 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-GRU: A Deep Learning Model for Future Bounding Box Prediction of Traffic Agents in Risky Driving Videos
Aug 12, 2023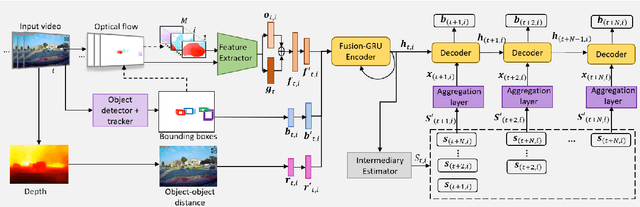
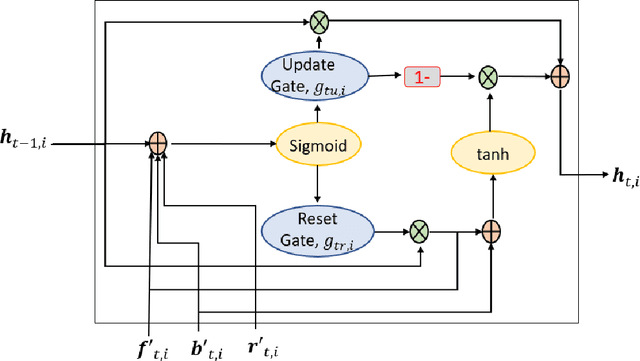
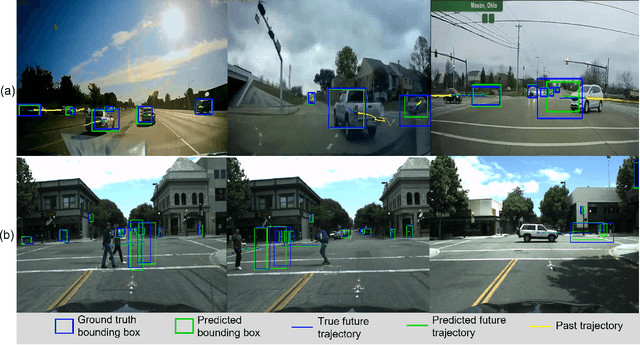
To ensure the safe and efficient navigation of autonomous vehicles and advanced driving assistance systems in complex traffic scenarios, predicting the future bounding boxes of surrounding traffic agents is crucial. However, simultaneously predicting the future location and scale of target traffic agents from the egocentric view poses challenges due to the vehicle's egomotion causing considerable field-of-view changes. Moreover, in anomalous or risky situations, tracking loss or abrupt motion changes limit the available observation time, requiring learning of cues within a short time window. Existing methods typically use a simple concatenation operation to combine different cues, overlooking their dynamics over time. To address this, this paper introduces the Fusion-Gated Recurrent Unit (Fusion-GRU) network, a novel encoder-decoder architecture for future bounding box localization. Unlike traditional GRUs, Fusion-GRU accounts for mutual and complex interactions among input features. Moreover, an intermediary estimator coupled with a self-attention aggregation layer is also introduced to learn sequential dependencies for long range prediction. Finally, a GRU decoder is employed to predict the future bounding boxes. The proposed method is evaluated on two publicly available datasets, ROL and HEV-I. The experimental results showcase the promising performance of the Fusion-GRU, demonstrating its effectiveness in predicting future bounding boxes of traffic agents.
An Attention-guided Multistream Feature Fusion Network for Localization of Risky Objects in Driving Videos
Sep 16, 2022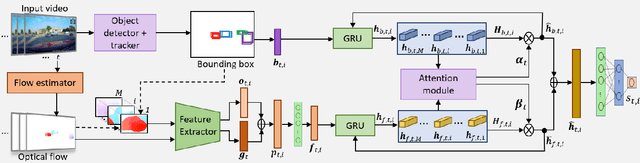
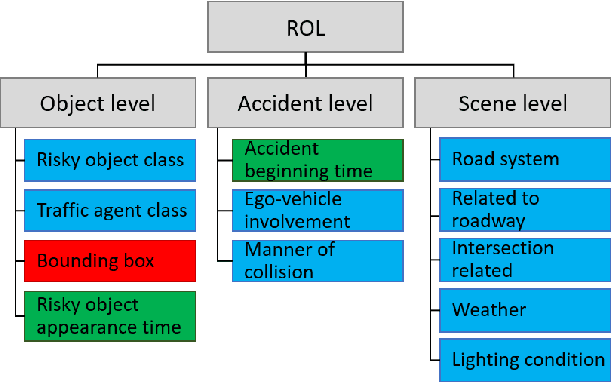

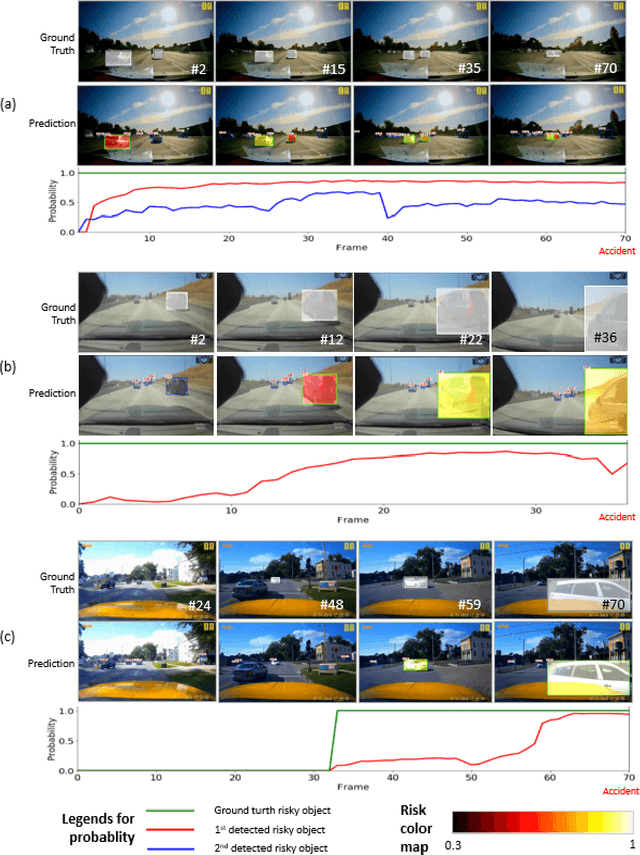
Detecting dangerous traffic agents in videos captured by vehicle-mounted dashboard cameras (dashcams) is essential to facilitate safe navigation in a complex environment. Accident-related videos are just a minor portion of the driving video big data, and the transient pre-accident processes are highly dynamic and complex. Besides, risky and non-risky traffic agents can be similar in their appearance. These make risky object localization in the driving video particularly challenging. To this end, this paper proposes an attention-guided multistream feature fusion network (AM-Net) to localize dangerous traffic agents from dashcam videos. Two Gated Recurrent Unit (GRU) networks use object bounding box and optical flow features extracted from consecutive video frames to capture spatio-temporal cues for distinguishing dangerous traffic agents. An attention module coupled with the GRUs learns to attend to the traffic agents relevant to an accident. Fusing the two streams of features, AM-Net predicts the riskiness scores of traffic agents in the video. In supporting this study, the paper also introduces a benchmark dataset called Risky Object Localization (ROL). The dataset contains spatial, temporal, and categorical annotations with the accident, object, and scene-level attributes. The proposed AM-Net achieves a promising performance of 85.73% AUC on the ROL dataset. Meanwhile, the AM-Net outperforms current state-of-the-art for video anomaly detection by 6.3% AUC on the DoTA dataset. A thorough ablation study further reveals AM-Net's merits by evaluating the contributions of its different components.
A Multitask Deep Learning Model for Parsing Bridge Elements and Segmenting Defect in Bridge Inspection Images
Sep 06, 2022
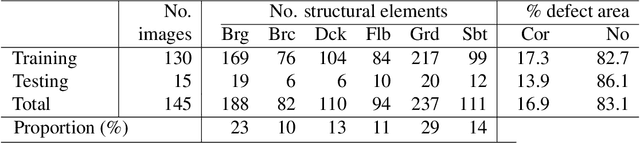
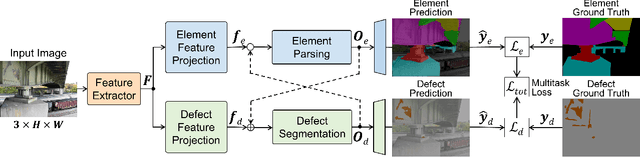
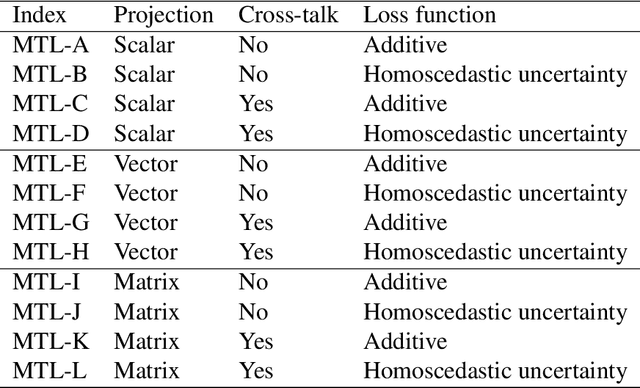
The vast network of bridges in the United States raises a high requirement for its maintenance and rehabilitation. The massive cost of manual visual inspection to assess the conditions of the bridges turns out to be a burden to some extent. Advanced robots have been leveraged to automate inspection data collection. Automating the segmentations of multiclass elements, as well as surface defects on the elements, in the large volume of inspection image data would facilitate an efficient and effective assessment of the bridge condition. Training separate single-task networks for element parsing (i.e., semantic segmentation of multiclass elements) and defect segmentation fails to incorporate the close connection between these two tasks in the inspection images where both recognizable structural elements and apparent surface defects are present. This paper is motivated to develop a multitask deep neural network that fully utilizes such interdependence between bridge elements and defects to boost the performance and generalization of the model. Furthermore, the effectiveness of the proposed network designs in improving the task performance was investigated, including feature decomposition, cross-talk sharing, and multi-objective loss function. A dataset with pixel-level labels of bridge elements and corrosion was developed for training and assessment of the models. Quantitative and qualitative results from evaluating the developed multitask deep neural network demonstrate that the recommended network outperforms the independent single-task networks not only in performance (2.59% higher mIoU on bridge parsing and 1.65% on corrosion segmentation) but also in computational time and implementation capability.
A Deep Neural Network for Multiclass Bridge Element Parsing in Inspection Image Analysis
Sep 05, 2022
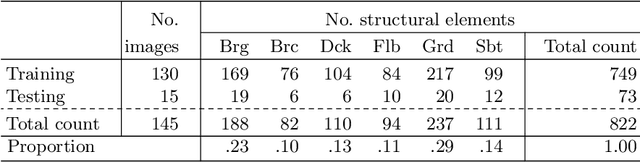


Aerial robots such as drones have been leveraged to perform bridge inspections. Inspection images with both recognizable structural elements and apparent surface defects can be collected by onboard cameras to provide valuable information for the condition assessment. This article aims to determine a suitable deep neural network (DNN) for parsing multiclass bridge elements in inspection images. An extensive set of quantitative evaluations along with qualitative examples show that High-Resolution Net (HRNet) possesses the desired ability. With data augmentation and a training sample of 130 images, a pre-trained HRNet is efficiently transferred to the task of structural element parsing and has achieved a 92.67% mean F1-score and 86.33% mean IoU.
A semi-supervised self-training method to develop assistive intelligence for segmenting multiclass bridge elements from inspection videos
Sep 14, 2021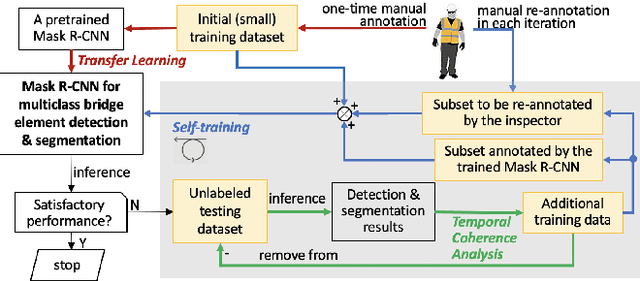
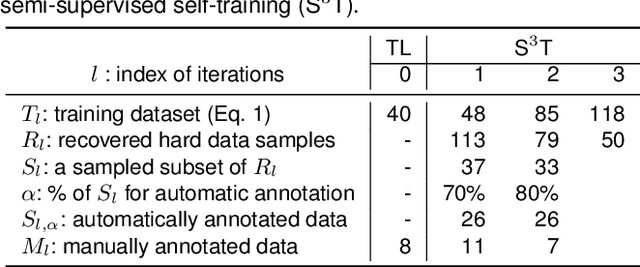
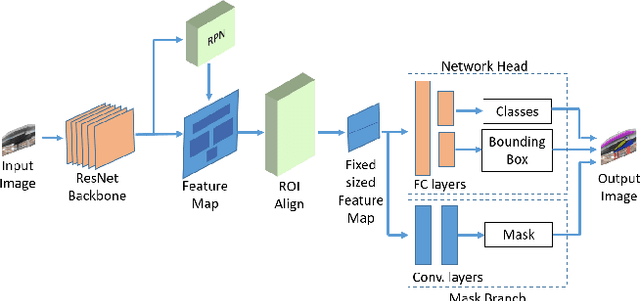
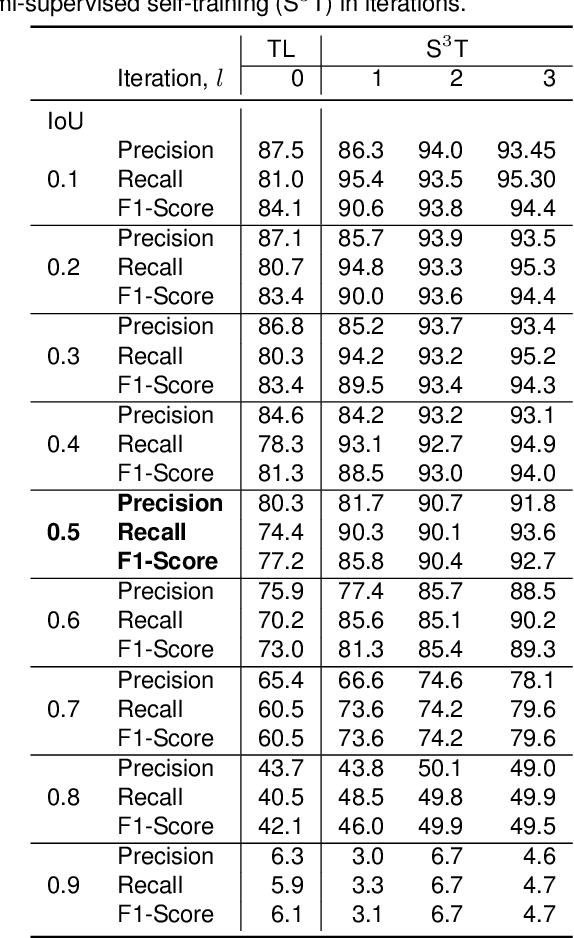
Bridge inspection is an important step in preserving and rehabilitating transportation infrastructure for extending their service lives. The advancement of mobile robotic technology allows the rapid collection of a large amount of inspection video data. However, the data are mainly images of complex scenes, wherein a bridge of various structural elements mix with a cluttered background. Assisting bridge inspectors in extracting structural elements of bridges from the big complex video data, and sorting them out by classes, will prepare inspectors for the element-wise inspection to determine the condition of bridges. This paper is motivated to develop an assistive intelligence model for segmenting multiclass bridge elements from inspection videos captured by an aerial inspection platform. With a small initial training dataset labeled by inspectors, a Mask Region-based Convolutional Neural Network (Mask R-CNN) pre-trained on a large public dataset was transferred to the new task of multiclass bridge element segmentation. Besides, the temporal coherence analysis attempts to recover false negatives and identify the weakness that the neural network can learn to improve. Furthermore, a semi-supervised self-training (S$^3$T) method was developed to engage experienced inspectors in refining the network iteratively. Quantitative and qualitative results from evaluating the developed deep neural network demonstrate that the proposed method can utilize a small amount of time and guidance from experienced inspectors (3.58 hours for labeling 66 images) to build the network of excellent performance (91.8% precision, 93.6% recall, and 92.7% f1-score). Importantly, the paper illustrates an approach to leveraging the domain knowledge and experiences of bridge professionals into computational intelligence models to efficiently adapt the models to varied bridges in the National Bridge Inventory.
* Published in Structural Health Monitoring
Crash Report Data Analysis for Creating Scenario-Wise, Spatio-Temporal Attention Guidance to Support Computer Vision-based Perception of Fatal Crash Risks
Sep 06, 2021
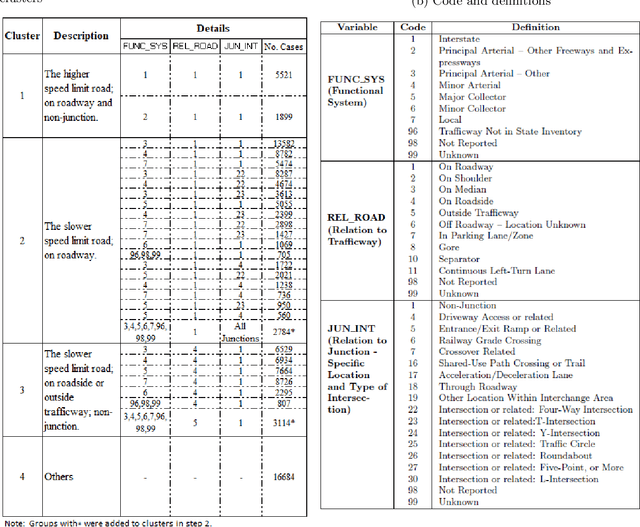
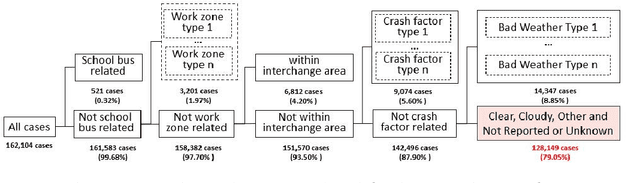
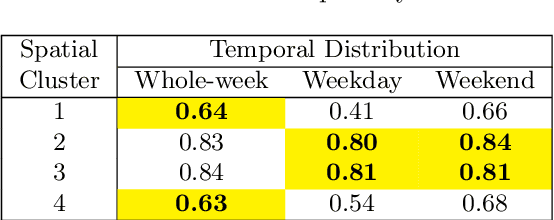
Reducing traffic fatalities and serious injuries is a top priority of the US Department of Transportation. The computer vision (CV)-based crash anticipation in the near-crash phase is receiving growing attention. The ability to perceive fatal crash risks earlier is also critical because it will improve the reliability of crash anticipation. Yet, annotated image data for training a reliable AI model for the early visual perception of crash risks are not abundant. The Fatality Analysis Reporting System contains big data of fatal crashes. It is a reliable data source for learning the relationship between driving scene characteristics and fatal crashes to compensate for the limitation of CV. Therefore, this paper develops a data analytics model, named scenario-wise, Spatio-temporal attention guidance, from fatal crash report data, which can estimate the relevance of detected objects to fatal crashes from their environment and context information. First, the paper identifies five sparse variables that allow for decomposing the 5-year fatal crash dataset to develop scenario-wise attention guidance. Then, exploratory analysis of location- and time-related variables of the crash report data suggests reducing fatal crashes to spatially defined groups. The group's temporal pattern is an indicator of the similarity of fatal crashes in the group. Hierarchical clustering and K-means clustering merge the spatially defined groups into six clusters according to the similarity of their temporal patterns. After that, association rule mining discovers the statistical relationship between the temporal information of driving scenes with crash features, for each cluster. The paper shows how the developed attention guidance supports the design and implementation of a preliminary CV model that can identify objects of a possibility to involve in fatal crashes from their environment and context information.
* 20 pages, 14 figures, submitted and accepted by Accident Analysis & Prevention
A Virtual Reality-based Training and Assessment System for Bridge Inspectors with an Assistant Drone
Sep 06, 2021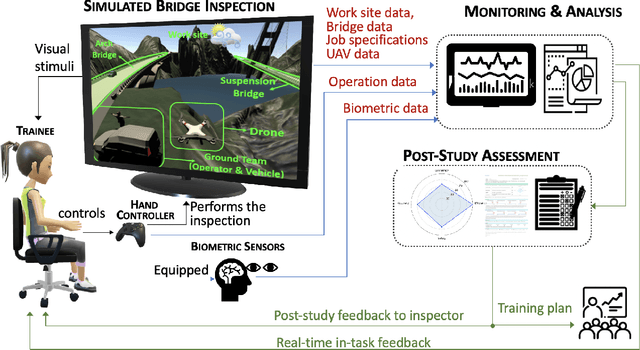



Over 600,000 bridges in the U.S. must be inspected every two years to identify flaws, defects, or potential problems that may need follow-up maintenance. An aerial robotic technology, Unmanned Aerial Vehicles (drones), has been adopted for bridge inspection for improving safety, efficiency, and cost-effectiveness. Although drones have an autonomous operation mode, keeping inspectors in the loop is still necessary for complex tasks like bridge inspection. Therefore, inspectors need to develop the skill and confidence in operating drones in their jobs. This paper presents the design and development of a virtual reality-based system for training inspectors who are assisted by a drone in the bridge inspection. The system is composed of four integrated modules: a simulated bridge inspection developed in Unity, an interface that allows a trainee to operate the drone in simulation using a remote controller, monitoring and analysis that analyzes data to provide real-time, in-task feedback to trainees to assist their learning, and a post-study assessment for accelerating the learning of trainees. The paper also conducts a small-size experimental study to illustrate the functionality of this system and its helpfulness for establishing the inspector-drone partnership. The developed system has built a modeling and analysis foundation for exploring advanced solutions to human-drone cooperative inspection and human sensor-based human-drone interaction.
Towards explainable artificial intelligence for early anticipation of traffic accidents
Jul 31, 2021


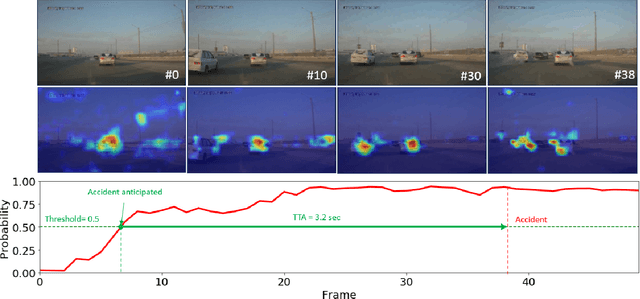
Traffic accident anticipation is a vital function of Automated Driving Systems (ADSs) for providing a safety-guaranteed driving experience. An accident anticipation model aims to predict accidents promptly and accurately before they occur. Existing Artificial Intelligence (AI) models of accident anticipation lack a human-interpretable explanation of their decision-making. Although these models perform well, they remain a black-box to the ADS users, thus difficult to get their trust. To this end, this paper presents a Gated Recurrent Unit (GRU) network that learns spatio-temporal relational features for the early anticipation of traffic accidents from dashcam video data. A post-hoc attention mechanism named Grad-CAM is integrated into the network to generate saliency maps as the visual explanation of the accident anticipation decision. An eye tracker captures human eye fixation points for generating human attention maps. The explainability of network-generated saliency maps is evaluated in comparison to human attention maps. Qualitative and quantitative results on a public crash dataset confirm that the proposed explainable network can anticipate an accident on average 4.57 seconds before it occurs, with 94.02% average precision. In further, various post-hoc attention-based XAI methods are evaluated and compared. It confirms that the Grad-CAM chosen by this study can generate high-quality, human-interpretable saliency maps (with 1.42 Normalized Scanpath Saliency) for explaining the crash anticipation decision. Importantly, results confirm that the proposed AI model, with a human-inspired design, can outperform humans in the accident anticipation.
A system of vision sensor based deep neural networks for complex driving scene analysis in support of crash risk assessment and prevention
Jun 18, 2021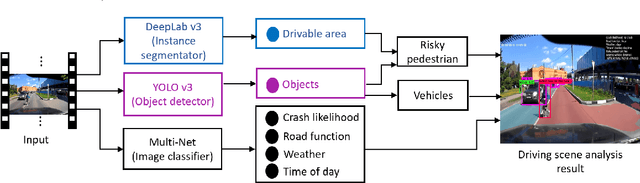


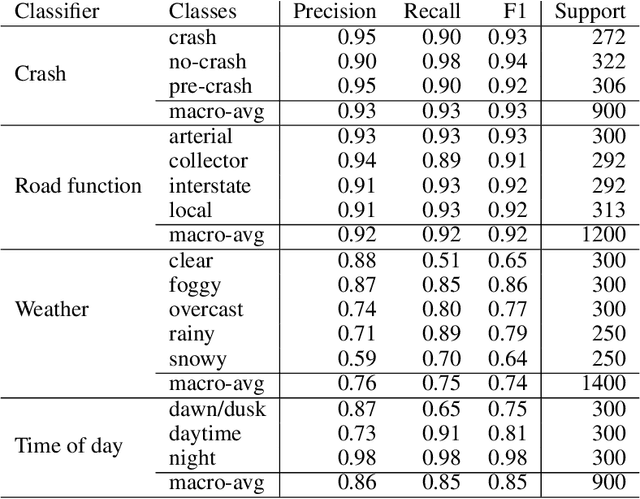
To assist human drivers and autonomous vehicles in assessing crash risks, driving scene analysis using dash cameras on vehicles and deep learning algorithms is of paramount importance. Although these technologies are increasingly available, driving scene analysis for this purpose still remains a challenge. This is mainly due to the lack of annotated large image datasets for analyzing crash risk indicators and crash likelihood, and the lack of an effective method to extract lots of required information from complex driving scenes. To fill the gap, this paper develops a scene analysis system. The Multi-Net of the system includes two multi-task neural networks that perform scene classification to provide four labels for each scene. The DeepLab v3 and YOLO v3 are combined by the system to detect and locate risky pedestrians and the nearest vehicles. All identified information can provide the situational awareness to autonomous vehicles or human drivers for identifying crash risks from the surrounding traffic. To address the scarcity of annotated image datasets for studying traffic crashes, two completely new datasets have been developed by this paper and made available to the public, which were proved to be effective in training the proposed deep neural networks. The paper further evaluates the performance of the Multi-Net and the efficiency of the developed system. Comprehensive scene analysis is further illustrated with representative examples. Results demonstrate the effectiveness of the developed system and datasets for driving scene analysis, and their supportiveness for crash risk assessment and crash prevention.
A Dynamic Spatial-temporal Attention Network for Early Anticipation of Traffic Accidents
Jun 18, 2021
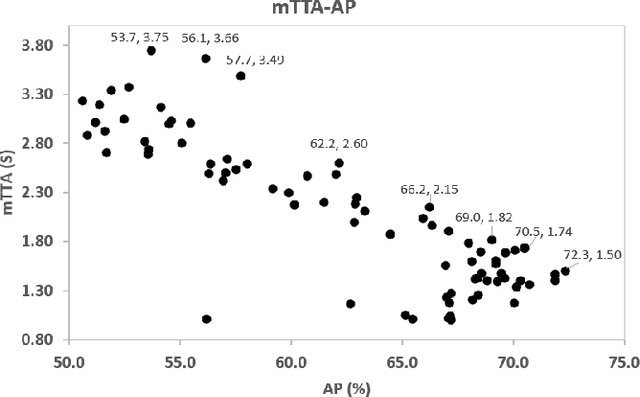

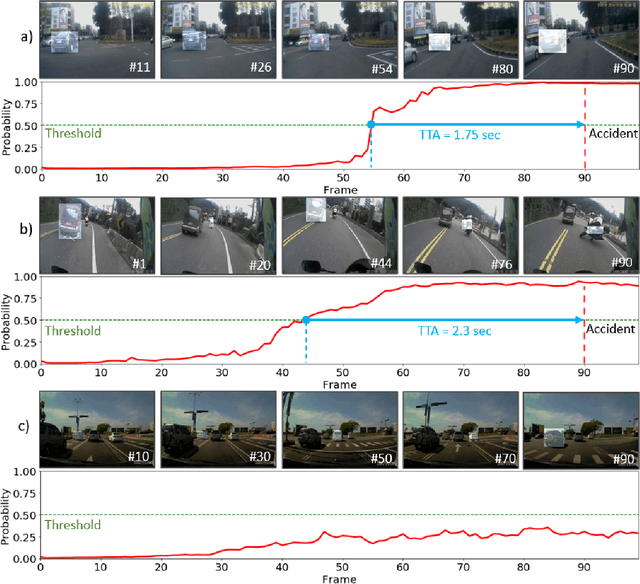
Recently, autonomous vehicles and those equipped with an Advanced Driver Assistance System (ADAS) are emerging. They share the road with regular ones operated by human drivers entirely. To ensure guaranteed safety for passengers and other road users, it becomes essential for autonomous vehicles and ADAS to anticipate traffic accidents from natural driving scenes. The dynamic spatial-temporal interaction of the traffic agents is complex, and visual cues for predicting a future accident are embedded deeply in dashcam video data. Therefore, early anticipation of traffic accidents remains a challenge. To this end, the paper presents a dynamic spatial-temporal attention (DSTA) network for early anticipation of traffic accidents from dashcam videos. The proposed DSTA-network learns to select discriminative temporal segments of a video sequence with a module named Dynamic Temporal Attention (DTA). It also learns to focus on the informative spatial regions of frames with another module named Dynamic Spatial Attention (DSA). The spatial-temporal relational features of accidents, along with scene appearance features, are learned jointly with a Gated Recurrent Unit (GRU) network. The experimental evaluation of the DSTA-network on two benchmark datasets confirms that it has exceeded the state-of-the-art performance. A thorough ablation study evaluates the contributions of individual components of the DSTA-network, revealing how the network achieves such performance. Furthermore, this paper proposes a new strategy that fuses the prediction scores from two complementary models and verifies its effectiveness in further boosting the performance of early accident anticipation.