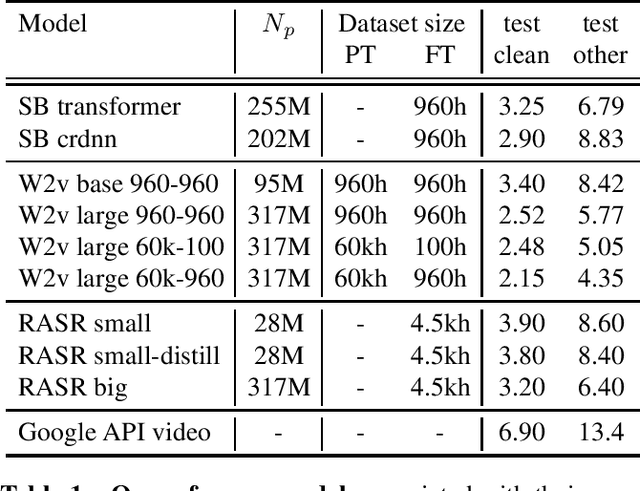
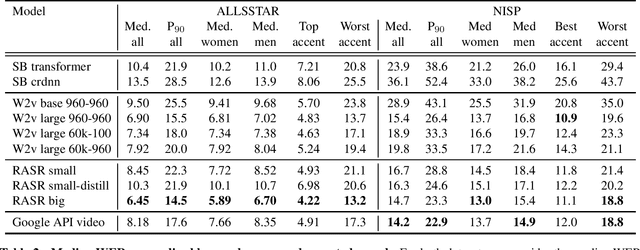
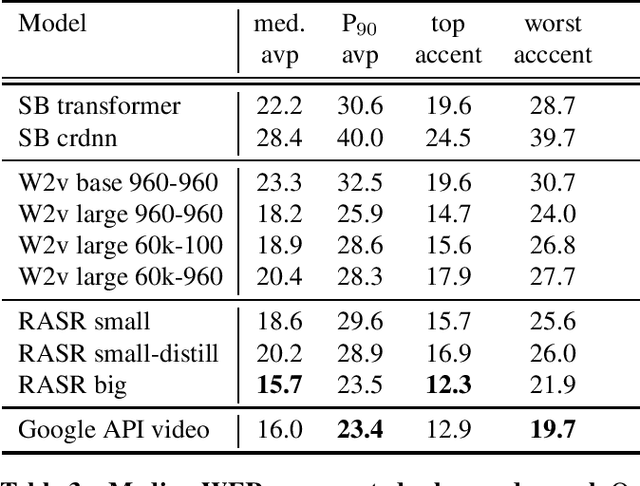
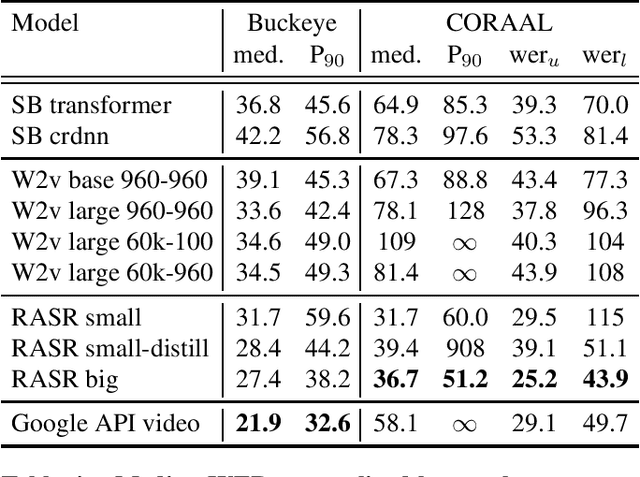
Popular ASR benchmarks such as Librispeech and Switchboard are limited in the diversity of settings and speakers they represent. We introduce a set of benchmarks matching real-life conditions, aimed at spotting possible biases and weaknesses in models. We have found out that even though recent models do not seem to exhibit a gender bias, they usually show important performance discrepancies by accent, and even more important ones depending on the socio-economic status of the speakers. Finally, all tested models show a strong performance drop when tested on conversational speech, and in this precise context even a language model trained on a dataset as big as Common Crawl does not seem to have significant positive effect which reiterates the importance of developing conversational language models
The Open Catalyst 2020 Dataset and Community Challenges
Oct 20, 2020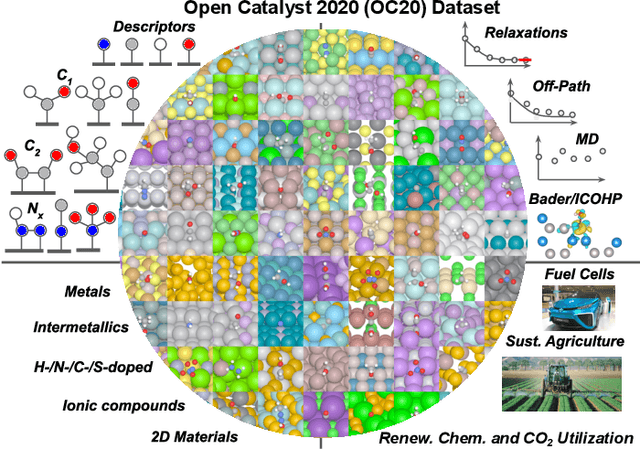

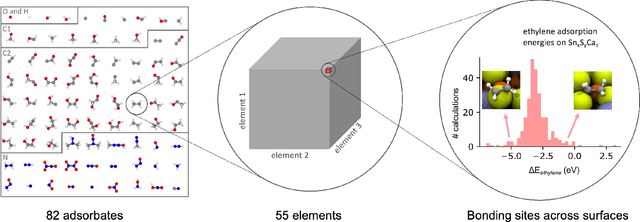
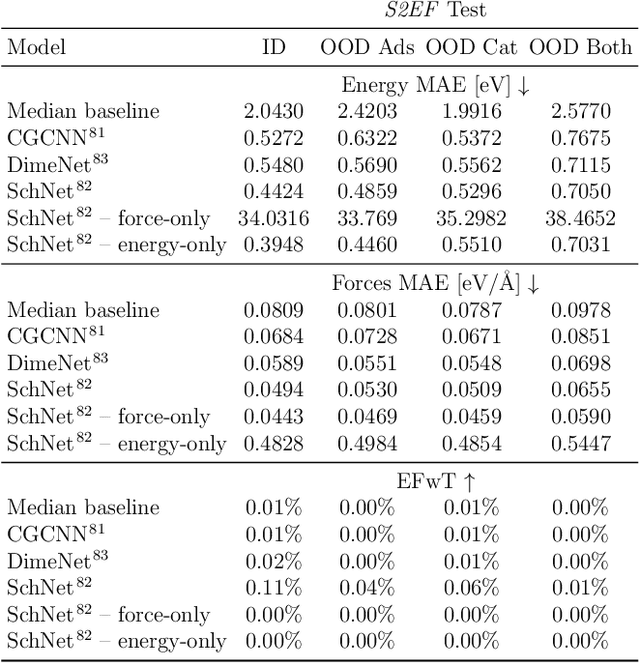
Catalyst discovery and optimization is key to solving many societal and energy challenges including solar fuels synthesis, long-term energy storage, and renewable fertilizer production. Despite considerable effort by the catalysis community to apply machine learning models to the computational catalyst discovery process, it remains an open challenge to build models that can generalize across both elemental compositions of surfaces and adsorbate identity/configurations, perhaps because datasets have been smaller in catalysis than related fields. To address this we developed the OC20 dataset, consisting of 1,281,121 Density Functional Theory (DFT) relaxations (264,900,500 single point evaluations) across a wide swath of materials, surfaces, and adsorbates (nitrogen, carbon, and oxygen chemistries). We supplemented this dataset with randomly perturbed structures, short timescale molecular dynamics, and electronic structure analyses. The dataset comprises three central tasks indicative of day-to-day catalyst modeling and comes with pre-defined train/validation/test splits to facilitate direct comparisons with future model development efforts. We applied three state-of-the-art graph neural network models (SchNet, Dimenet, CGCNN) to each of these tasks as baseline demonstrations for the community to build on. In almost every task, no upper limit on model size was identified, suggesting that even larger models are likely to improve on initial results. The dataset and baseline models are both provided as open resources, as well as a public leader board to encourage community contributions to solve these important tasks.
An Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020
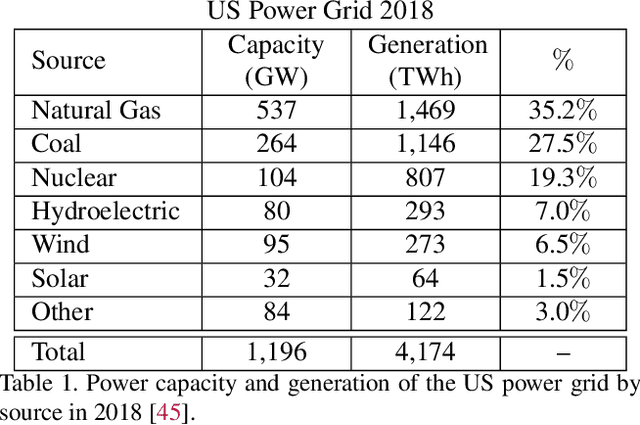
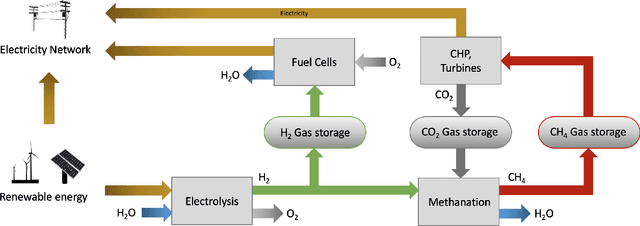
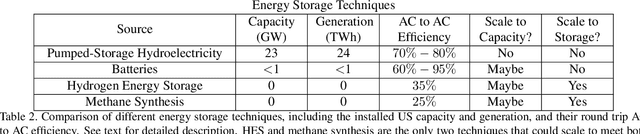
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.
Inspirational Adversarial Image Generation
Jun 17, 2019

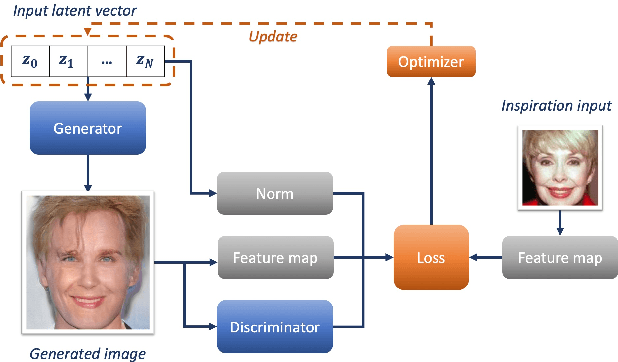
The task of image generation started to receive some attention from artists and designers to inspire them in new creations. However, exploiting the results of deep generative models such as Generative Adversarial Networks can be long and tedious given the lack of existing tools. In this work, we propose a simple strategy to inspire creators with new generations learned from a dataset of their choice, while providing some control on them. We design a simple optimization method to find the optimal latent parameters corresponding to the closest generation to any input inspirational image. Specifically, we allow the generation given an inspirational image of the user choice by performing several optimization steps to recover optimal parameters from the model's latent space. We tested several exploration methods starting with classic gradient descents to gradient-free optimizers. Many gradient-free optimizers just need comparisons (better/worse than another image), so that they can even be used without numerical criterion, without inspirational image, but with only with human preference. Thus, by iterating on one's preferences we could make robust Facial Composite or Fashion Generation algorithms. High resolution of the produced design generations are obtained using progressive growing of GANs. Our results on four datasets of faces, fashion images, and textures show that satisfactory images are effectively retrieved in most cases.
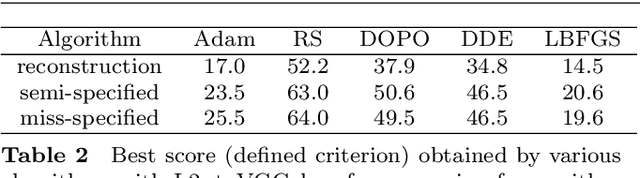
GDPP: Learning Diverse Generations Using Determinantal Point Process
Dec 05, 2018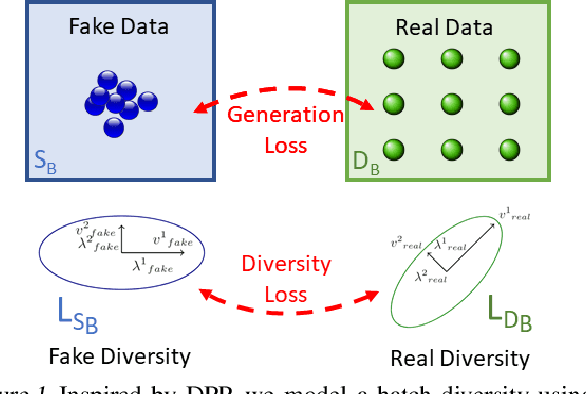
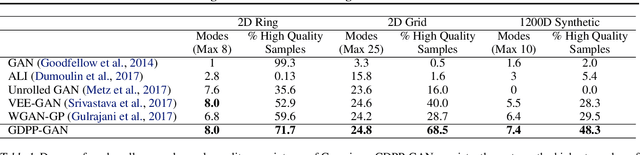
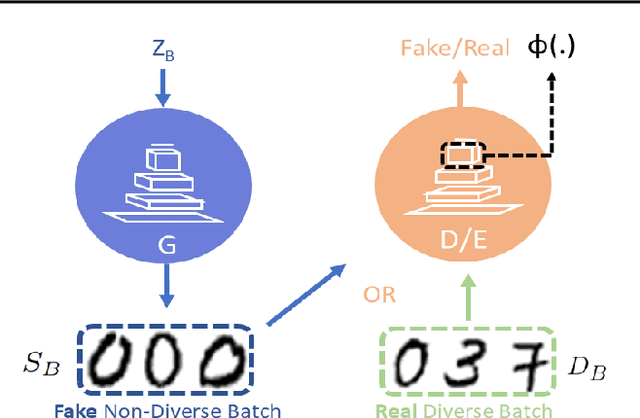
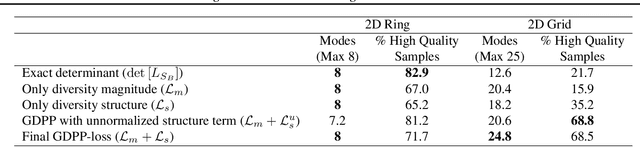
Generative models have proven to be an outstanding tool for representing high-dimensional probability distributions and generating realistic looking images. A fundamental characteristic of generative models is their ability to produce multi-modal outputs. However, while training, they are often susceptible to mode collapse, which means that the model is limited in mapping the input noise to only a few modes of the true data distribution. In this paper, we draw inspiration from Determinantal Point Process (DPP) to devise a generative model that alleviates mode collapse while producing higher quality samples. DPP is an elegant probabilistic measure used to model negative correlations within a subset and hence quantify its diversity. We use DPP kernel to model the diversity in real data as well as in synthetic data. Then, we devise a generation penalty term that encourages the generator to synthesize data with a similar diversity to real data. In contrast to previous state-of-the-art generative models that tend to use additional trainable parameters or complex training paradigms, our method does not change the original training scheme. Embedded in an adversarial training and variational autoencoder, our Generative DPP approach shows a consistent resistance to mode-collapse on a wide-variety of synthetic data and natural image datasets including MNIST, CIFAR10, and CelebA, while outperforming state-of-the-art methods for data-efficiency, convergence-time, and generation quality. Our code is publicly available.