 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
PartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024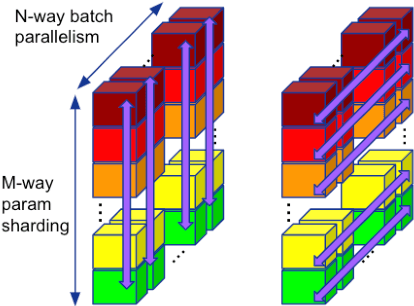
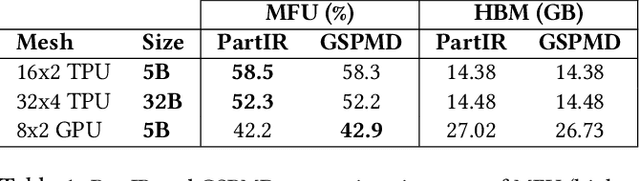
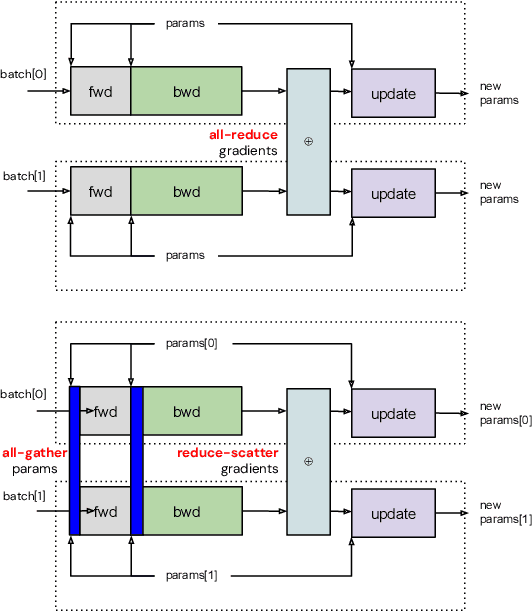
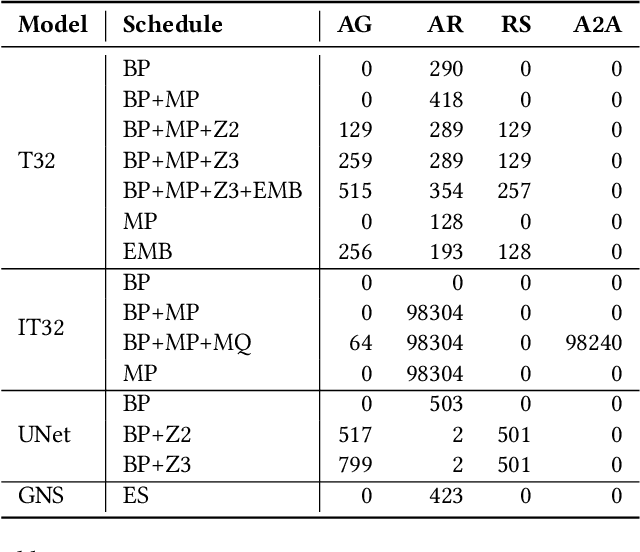
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021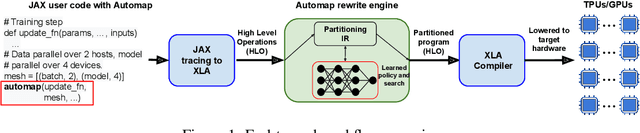
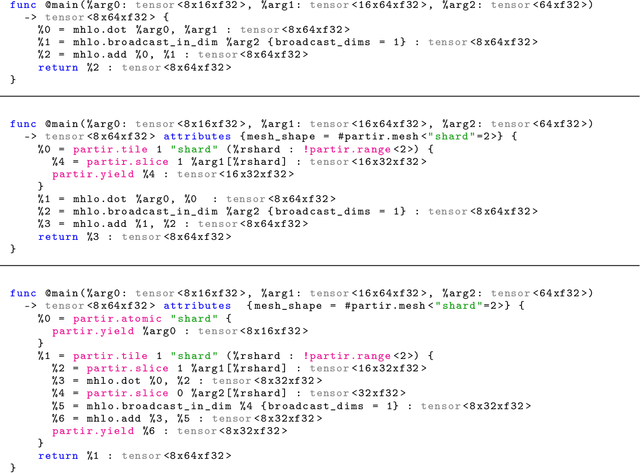


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.
Memory-efficient array redistribution through portable collective communication
Dec 02, 2021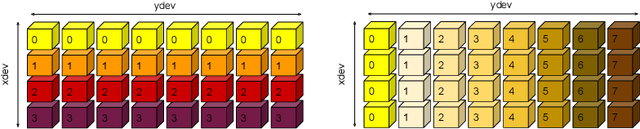
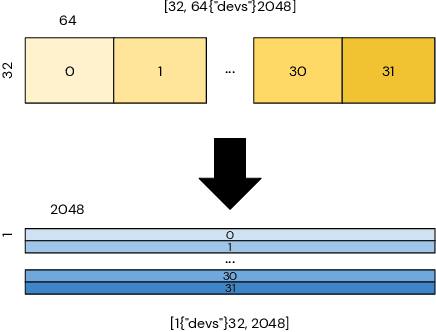
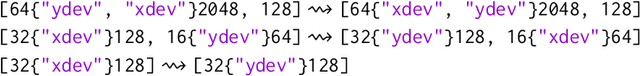

Modern large-scale deep learning workloads highlight the need for parallel execution across many devices in order to fit model data into hardware accelerator memories. In these settings, array redistribution may be required during a computation, but can also become a bottleneck if not done efficiently. In this paper we address the problem of redistributing multi-dimensional array data in SPMD computations, the most prevalent form of parallelism in deep learning. We present a type-directed approach to synthesizing array redistributions as sequences of MPI-style collective operations. We prove formally that our synthesized redistributions are memory-efficient and perform no excessive data transfers. Array redistribution for SPMD computations using collective operations has also been implemented in the context of the XLA SPMD partitioner, a production-grade tool for partitioning programs across accelerator systems. We evaluate our approach against the XLA implementation and find that our approach delivers a geometric mean speedup of $1.22\times$, with maximum speedups as a high as $5.7\times$, while offering provable memory guarantees, making our system particularly appealing for large-scale models.
Decomposing reverse-mode automatic differentiation
May 20, 2021We decompose reverse-mode automatic differentiation into (forward-mode) linearization followed by transposition. Doing so isolates the essential difference between forward- and reverse-mode AD, and simplifies their joint implementation. In particular, once forward-mode AD rules are defined for every primitive operation in a source language, only linear primitives require an additional transposition rule in order to arrive at a complete reverse-mode AD implementation. This is how reverse-mode AD is written in JAX and Dex.
Tensors Fitting Perfectly
Feb 26, 2021
Multidimensional arrays (NDArrays) are a central abstraction in modern scientific computing environments. Unfortunately, they can make reasoning about programs harder as the number of different array shapes used in an execution of a program is usually very large, and they rarely appear explicitly in program text. To make things worse, many operators make implicit assumptions about the shapes of their inputs: array addition is commonly enriched with broadcasting semantics, while matrix multiplication assumes that the lengths of contracted dimensions are equal. Because precise reasoning about shapes is crucial to write correct programs using NDArrays, and because shapes are often hard to infer from a quick glance at the program, we developed Tensors Fitting Perfectly, a static analysis tool that reasons about NDArray shapes in Swift for TensorFlow programs by synthesizing a set of shape constraints from an abstract interpretation of the program. It can both (1) check for possible inconsistencies, and (2) provide direct insights about the shapes of intermediate values appearing in the program, including via a mechanism called shape holes. The static analysis works in concert with optional runtime assertions to improve the productivity of program authors.
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Jun 28, 2020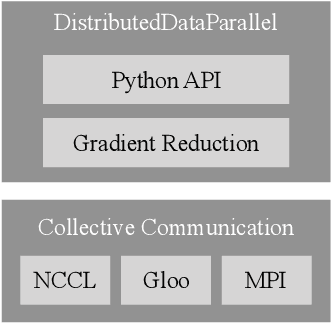
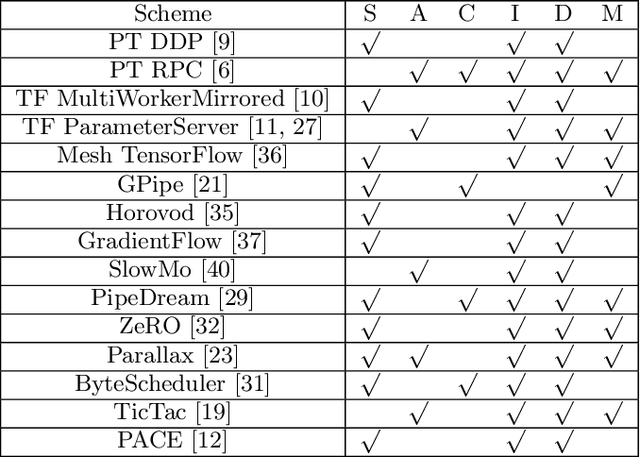
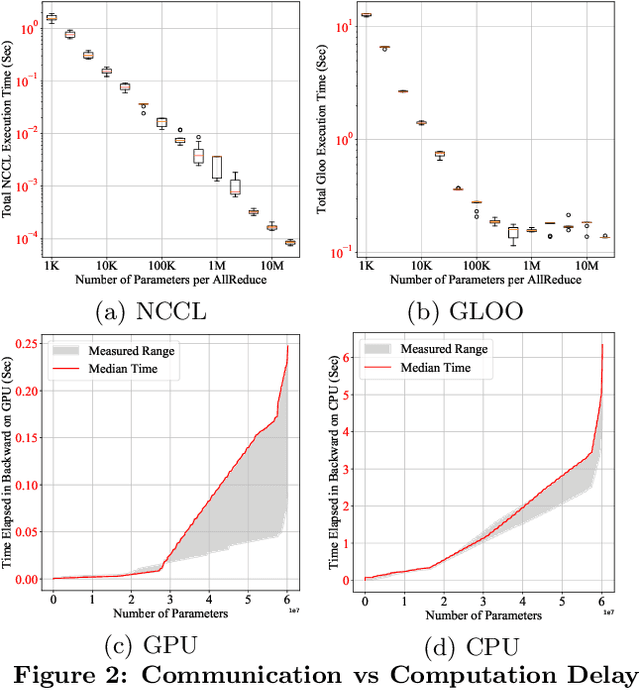
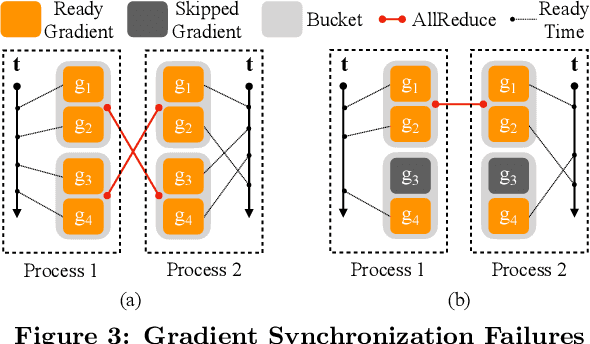
This paper presents the design, implementation, and evaluation of the PyTorch distributed data parallel module. PyTorch is a widely-adopted scientific computing package used in deep learning research and applications. Recent advances in deep learning argue for the value of large datasets and large models, which necessitates the ability to scale out model training to more computational resources. Data parallelism has emerged as a popular solution for distributed training thanks to its straightforward principle and broad applicability. In general, the technique of distributed data parallelism replicates the model on every computational resource to generate gradients independently and then communicates those gradients at each iteration to keep model replicas consistent. Despite the conceptual simplicity of the technique, the subtle dependencies between computation and communication make it non-trivial to optimize the distributed training efficiency. As of v1.5, PyTorch natively provides several techniques to accelerate distributed data parallel, including bucketing gradients, overlapping computation with communication, and skipping gradient synchronization. Evaluations show that, when configured appropriately, the PyTorch distributed data parallel module attains near-linear scalability using 256 GPUs.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019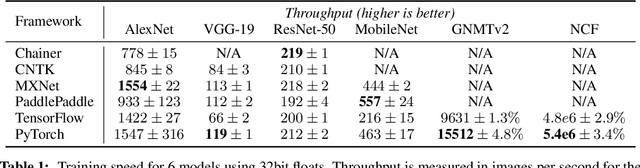

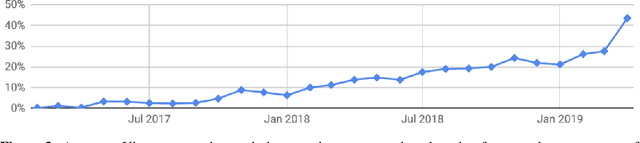
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.