 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANEval: Open-Vocabulary Compositional Benchmarks with Failure-mode Diagnosis
Jan 30, 2026The rapid progress of text-to-image (T2I) models has unlocked unprecedented creative potential, yet their ability to faithfully render complex prompts involving multiple objects, attributes, and spatial relationships remains a significant bottleneck. Progress is hampered by a lack of adequate evaluation methods; current benchmarks are often restricted to closed-set vocabularies, lack fine-grained diagnostic capabilities, and fail to provide the interpretable feedback necessary to diagnose and remedy specific compositional failures. We solve these challenges by introducing SANEval (Spatial, Attribute, and Numeracy Evaluation), a comprehensive benchmark that establishes a scalable new pipeline for open-vocabulary compositional evaluation. SANEval combines a large language model (LLM) for deep prompt understanding with an LLM-enhanced, open-vocabulary object detector to robustly evaluate compositional adherence, unconstrained by a fixed vocabulary. Through extensive experiments on six state-of-the-art T2I models, we demonstrate that SANEval's automated evaluations provide a more faithful proxy for human assessment; our metric achieves a Spearman's rank correlation with statistically different results than those of existing benchmarks across tasks of attribute binding, spatial relations, and numeracy. To facilitate future research in compositional T2I generation and evaluation, we will release the SANEval dataset and our open-source evaluation pipeline.
SHARe-KAN: Holographic Vector Quantization for Memory-Bound Inference
Dec 10, 2025Kolmogorov-Arnold Networks (KANs) face a fundamental memory wall: their learned basis functions create parameter counts that impose extreme bandwidth demands, hindering deployment in memory-constrained environments. We show that Vision KANs exhibit a holographic topology, where information is distributed across the interference of splines rather than localized to specific edges. Consequently, traditional pruning fails (10% sparsity degrades mAP from 85.23% to 45%, a $\sim$40-point drop). To address this, we present SHARe-KAN, a framework utilizing Gain-Shape-Bias Vector Quantization to exploit functional redundancy while preserving the dense topology. Coupled with LUTHAM, a hardware-aware compiler with static memory planning, we achieve $88\times$ runtime memory reduction (1.13 GB $\to$ 12.91 MB) and match uncompressed baseline accuracy on PASCAL VOC. Profiling on NVIDIA Ampere architecture confirms $>90\%$ L2 cache residency, demonstrating that the workload is decoupled from DRAM bandwidth constraints inherent to spline-based architectures.
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Jun 28, 2020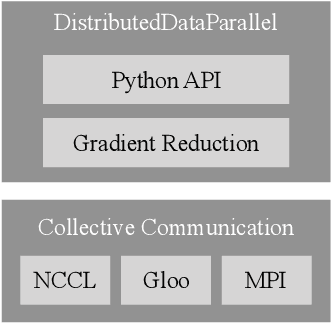
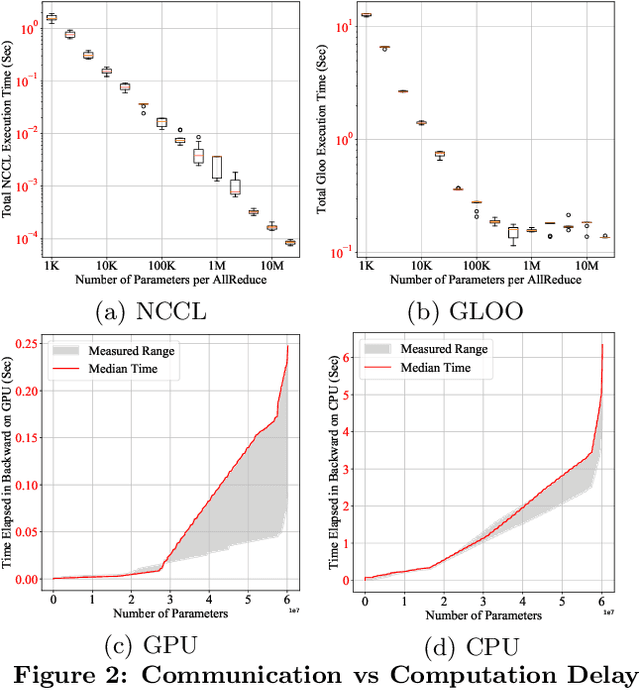
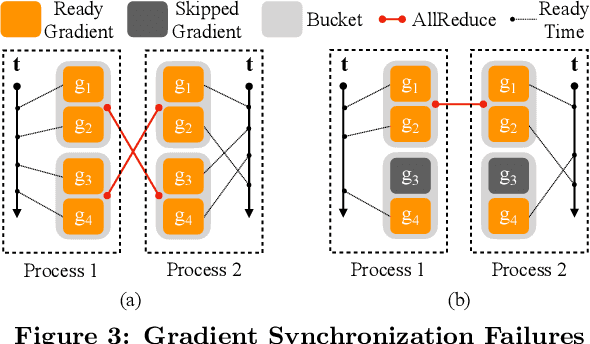
This paper presents the design, implementation, and evaluation of the PyTorch distributed data parallel module. PyTorch is a widely-adopted scientific computing package used in deep learning research and applications. Recent advances in deep learning argue for the value of large datasets and large models, which necessitates the ability to scale out model training to more computational resources. Data parallelism has emerged as a popular solution for distributed training thanks to its straightforward principle and broad applicability. In general, the technique of distributed data parallelism replicates the model on every computational resource to generate gradients independently and then communicates those gradients at each iteration to keep model replicas consistent. Despite the conceptual simplicity of the technique, the subtle dependencies between computation and communication make it non-trivial to optimize the distributed training efficiency. As of v1.5, PyTorch natively provides several techniques to accelerate distributed data parallel, including bucketing gradients, overlapping computation with communication, and skipping gradient synchronization. Evaluations show that, when configured appropriately, the PyTorch distributed data parallel module attains near-linear scalability using 256 GPUs.