 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs with Fault Tolerant HSDP on 100,000 GPUs
Jan 30, 2026Large-scale training systems typically use synchronous training, requiring all GPUs to be healthy simultaneously. In our experience training on O(100K) GPUs, synchronous training results in a low efficiency due to frequent failures and long recovery time. To address this problem, we propose a novel training paradigm, Fault Tolerant Hybrid-Shared Data Parallelism (FT-HSDP). FT-HSDP uses data parallel replicas as units of fault tolerance. When failures occur, only a single data-parallel replica containing the failed GPU or server is taken offline and restarted, while the other replicas continue training. To realize this idea at scale, FT-HSDP incorporates several techniques: 1) We introduce a Fault Tolerant All Reduce (FTAR) protocol for gradient exchange across data parallel replicas. FTAR relies on the CPU to drive the complex control logic for tasks like adding or removing participants dynamically, and relies on GPU to perform data transfer for best performance. 2) We introduce a non-blocking catch-up protocol, allowing a recovering replica to join training with minimal stall. Compared with fully synchronous training at O(100K) GPUs, FT-HSDP can reduce the stall time due to failure recovery from 10 minutes to 3 minutes, increasing effective training time from 44\% to 80\%. We further demonstrate that FT-HSDP's asynchronous recovery does not bring any meaning degradation to the accuracy of the result model.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Jun 28, 2020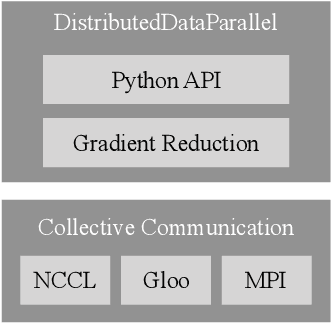
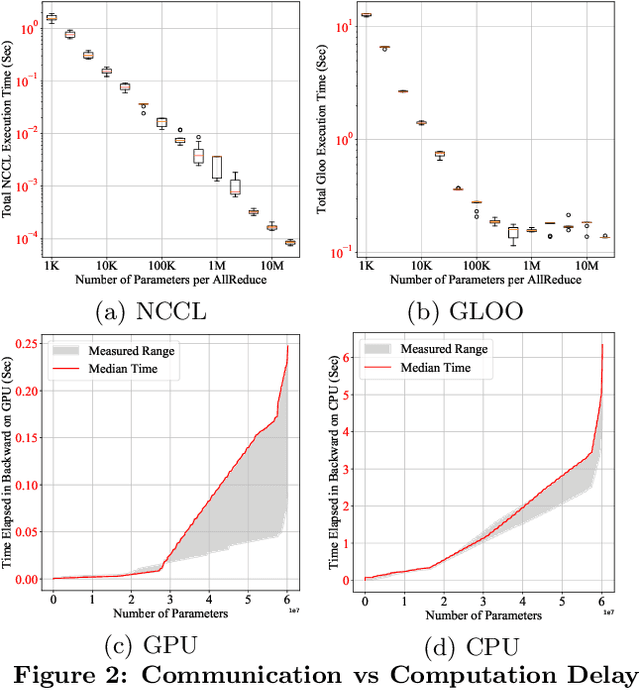
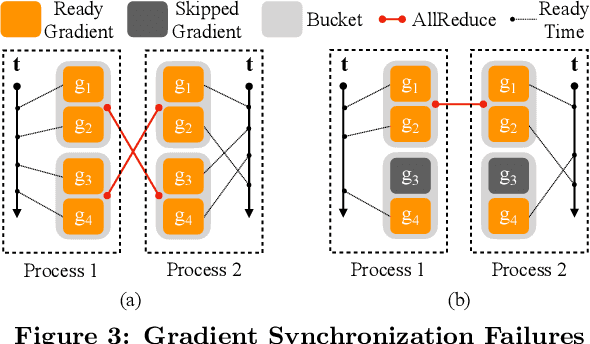
This paper presents the design, implementation, and evaluation of the PyTorch distributed data parallel module. PyTorch is a widely-adopted scientific computing package used in deep learning research and applications. Recent advances in deep learning argue for the value of large datasets and large models, which necessitates the ability to scale out model training to more computational resources. Data parallelism has emerged as a popular solution for distributed training thanks to its straightforward principle and broad applicability. In general, the technique of distributed data parallelism replicates the model on every computational resource to generate gradients independently and then communicates those gradients at each iteration to keep model replicas consistent. Despite the conceptual simplicity of the technique, the subtle dependencies between computation and communication make it non-trivial to optimize the distributed training efficiency. As of v1.5, PyTorch natively provides several techniques to accelerate distributed data parallel, including bucketing gradients, overlapping computation with communication, and skipping gradient synchronization. Evaluations show that, when configured appropriately, the PyTorch distributed data parallel module attains near-linear scalability using 256 GPUs.