 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
PartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024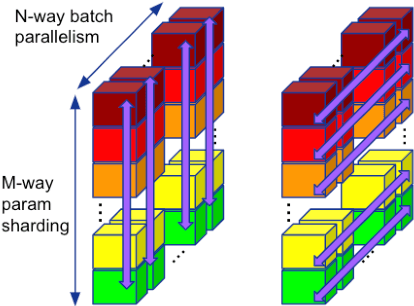
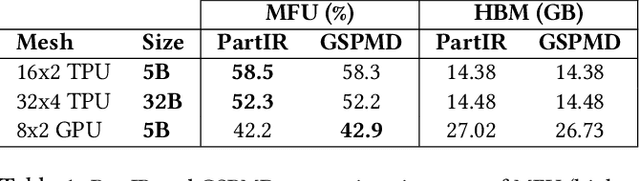
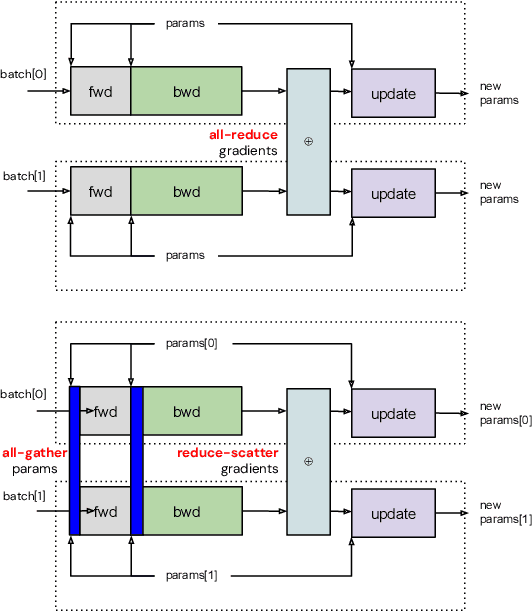
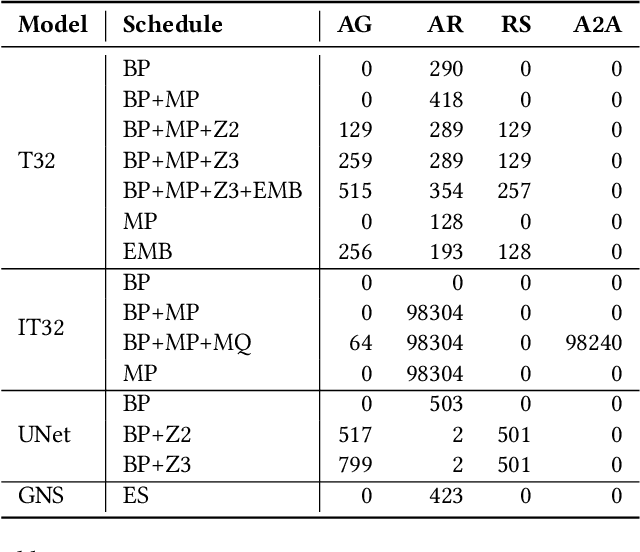
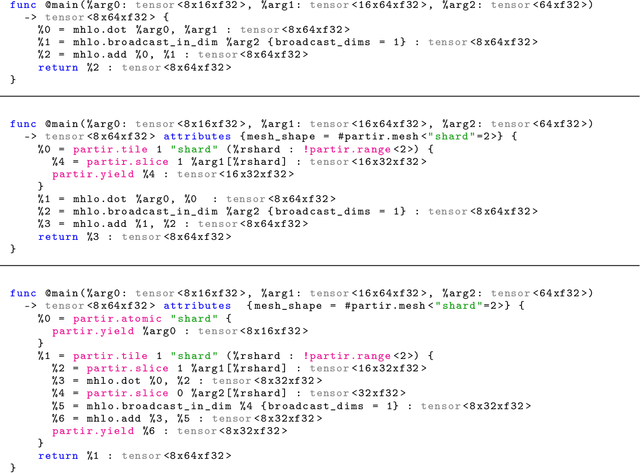
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021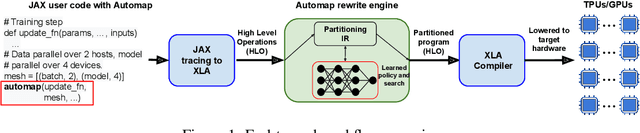


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.