 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024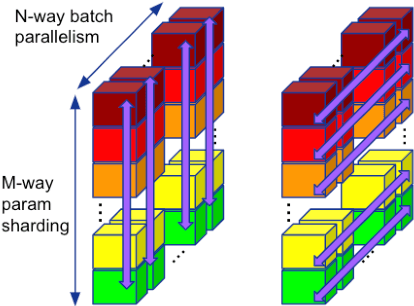
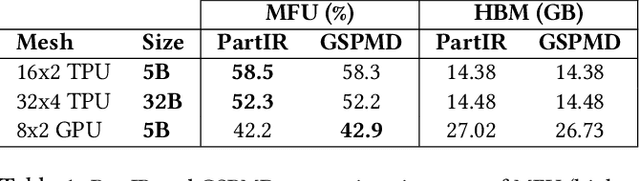
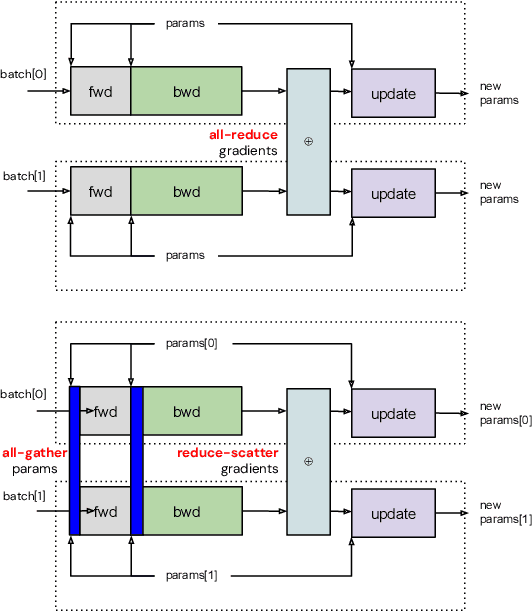
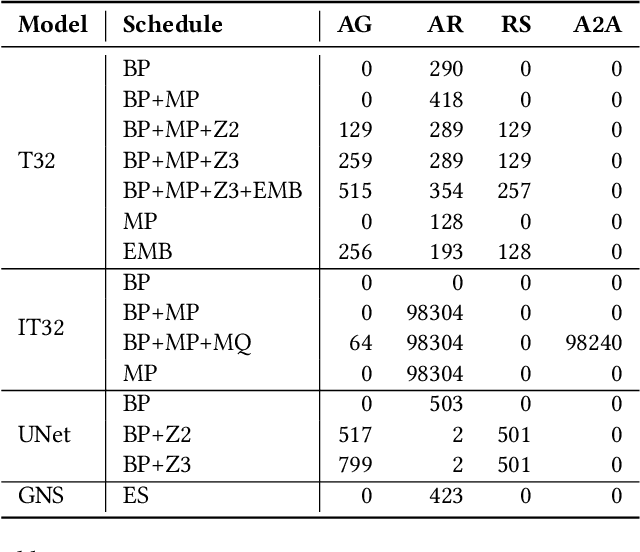
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Automatic Discovery of Composite SPMD Partitioning Strategies in PartIR
Oct 07, 2022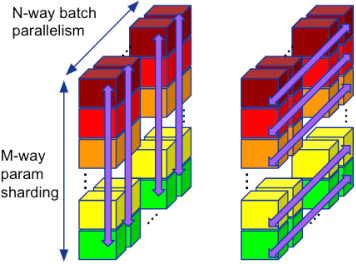


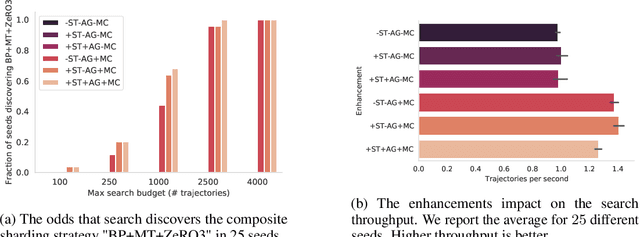
Large neural network models are commonly trained through a combination of advanced parallelism strategies in a single program, multiple data (SPMD) paradigm. For example, training large transformer models requires combining data, model, and pipeline partitioning; and optimizer sharding techniques. However, identifying efficient combinations for many model architectures and accelerator systems requires significant manual analysis. In this work, we present an automatic partitioner that identifies these combinations through a goal-oriented search. Our key findings are that a Monte Carlo Tree Search-based partitioner leveraging partition-specific compiler analysis directly into the search and guided goals matches expert-level strategies for various models.
Learned Force Fields Are Ready For Ground State Catalyst Discovery
Sep 26, 2022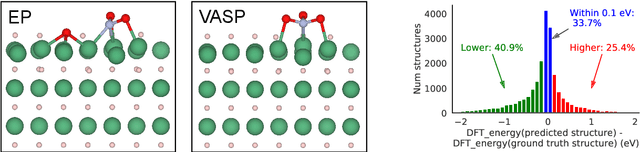
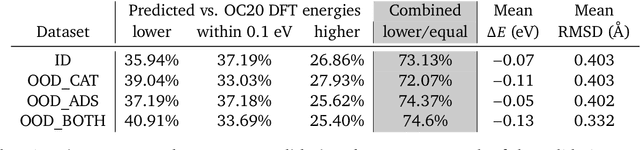
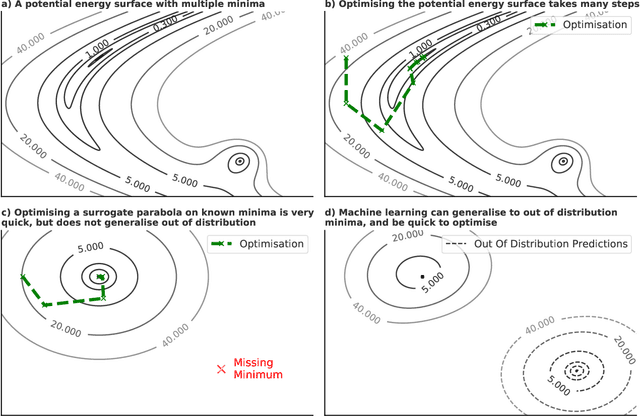
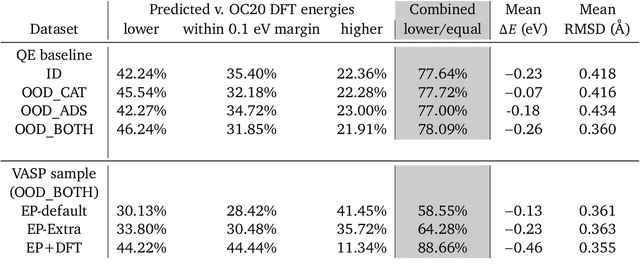
We present evidence that learned density functional theory (``DFT'') force fields are ready for ground state catalyst discovery. Our key finding is that relaxation using forces from a learned potential yields structures with similar or lower energy to those relaxed using the RPBE functional in over 50\% of evaluated systems, despite the fact that the predicted forces differ significantly from the ground truth. This has the surprising implication that learned potentials may be ready for replacing DFT in challenging catalytic systems such as those found in the Open Catalyst 2020 dataset. Furthermore, we show that a force field trained on a locally harmonic energy surface with the same minima as a target DFT energy is also able to find lower or similar energy structures in over 50\% of cases. This ``Easy Potential'' converges in fewer steps than a standard model trained on true energies and forces, which further accelerates calculations. Its success illustrates a key point: learned potentials can locate energy minima even when the model has high force errors. The main requirement for structure optimisation is simply that the learned potential has the correct minima. Since learned potentials are fast and scale linearly with system size, our results open the possibility of quickly finding ground states for large systems.
Pre-training via Denoising for Molecular Property Prediction
May 31, 2022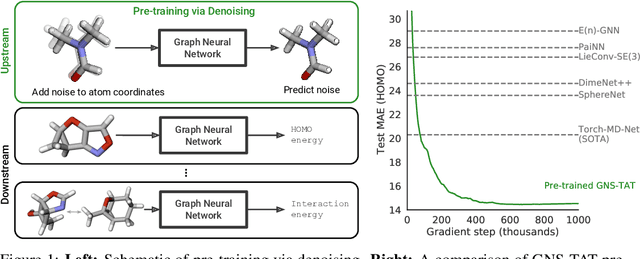
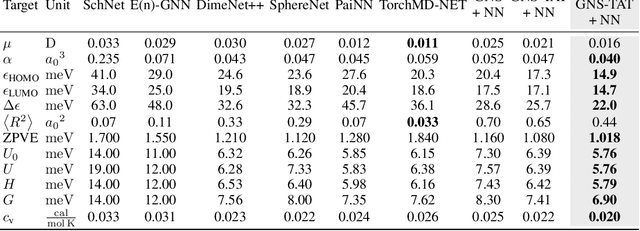
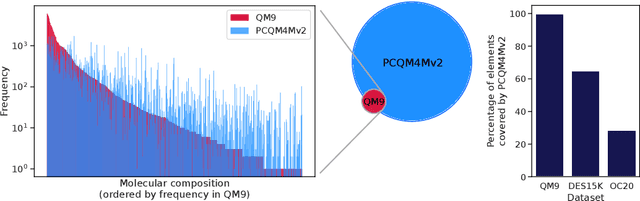
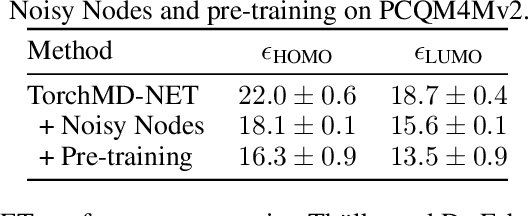
Many important problems involving molecular property prediction from 3D structures have limited data, posing a generalization challenge for neural networks. In this paper, we describe a pre-training technique that utilizes large datasets of 3D molecular structures at equilibrium to learn meaningful representations for downstream tasks. Inspired by recent advances in noise regularization, our pre-training objective is based on denoising. Relying on the well-known link between denoising autoencoders and score-matching, we also show that the objective corresponds to learning a molecular force field -- arising from approximating the physical state distribution with a mixture of Gaussians -- directly from equilibrium structures. Our experiments demonstrate that using this pre-training objective significantly improves performance on multiple benchmarks, achieving a new state-of-the-art on the majority of targets in the widely used QM9 dataset. Our analysis then provides practical insights into the effects of different factors -- dataset sizes, model size and architecture, and the choice of upstream and downstream datasets -- on pre-training.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021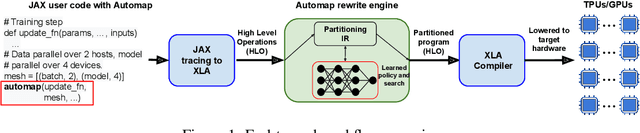
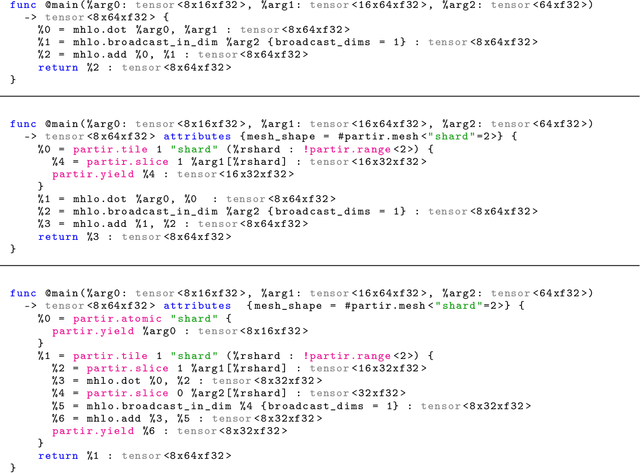


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.
Very Deep Graph Neural Networks Via Noise Regularisation
Jun 15, 2021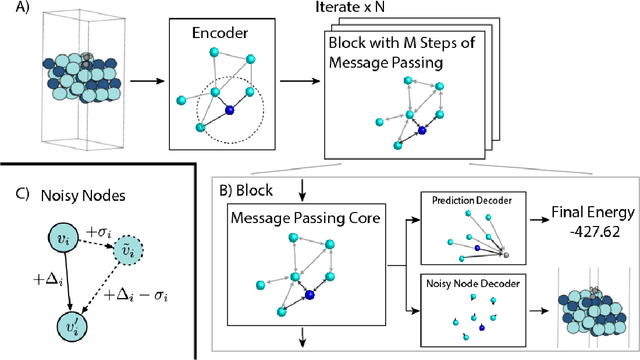
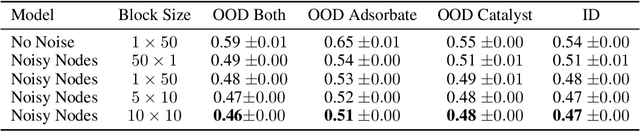
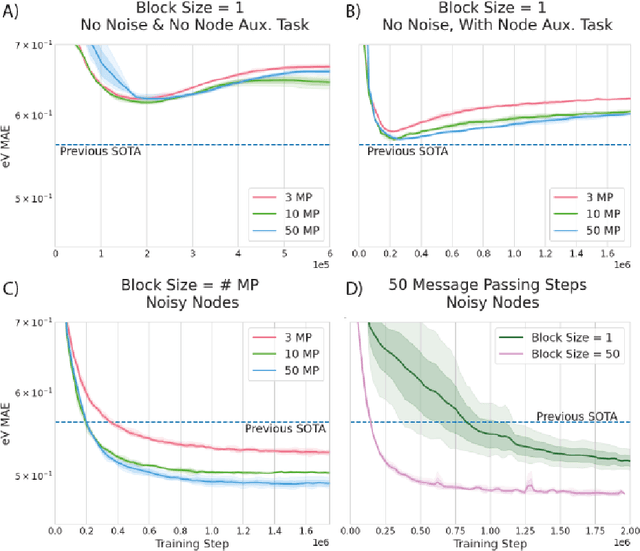
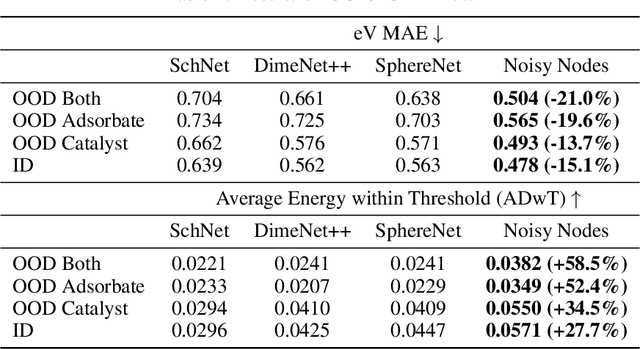
Graph Neural Networks (GNNs) perform learned message passing over an input graph, but conventional wisdom says performing more than handful of steps makes training difficult and does not yield improved performance. Here we show the contrary. We train a deep GNN with up to 100 message passing steps and achieve several state-of-the-art results on two challenging molecular property prediction benchmarks, Open Catalyst 2020 IS2RE and QM9. Our approach depends crucially on a novel but simple regularisation method, which we call ``Noisy Nodes'', in which we corrupt the input graph with noise and add an auxiliary node autoencoder loss if the task is graph property prediction. Our results show this regularisation method allows the model to monotonically improve in performance with increased message passing steps. Our work opens new opportunities for reaping the benefits of deep neural networks in the space of graph and other structured prediction problems.
Learning Index Selection with Structured Action Spaces
Sep 16, 2019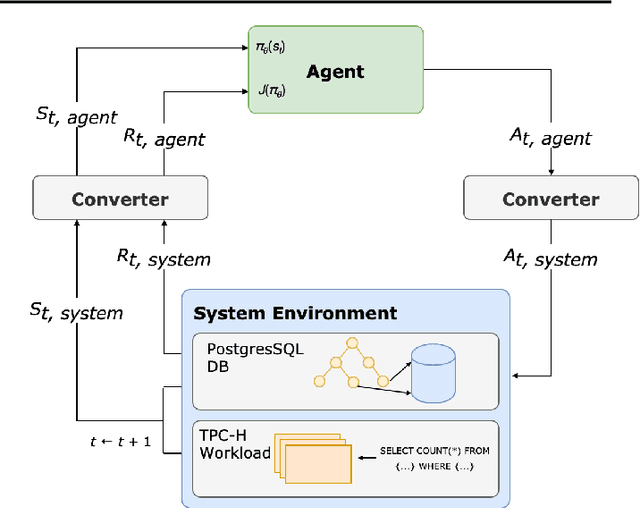

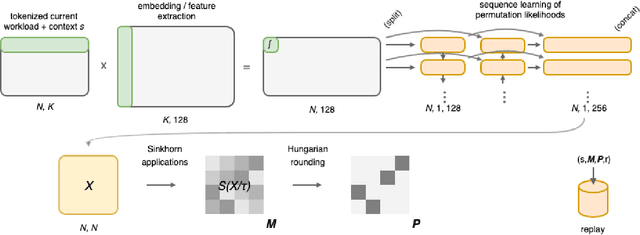
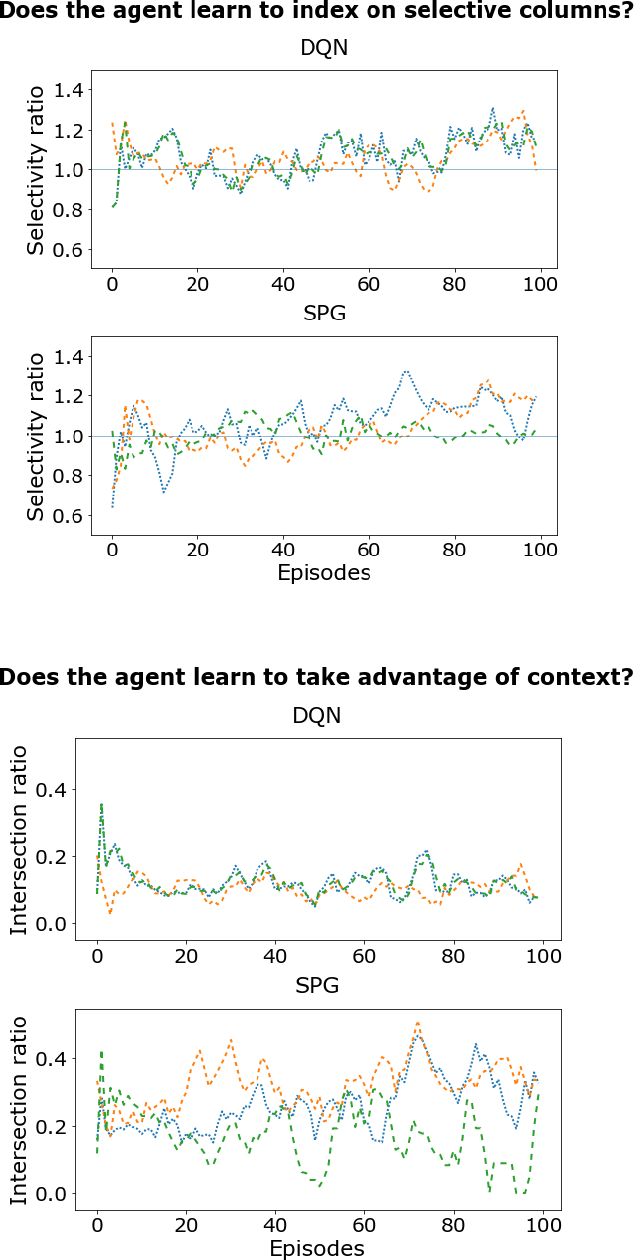
Configuration spaces for computer systems can be challenging for traditional and automatic tuning strategies. Injecting task-specific knowledge into the tuner for a task may allow for more efficient exploration of candidate configurations. We apply this idea to the task of index set selection to accelerate database workloads. Index set selection has been amenable to recent applications of vanilla deep RL, but real deployments remain out of reach. In this paper, we explore how learning index selection can be enhanced with task-specific inductive biases, specifically by encoding these inductive biases in better action structures. Index selection-specific action representations arise when the problem is reformulated in terms of permutation learning and we rely on recent work for learning RL policies on permutations. Through this approach, we build an indexing agent that is able to achieve improved indexing and validate its behavior with task-specific statistics. Early experiments reveal that our agent can find configurations that are up to 40% smaller for the same levels of latency as compared with other approaches and indicate more intuitive indexing behavior.
Wield: Systematic Reinforcement Learning With Progressive Randomization
Sep 15, 2019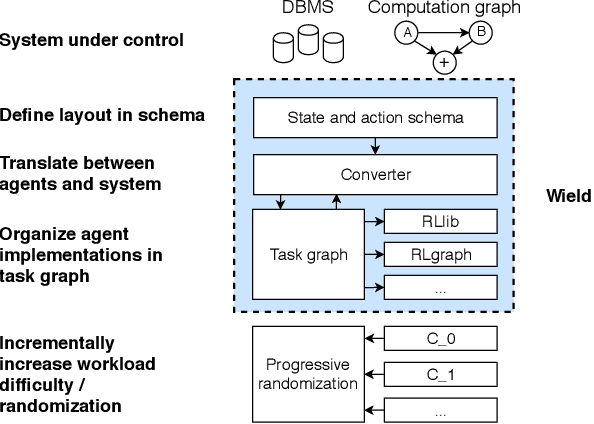
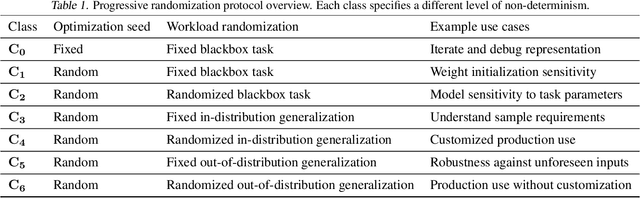

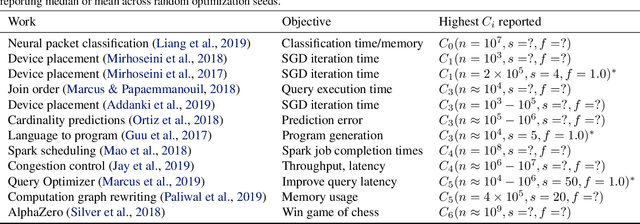
Reinforcement learning frameworks have introduced abstractions to implement and execute algorithms at scale. They assume standardized simulator interfaces but are not concerned with identifying suitable task representations. We present Wield, a first-of-its kind system to facilitate task design for practical reinforcement learning. Through software primitives, Wield enables practitioners to decouple system-interface and deployment-specific configuration from state and action design. To guide experimentation, Wield further introduces a novel task design protocol and classification scheme centred around staged randomization to incrementally evaluate model capabilities.
RLgraph: Flexible Computation Graphs for Deep Reinforcement Learning
Oct 21, 2018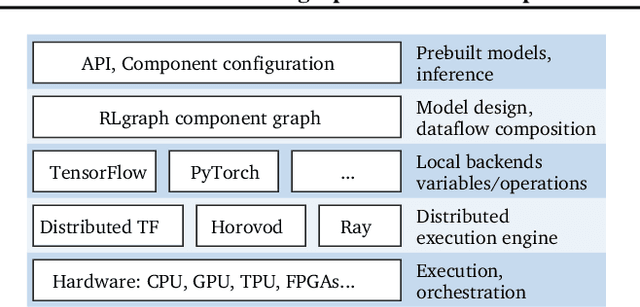
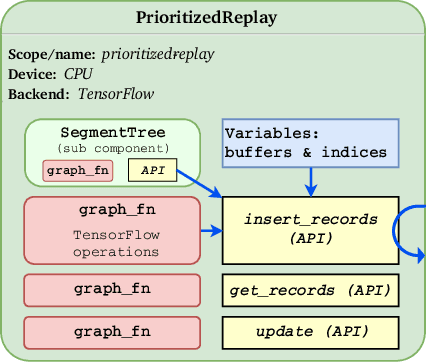

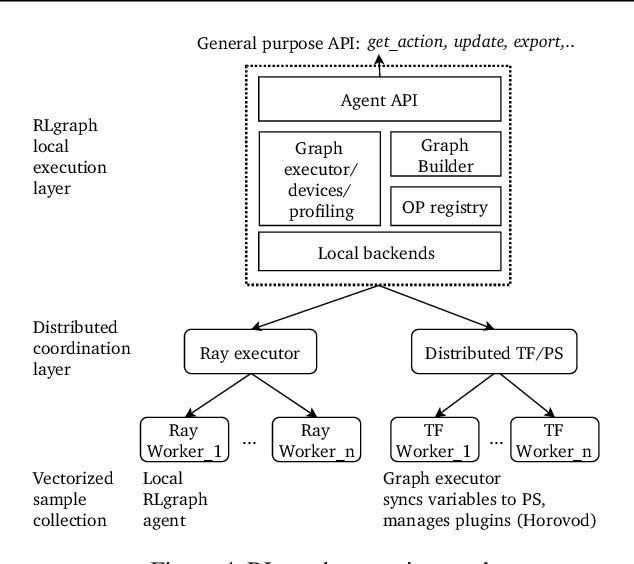
Reinforcement learning (RL) tasks are challenging to implement, execute and test due to algorithmic instability, hyper-parameter sensitivity, and heterogeneous distributed communication patterns. We argue for the separation of logical component composition, backend graph definition, and distributed execution. To this end, we introduce RLgraph, a library for designing and executing high performance RL computation graphs in both static graph and define-by-run paradigms. The resulting implementations yield high performance across different deep learning frameworks and distributed backends.
LIFT: Reinforcement Learning in Computer Systems by Learning From Demonstrations
Aug 23, 2018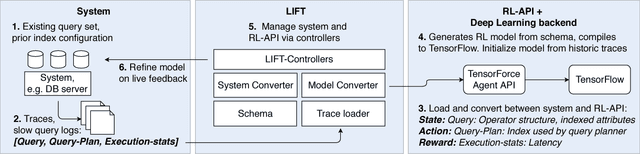

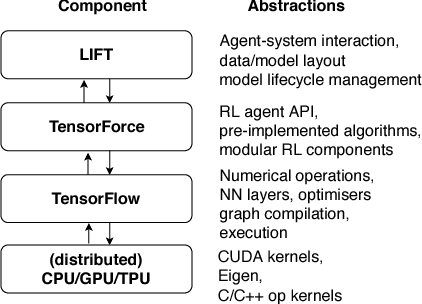
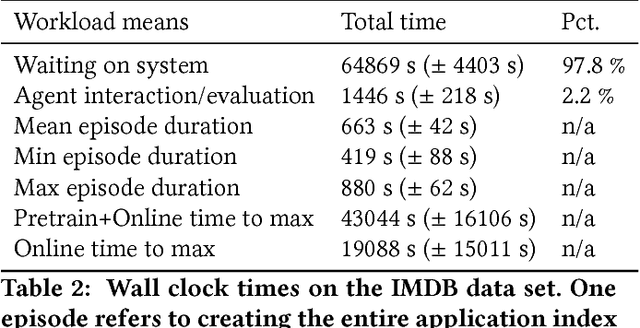
Reinforcement learning approaches have long appealed to the data management community due to their ability to learn to control dynamic behavior from raw system performance. Recent successes in combining deep neural networks with reinforcement learning have sparked significant new interest in this domain. However, practical solutions remain elusive due to large training data requirements, algorithmic instability, and lack of standard tools. In this work, we introduce LIFT, an end-to-end software stack for applying deep reinforcement learning to data management tasks. While prior work has frequently explored applications in simulations, LIFT centers on utilizing human expertise to learn from demonstrations, thus lowering online training times. We further introduce TensorForce, a TensorFlow library for applied deep reinforcement learning exposing a unified declarative interface to common RL algorithms, thus providing a backend to LIFT. We demonstrate the utility of LIFT in two case studies in database compound indexing and resource management in stream processing. Results show LIFT controllers initialized from demonstrations can outperform human baselines and heuristics across latency metrics and space usage by up to 70%.