 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMPDM: A Diffusion Model for Driving Video Prediction with Historical Motion Priors
Mar 28, 2026Video prediction is a useful function for autonomous driving, enabling intelligent vehicles to reliably anticipate how driving scenes will evolve and thereby supporting reasoning and safer planning. However, existing models are constrained by multi-stage training pipelines and remain insufficient in modeling the diverse motion patterns in real driving scenes, leading to degraded temporal consistency and visual quality. To address these challenges, this paper introduces the historical motion priors-informed diffusion model (HMPDM), a video prediction model that leverages historical motion priors to enhance motion understanding and temporal coherence. The proposed deep learning system introduces three key designs: (i) a Temporal-aware Latent Conditioning (TaLC) module for implicit historical motion injection; (ii) a Motion-aware Pyramid Encoder (MaPE) for multi-scale motion representation; (iii) a Self-Conditioning (SC) strategy for stable iterative denoising. Extensive experiments on the Cityscapes and KITTI benchmarks demonstrate that HMPDM outperforms state-of-the-art video prediction methods with efficiency, achieving a 28.2% improvement in FVD on Cityscapes under the same monocular RGB input configuration setting. The implementation codes are publicly available at https://github.com/KELISBU/HMPDM.
CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis
Dec 21, 2025
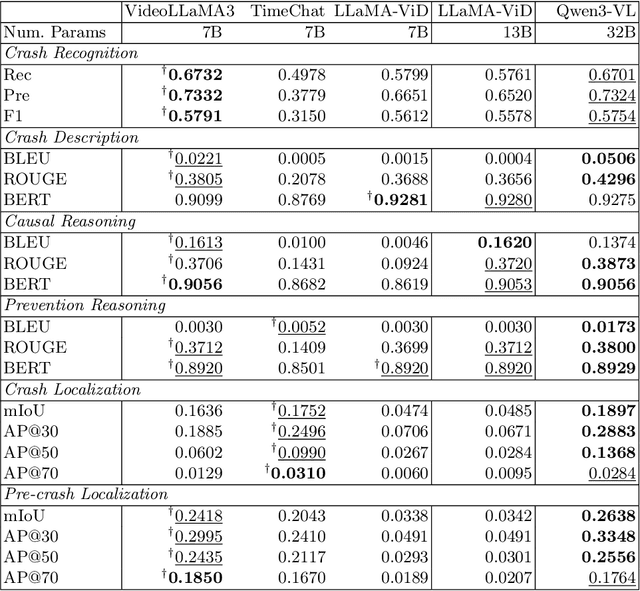
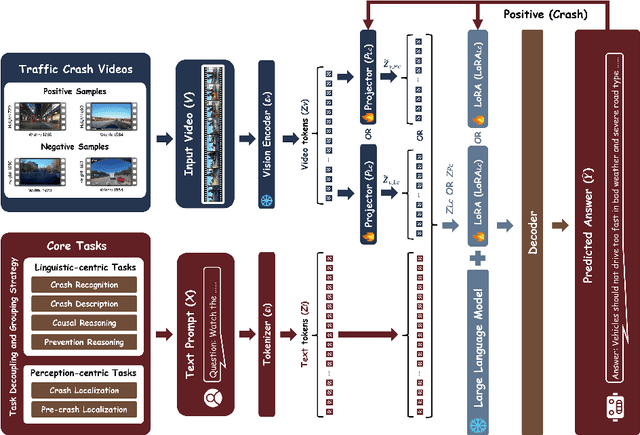
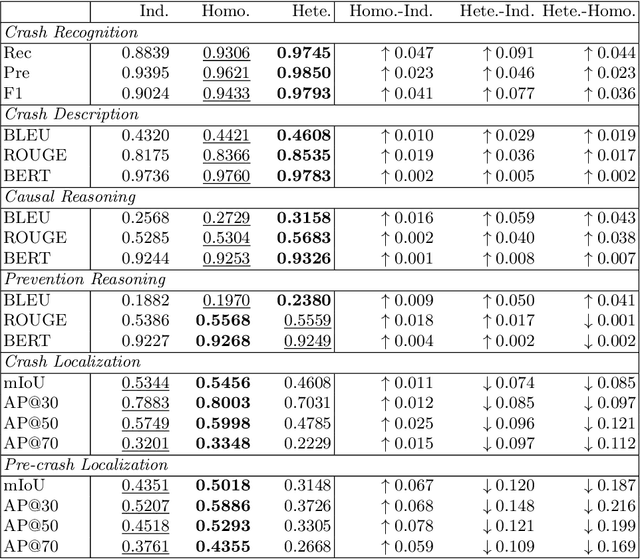
Automating crash video analysis is essential to leverage the growing availability of driving video data for traffic safety research and accountability attribution in autonomous driving. Crash video analysis is a challenging multitask problem due to the complex spatiotemporal dynamics of crash events in video data and the diverse analytical requirements involved. It requires capabilities spanning crash recognition, temporal grounding, and high-level video understanding. Existing models, however, cannot perform all these tasks within a unified framework, and effective training strategies for such models remain underexplored. To fill these gaps, this paper proposes CrashChat, a multimodal large language model (MLLM) for multitask traffic crash analysis, built upon VideoLLaMA3. CrashChat acquires domain-specific knowledge through instruction fine-tuning and employs a novel multitask learning strategy based on task decoupling and grouping, which maximizes the benefit of joint learning within and across task groups while mitigating negative transfer. Numerical experiments on consolidated public datasets demonstrate that CrashChat consistently outperforms existing MLLMs across model scales and traditional vision-based methods, achieving state-of-the-art performance. It reaches near-perfect accuracy in crash recognition, a 176\% improvement in crash localization, and a 40\% improvement in the more challenging pre-crash localization. Compared to general MLLMs, it substantially enhances textual accuracy and content coverage in crash description and reasoning tasks, with 0.18-0.41 increases in BLEU scores and 0.18-0.42 increases in ROUGE scores. Beyond its strong performance, CrashChat is a convenient, end-to-end analytical tool ready for practical implementation. The dataset and implementation code for CrashChat are available at https://github.com/Liangkd/CrashChat.
Fusion-GRU: A Deep Learning Model for Future Bounding Box Prediction of Traffic Agents in Risky Driving Videos
Aug 12, 2023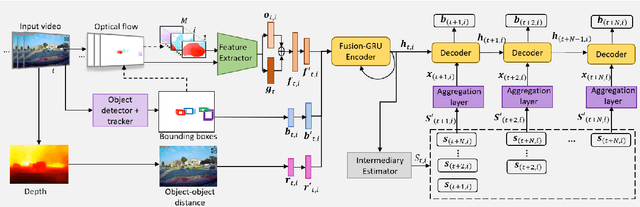
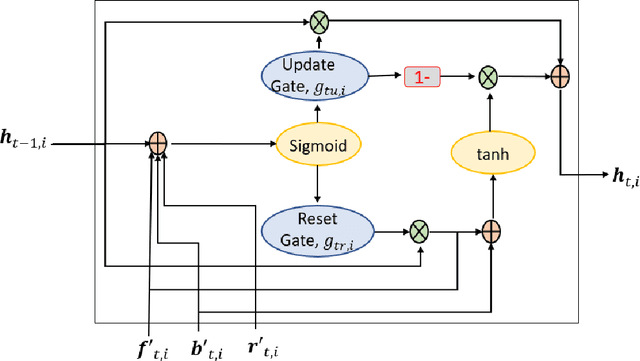
To ensure the safe and efficient navigation of autonomous vehicles and advanced driving assistance systems in complex traffic scenarios, predicting the future bounding boxes of surrounding traffic agents is crucial. However, simultaneously predicting the future location and scale of target traffic agents from the egocentric view poses challenges due to the vehicle's egomotion causing considerable field-of-view changes. Moreover, in anomalous or risky situations, tracking loss or abrupt motion changes limit the available observation time, requiring learning of cues within a short time window. Existing methods typically use a simple concatenation operation to combine different cues, overlooking their dynamics over time. To address this, this paper introduces the Fusion-Gated Recurrent Unit (Fusion-GRU) network, a novel encoder-decoder architecture for future bounding box localization. Unlike traditional GRUs, Fusion-GRU accounts for mutual and complex interactions among input features. Moreover, an intermediary estimator coupled with a self-attention aggregation layer is also introduced to learn sequential dependencies for long range prediction. Finally, a GRU decoder is employed to predict the future bounding boxes. The proposed method is evaluated on two publicly available datasets, ROL and HEV-I. The experimental results showcase the promising performance of the Fusion-GRU, demonstrating its effectiveness in predicting future bounding boxes of traffic agents.
ACF-Net: An Attention-enhanced Co-interactive Fusion Network for Automated Structural Condition Assessment in Visual Inspection
Jul 14, 2023Efficiently monitoring the condition of civil infrastructures necessitates automating the structural condition assessment in visual inspection. This paper proposes an Attention-enhanced Co-interactive Fusion Network (ACF-Net) for automatic structural condition assessment in visual bridge inspection. The ACF-Net can simultaneously parse structural elements and segment surface defects on the elements in inspection images. It integrates two task-specific relearning subnets to extract task-specific features from an overall feature embedding and a co-interactive feature fusion module to capture the spatial correlation and facilitate information sharing between tasks. Experimental results demonstrate that the proposed ACF-Net outperforms the current state-of-the-art approaches, achieving promising performance with 92.11% mIoU for element parsing and 87.16% mIoU for corrosion segmentation on the new benchmark dataset Steel Bridge Condition Inspection Visual (SBCIV) testing set. An ablation study reveals the strengths of ACF-Net, and a case study showcases its capability to automate structural condition assessment. The code will be open-source after acceptance.
An Attention-guided Multistream Feature Fusion Network for Localization of Risky Objects in Driving Videos
Sep 16, 2022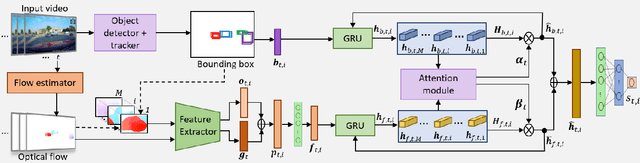
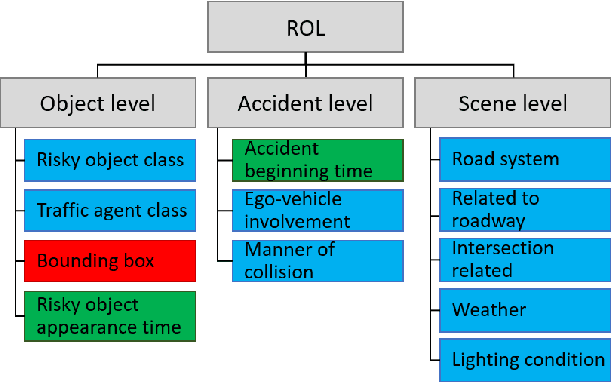

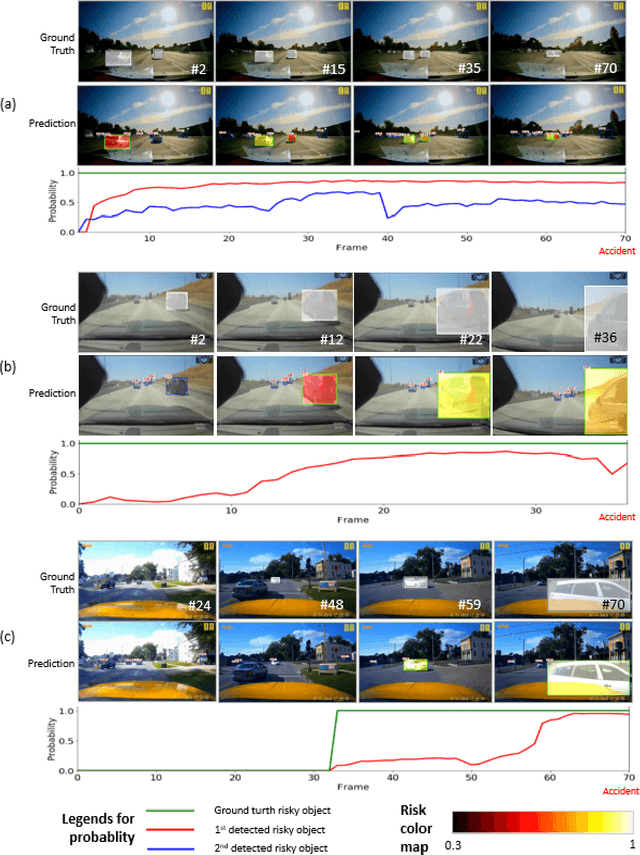
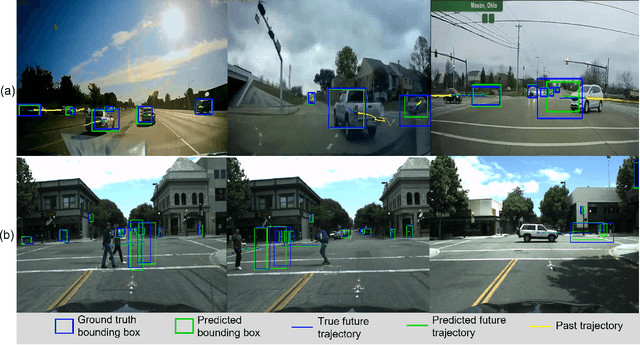
Detecting dangerous traffic agents in videos captured by vehicle-mounted dashboard cameras (dashcams) is essential to facilitate safe navigation in a complex environment. Accident-related videos are just a minor portion of the driving video big data, and the transient pre-accident processes are highly dynamic and complex. Besides, risky and non-risky traffic agents can be similar in their appearance. These make risky object localization in the driving video particularly challenging. To this end, this paper proposes an attention-guided multistream feature fusion network (AM-Net) to localize dangerous traffic agents from dashcam videos. Two Gated Recurrent Unit (GRU) networks use object bounding box and optical flow features extracted from consecutive video frames to capture spatio-temporal cues for distinguishing dangerous traffic agents. An attention module coupled with the GRUs learns to attend to the traffic agents relevant to an accident. Fusing the two streams of features, AM-Net predicts the riskiness scores of traffic agents in the video. In supporting this study, the paper also introduces a benchmark dataset called Risky Object Localization (ROL). The dataset contains spatial, temporal, and categorical annotations with the accident, object, and scene-level attributes. The proposed AM-Net achieves a promising performance of 85.73% AUC on the ROL dataset. Meanwhile, the AM-Net outperforms current state-of-the-art for video anomaly detection by 6.3% AUC on the DoTA dataset. A thorough ablation study further reveals AM-Net's merits by evaluating the contributions of its different components.
A Multitask Deep Learning Model for Parsing Bridge Elements and Segmenting Defect in Bridge Inspection Images
Sep 06, 2022
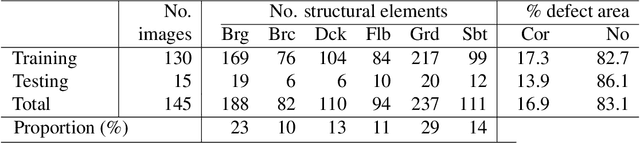
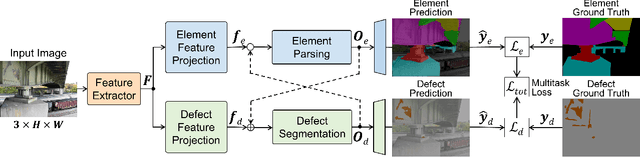
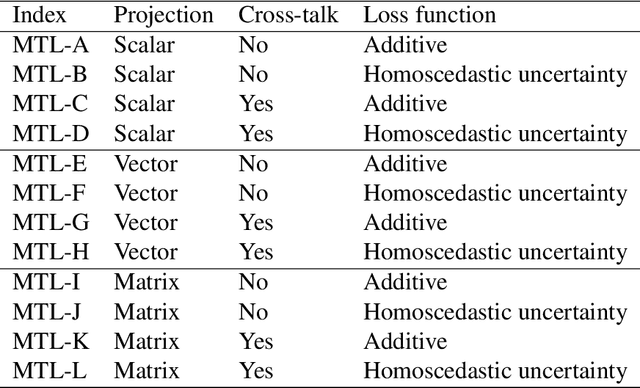
The vast network of bridges in the United States raises a high requirement for its maintenance and rehabilitation. The massive cost of manual visual inspection to assess the conditions of the bridges turns out to be a burden to some extent. Advanced robots have been leveraged to automate inspection data collection. Automating the segmentations of multiclass elements, as well as surface defects on the elements, in the large volume of inspection image data would facilitate an efficient and effective assessment of the bridge condition. Training separate single-task networks for element parsing (i.e., semantic segmentation of multiclass elements) and defect segmentation fails to incorporate the close connection between these two tasks in the inspection images where both recognizable structural elements and apparent surface defects are present. This paper is motivated to develop a multitask deep neural network that fully utilizes such interdependence between bridge elements and defects to boost the performance and generalization of the model. Furthermore, the effectiveness of the proposed network designs in improving the task performance was investigated, including feature decomposition, cross-talk sharing, and multi-objective loss function. A dataset with pixel-level labels of bridge elements and corrosion was developed for training and assessment of the models. Quantitative and qualitative results from evaluating the developed multitask deep neural network demonstrate that the recommended network outperforms the independent single-task networks not only in performance (2.59% higher mIoU on bridge parsing and 1.65% on corrosion segmentation) but also in computational time and implementation capability.
A Deep Neural Network for Multiclass Bridge Element Parsing in Inspection Image Analysis
Sep 05, 2022
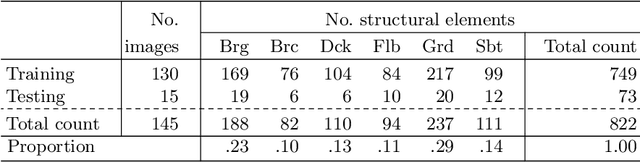


Aerial robots such as drones have been leveraged to perform bridge inspections. Inspection images with both recognizable structural elements and apparent surface defects can be collected by onboard cameras to provide valuable information for the condition assessment. This article aims to determine a suitable deep neural network (DNN) for parsing multiclass bridge elements in inspection images. An extensive set of quantitative evaluations along with qualitative examples show that High-Resolution Net (HRNet) possesses the desired ability. With data augmentation and a training sample of 130 images, a pre-trained HRNet is efficiently transferred to the task of structural element parsing and has achieved a 92.67% mean F1-score and 86.33% mean IoU.
A Simulation Study of Passing Drivers' Responses to the Automated Truck-Mounted Attenuator System in Road Maintenance
Aug 01, 2022



The Autonomous Truck-Mounted Attenuator (ATMA) system is a lead-follower vehicle system based on autonomous driving and connected vehicle technologies. The lead truck performs maintenance tasks on the road, and the unmanned follower truck is designed to improve the visibility of the moving work zone to passing vehicles and to protect workers and equipment. While the ATMA has been under testing by transportation maintenance and operations agencies in recent years, a simulator-based testing capability is a supplement, especially if human subjects are involved. This paper aims to discover how passing drivers perceive, understand, and react to the ATMA system in road maintenance accordingly. A driving simulator for ATMA studies is developed for collecting the driving data. Then, driving simulation experiments were performed, wherein a screen-based eye tracker collected sixteen subjects' gaze points and pupil diameters. Data analysis has evidenced the changes in the visual attention pattern of subjects when they were passing the ATMA. On average, the ATMA starts to attract subjects' attention from 500 ft behind the follower truck. Most (87.50%) understood the follower truck's protection purpose, and the majority (86.67%) reasoned the association between the two trucks. But still, many (43.75%) did not recognize that ATMA is a connected autonomous vehicle system. While all subjects safely changed lanes and attempted to pass the slow-moving ATMA, their inadequate understanding of ATMA is a potential risk, like cutting into the ATAM. Results implied that transportation maintenance and operations agencies should take this into consideration in establishing the deployment guidance.
A Multi-tasking Model of Speaker-Keyword Classification for Keeping Human in the Loop of Drone-assisted Inspection
Jul 08, 2022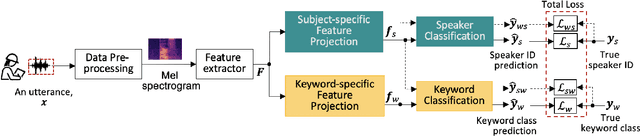


Audio commands are a preferred communication medium to keep inspectors in the loop of civil infrastructure inspection performed by a semi-autonomous drone. To understand job-specific commands from a group of heterogeneous and dynamic inspectors, a model needs to be developed cost-effectively for the group and easily adapted when the group changes. This paper is motivated to build a multi-tasking deep learning model that possesses a Share-Split-Collaborate architecture. This architecture allows the two classification tasks to share the feature extractor and then split subject-specific and keyword-specific features intertwined in the extracted features through feature projection and collaborative training. A base model for a group of five authorized subjects is trained and tested on the inspection keyword dataset collected by this study. The model achieved a 95.3% or higher mean accuracy in classifying the keywords of any authorized inspectors. Its mean accuracy in speaker classification is 99.2%. Due to the richer keyword representations that the model learns from the pooled training data, adapting the base model to a new inspector requires only a little training data from that inspector, like five utterances per keyword. Using the speaker classification scores for inspector verification can achieve a success rate of at least 93.9% in verifying authorized inspectors and 76.1\% in detecting unauthorized ones. Further, the paper demonstrates the applicability of the proposed model to larger-size groups on a public dataset. This paper provides a solution to addressing challenges facing AI-assisted human-robot interaction, including worker heterogeneity, worker dynamics, and job heterogeneity.
Attention-Based Sensor Fusion for Human Activity Recognition Using IMU Signals
Dec 20, 2021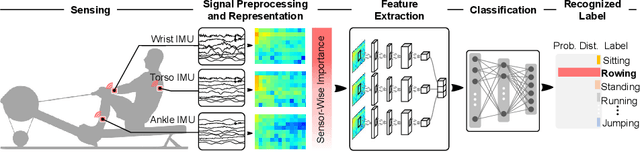

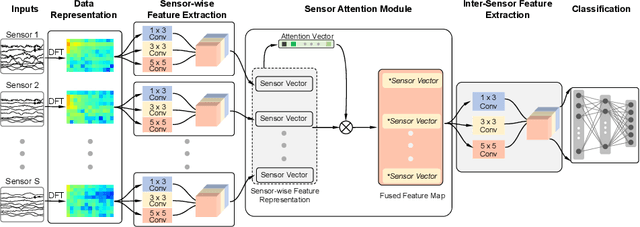
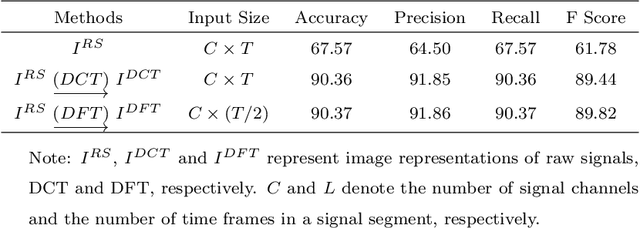
Human Activity Recognition (HAR) using wearable devices such as smart watches embedded with Inertial Measurement Unit (IMU) sensors has various applications relevant to our daily life, such as workout tracking and health monitoring. In this paper, we propose a novel attention-based approach to human activity recognition using multiple IMU sensors worn at different body locations. Firstly, a sensor-wise feature extraction module is designed to extract the most discriminative features from individual sensors with Convolutional Neural Networks (CNNs). Secondly, an attention-based fusion mechanism is developed to learn the importance of sensors at different body locations and to generate an attentive feature representation. Finally, an inter-sensor feature extraction module is applied to learn the inter-sensor correlations, which are connected to a classifier to output the predicted classes of activities. The proposed approach is evaluated using five public datasets and it outperforms state-of-the-art methods on a wide variety of activity categories.