 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCDNet: Learning to Detect Camouflage against Distractors in Infrared Small Target Detection
Mar 31, 2026Infrared target detection (IRSTD) tasks have critical applications in areas like wilderness rescue and maritime search. However, detecting infrared targets is challenging due to their low contrast and tendency to blend into complex backgrounds, effectively camouflaging themselves. Additionally, other objects with similar features (distractors) can cause false alarms, further degrading detection performance. To address these issues, we propose a novel \textbf{C}amouflage-aware \textbf{C}ounter-\textbf{D}istraction \textbf{Net}work (CCDNet) in this paper. We design a backbone with Weighted Multi-branch Perceptrons (WMPs), which aggregates self-conditioned multi-level features to accurately represent the target and background. Based on these rich features, we then propose a novel Aggregation-and-Refinement Fusion Neck (ARFN) to refine structures/semantics from shallow/deep features maps, and bidirectionally reconstruct the relations between the targets and the backgrounds, highlighting the targets while suppressing the complex backgrounds to improve detection accuracy. Furthermore, we present a new Contrastive-aided Distractor Discriminator (CaDD), enforcing adaptive similarity computation both locally and globally between the real targets and the backgrounds to more precisely discriminate distractors, so as to reduce the false alarm rate. Extensive experiments on infrared image datasets confirm that CCDNet outperforms other state-of-the-art methods.
SANEval: Open-Vocabulary Compositional Benchmarks with Failure-mode Diagnosis
Jan 30, 2026The rapid progress of text-to-image (T2I) models has unlocked unprecedented creative potential, yet their ability to faithfully render complex prompts involving multiple objects, attributes, and spatial relationships remains a significant bottleneck. Progress is hampered by a lack of adequate evaluation methods; current benchmarks are often restricted to closed-set vocabularies, lack fine-grained diagnostic capabilities, and fail to provide the interpretable feedback necessary to diagnose and remedy specific compositional failures. We solve these challenges by introducing SANEval (Spatial, Attribute, and Numeracy Evaluation), a comprehensive benchmark that establishes a scalable new pipeline for open-vocabulary compositional evaluation. SANEval combines a large language model (LLM) for deep prompt understanding with an LLM-enhanced, open-vocabulary object detector to robustly evaluate compositional adherence, unconstrained by a fixed vocabulary. Through extensive experiments on six state-of-the-art T2I models, we demonstrate that SANEval's automated evaluations provide a more faithful proxy for human assessment; our metric achieves a Spearman's rank correlation with statistically different results than those of existing benchmarks across tasks of attribute binding, spatial relations, and numeracy. To facilitate future research in compositional T2I generation and evaluation, we will release the SANEval dataset and our open-source evaluation pipeline.
ASBA: A-line State Space Model and B-line Attention for Sparse Optical Doppler Tomography Reconstruction
Jan 20, 2026Optical Doppler Tomography (ODT) is an emerging blood flow analysis technique. A 2D ODT image (B-scan) is generated by sequentially acquiring 1D depth-resolved raw A-scans (A-line) along the lateral axis (B-line), followed by Doppler phase-subtraction analysis. To ensure high-fidelity B-scan images, current practices rely on dense sampling, which prolongs scanning time, increases storage demands, and limits the capture of rapid blood flow dynamics. Recent studies have explored sparse sampling of raw A-scans to alleviate these limitations, but their effectiveness is hindered by the conservative sampling rates and the uniform modeling of flow and background signals. In this study, we introduce a novel blood flow-aware network, named ASBA (A-line ROI State space model and B-line phase Attention), to reconstruct ODT images from highly sparsely sampled raw A-scans. Specifically, we propose an A-line ROI state space model to extract sparsely distributed flow features along the A-line, and a B-line phase attention to capture long-range flow signals along each B-line based on phase difference. Moreover, we introduce a flow-aware weighted loss function that encourages the network to prioritize the accurate reconstruction of flow signals. Extensive experiments on real animal data demonstrate that the proposed approach clearly outperforms existing state-of-the-art reconstruction methods.
Beyond Words: Multimodal LLM Knows When to Speak
May 20, 2025While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
Distilling semantically aware orders for autoregressive image generation
Apr 23, 2025Autoregressive patch-based image generation has recently shown competitive results in terms of image quality and scalability. It can also be easily integrated and scaled within Vision-Language models. Nevertheless, autoregressive models require a defined order for patch generation. While a natural order based on the dictation of the words makes sense for text generation, there is no inherent generation order that exists for image generation. Traditionally, a raster-scan order (from top-left to bottom-right) guides autoregressive image generation models. In this paper, we argue that this order is suboptimal, as it fails to respect the causality of the image content: for instance, when conditioned on a visual description of a sunset, an autoregressive model may generate clouds before the sun, even though the color of clouds should depend on the color of the sun and not the inverse. In this work, we show that first by training a model to generate patches in any-given-order, we can infer both the content and the location (order) of each patch during generation. Secondly, we use these extracted orders to finetune the any-given-order model to produce better-quality images. Through our experiments, we show on two datasets that this new generation method produces better images than the traditional raster-scan approach, with similar training costs and no extra annotations.
SemiDAViL: Semi-supervised Domain Adaptation with Vision-Language Guidance for Semantic Segmentation
Apr 08, 2025



Domain Adaptation (DA) and Semi-supervised Learning (SSL) converge in Semi-supervised Domain Adaptation (SSDA), where the objective is to transfer knowledge from a source domain to a target domain using a combination of limited labeled target samples and abundant unlabeled target data. Although intuitive, a simple amalgamation of DA and SSL is suboptimal in semantic segmentation due to two major reasons: (1) previous methods, while able to learn good segmentation boundaries, are prone to confuse classes with similar visual appearance due to limited supervision; and (2) skewed and imbalanced training data distribution preferring source representation learning whereas impeding from exploring limited information about tailed classes. Language guidance can serve as a pivotal semantic bridge, facilitating robust class discrimination and mitigating visual ambiguities by leveraging the rich semantic relationships encoded in pre-trained language models to enhance feature representations across domains. Therefore, we propose the first language-guided SSDA setting for semantic segmentation in this work. Specifically, we harness the semantic generalization capabilities inherent in vision-language models (VLMs) to establish a synergistic framework within the SSDA paradigm. To address the inherent class-imbalance challenges in long-tailed distributions, we introduce class-balanced segmentation loss formulations that effectively regularize the learning process. Through extensive experimentation across diverse domain adaptation scenarios, our approach demonstrates substantial performance improvements over contemporary state-of-the-art (SoTA) methodologies. Code is available: \href{https://github.com/hritam-98/SemiDAViL}{GitHub}.
Enhancing Single Image to 3D Generation using Gaussian Splatting and Hybrid Diffusion Priors
Oct 12, 2024
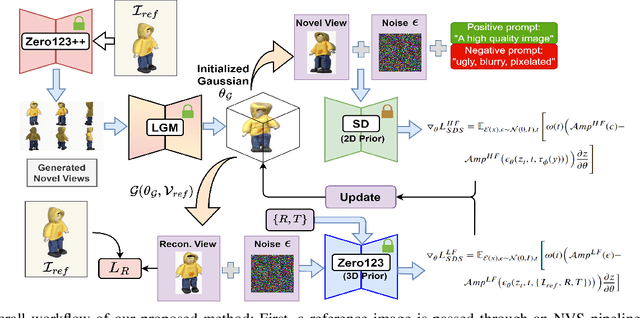
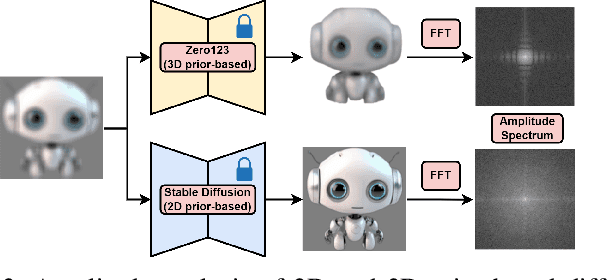
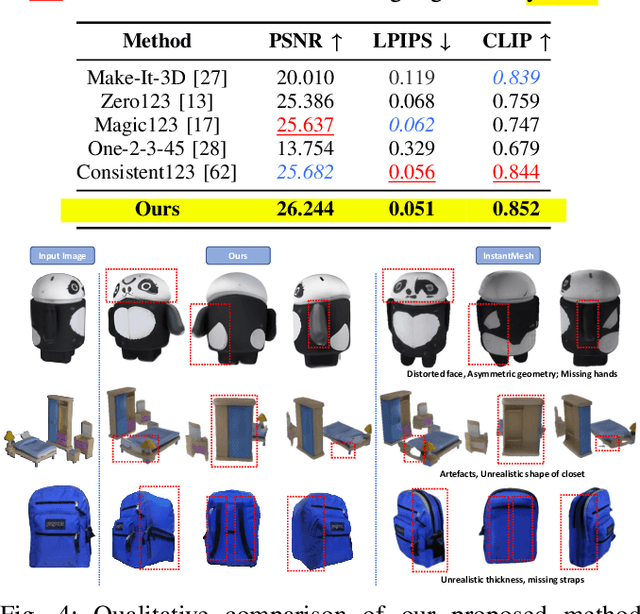
3D object generation from a single image involves estimating the full 3D geometry and texture of unseen views from an unposed RGB image captured in the wild. Accurately reconstructing an object's complete 3D structure and texture has numerous applications in real-world scenarios, including robotic manipulation, grasping, 3D scene understanding, and AR/VR. Recent advancements in 3D object generation have introduced techniques that reconstruct an object's 3D shape and texture by optimizing the efficient representation of Gaussian Splatting, guided by pre-trained 2D or 3D diffusion models. However, a notable disparity exists between the training datasets of these models, leading to distinct differences in their outputs. While 2D models generate highly detailed visuals, they lack cross-view consistency in geometry and texture. In contrast, 3D models ensure consistency across different views but often result in overly smooth textures. We propose bridging the gap between 2D and 3D diffusion models to address this limitation by integrating a two-stage frequency-based distillation loss with Gaussian Splatting. Specifically, we leverage geometric priors in the low-frequency spectrum from a 3D diffusion model to maintain consistent geometry and use a 2D diffusion model to refine the fidelity and texture in the high-frequency spectrum of the generated 3D structure, resulting in more detailed and fine-grained outcomes. Our approach enhances geometric consistency and visual quality, outperforming the current SOTA. Additionally, we demonstrate the easy adaptability of our method for efficient object pose estimation and tracking.
CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
Oct 06, 2023



While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model. To lower the cost of annotation, this work considers the problem of pre-training DNN models for few-shot cell segmentation, where massive unlabeled cell images are available but only a small proportion is annotated. Hereby, we propose Cross-domain Unsupervised Pre-training, namely CUPre, transferring the capability of object detection and instance segmentation for common visual objects (learned from COCO) to the visual domain of cells using unlabeled images. Given a standard COCO pre-trained network with backbone, neck, and head modules, CUPre adopts an alternate multi-task pre-training (AMT2) procedure with two sub-tasks -- in every iteration of pre-training, AMT2 first trains the backbone with cell images from multiple cell datasets via unsupervised momentum contrastive learning (MoCo) [3], and then trains the whole model with vanilla COCO datasets via instance segmentation. After pre-training, CUPre fine-tunes the whole model on the cell segmentation task using a few annotated images. We carry out extensive experiments to evaluate CUPre using LIVECell [2] and BBBC038 [4] datasets in few-shot instance segmentation settings. The experiment shows that CUPre can outperform existing pre-training methods, achieving the highest average precision (AP) for few-shot cell segmentation and detection.
Advancements in Repetitive Action Counting: Joint-Based PoseRAC Model With Improved Performance
Aug 15, 2023



Repetitive counting (RepCount) is critical in various applications, such as fitness tracking and rehabilitation. Previous methods have relied on the estimation of red-green-and-blue (RGB) frames and body pose landmarks to identify the number of action repetitions, but these methods suffer from a number of issues, including the inability to stably handle changes in camera viewpoints, over-counting, under-counting, difficulty in distinguishing between sub-actions, inaccuracy in recognizing salient poses, etc. In this paper, based on the work done by [1], we integrate joint angles with body pose landmarks to address these challenges and achieve better results than the state-of-the-art RepCount methods, with a Mean Absolute Error (MAE) of 0.211 and an Off-By-One (OBO) counting accuracy of 0.599 on the RepCount data set [2]. Comprehensive experimental results demonstrate the effectiveness and robustness of our method.
ACF-Net: An Attention-enhanced Co-interactive Fusion Network for Automated Structural Condition Assessment in Visual Inspection
Jul 14, 2023Efficiently monitoring the condition of civil infrastructures necessitates automating the structural condition assessment in visual inspection. This paper proposes an Attention-enhanced Co-interactive Fusion Network (ACF-Net) for automatic structural condition assessment in visual bridge inspection. The ACF-Net can simultaneously parse structural elements and segment surface defects on the elements in inspection images. It integrates two task-specific relearning subnets to extract task-specific features from an overall feature embedding and a co-interactive feature fusion module to capture the spatial correlation and facilitate information sharing between tasks. Experimental results demonstrate that the proposed ACF-Net outperforms the current state-of-the-art approaches, achieving promising performance with 92.11% mIoU for element parsing and 87.16% mIoU for corrosion segmentation on the new benchmark dataset Steel Bridge Condition Inspection Visual (SBCIV) testing set. An ablation study reveals the strengths of ACF-Net, and a case study showcases its capability to automate structural condition assessment. The code will be open-source after acceptance.