 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic Spatial-temporal Attention Network for Early Anticipation of Traffic Accidents
Paper and Code

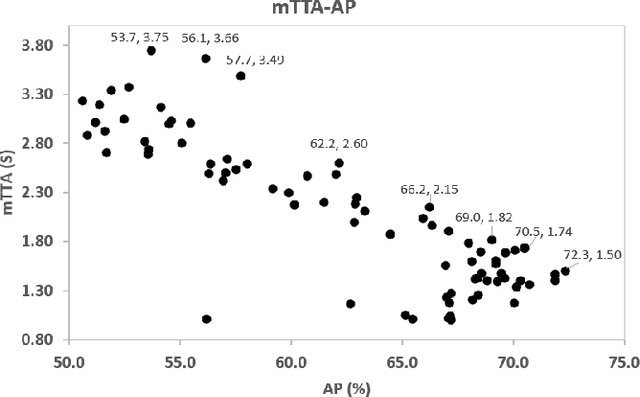

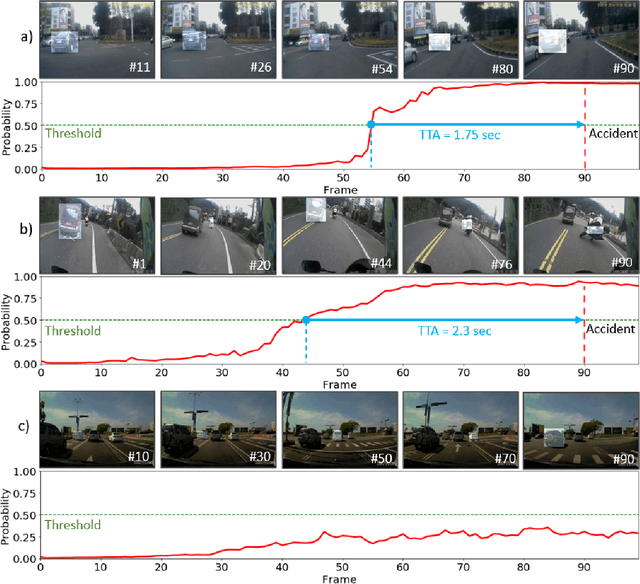
Recently, autonomous vehicles and those equipped with an Advanced Driver Assistance System (ADAS) are emerging. They share the road with regular ones operated by human drivers entirely. To ensure guaranteed safety for passengers and other road users, it becomes essential for autonomous vehicles and ADAS to anticipate traffic accidents from natural driving scenes. The dynamic spatial-temporal interaction of the traffic agents is complex, and visual cues for predicting a future accident are embedded deeply in dashcam video data. Therefore, early anticipation of traffic accidents remains a challenge. To this end, the paper presents a dynamic spatial-temporal attention (DSTA) network for early anticipation of traffic accidents from dashcam videos. The proposed DSTA-network learns to select discriminative temporal segments of a video sequence with a module named Dynamic Temporal Attention (DTA). It also learns to focus on the informative spatial regions of frames with another module named Dynamic Spatial Attention (DSA). The spatial-temporal relational features of accidents, along with scene appearance features, are learned jointly with a Gated Recurrent Unit (GRU) network. The experimental evaluation of the DSTA-network on two benchmark datasets confirms that it has exceeded the state-of-the-art performance. A thorough ablation study evaluates the contributions of individual components of the DSTA-network, revealing how the network achieves such performance. Furthermore, this paper proposes a new strategy that fuses the prediction scores from two complementary models and verifies its effectiveness in further boosting the performance of early accident anticipation.