 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards explainable artificial intelligence for early anticipation of traffic accidents
Paper and Code



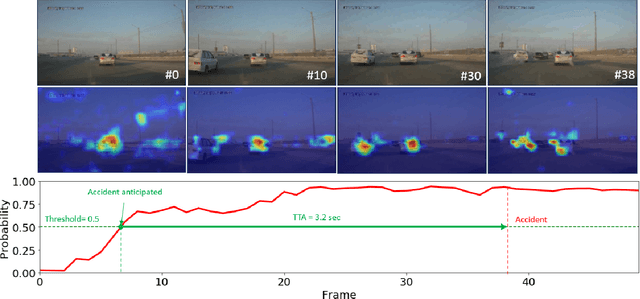
Traffic accident anticipation is a vital function of Automated Driving Systems (ADSs) for providing a safety-guaranteed driving experience. An accident anticipation model aims to predict accidents promptly and accurately before they occur. Existing Artificial Intelligence (AI) models of accident anticipation lack a human-interpretable explanation of their decision-making. Although these models perform well, they remain a black-box to the ADS users, thus difficult to get their trust. To this end, this paper presents a Gated Recurrent Unit (GRU) network that learns spatio-temporal relational features for the early anticipation of traffic accidents from dashcam video data. A post-hoc attention mechanism named Grad-CAM is integrated into the network to generate saliency maps as the visual explanation of the accident anticipation decision. An eye tracker captures human eye fixation points for generating human attention maps. The explainability of network-generated saliency maps is evaluated in comparison to human attention maps. Qualitative and quantitative results on a public crash dataset confirm that the proposed explainable network can anticipate an accident on average 4.57 seconds before it occurs, with 94.02% average precision. In further, various post-hoc attention-based XAI methods are evaluated and compared. It confirms that the Grad-CAM chosen by this study can generate high-quality, human-interpretable saliency maps (with 1.42 Normalized Scanpath Saliency) for explaining the crash anticipation decision. Importantly, results confirm that the proposed AI model, with a human-inspired design, can outperform humans in the accident anticipation.