 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-GRU: A Deep Learning Model for Future Bounding Box Prediction of Traffic Agents in Risky Driving Videos
Paper and Code
Aug 12, 2023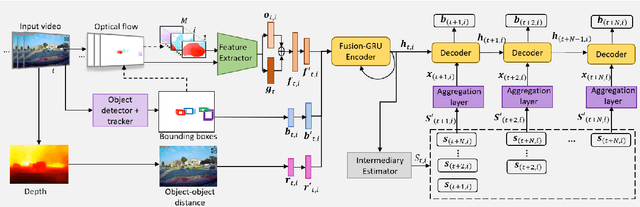
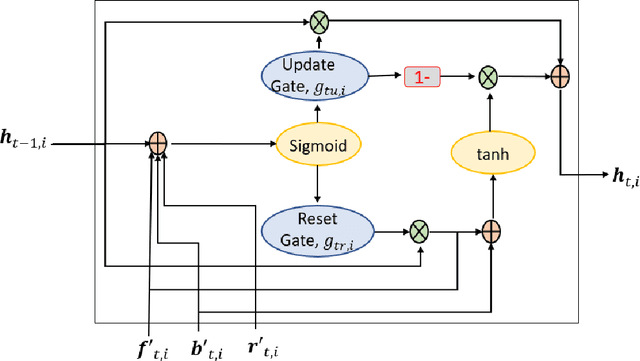
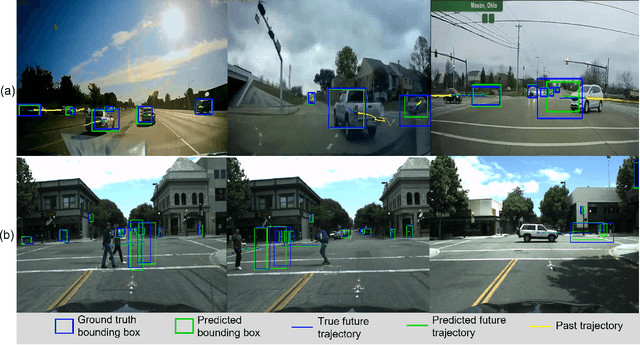
To ensure the safe and efficient navigation of autonomous vehicles and advanced driving assistance systems in complex traffic scenarios, predicting the future bounding boxes of surrounding traffic agents is crucial. However, simultaneously predicting the future location and scale of target traffic agents from the egocentric view poses challenges due to the vehicle's egomotion causing considerable field-of-view changes. Moreover, in anomalous or risky situations, tracking loss or abrupt motion changes limit the available observation time, requiring learning of cues within a short time window. Existing methods typically use a simple concatenation operation to combine different cues, overlooking their dynamics over time. To address this, this paper introduces the Fusion-Gated Recurrent Unit (Fusion-GRU) network, a novel encoder-decoder architecture for future bounding box localization. Unlike traditional GRUs, Fusion-GRU accounts for mutual and complex interactions among input features. Moreover, an intermediary estimator coupled with a self-attention aggregation layer is also introduced to learn sequential dependencies for long range prediction. Finally, a GRU decoder is employed to predict the future bounding boxes. The proposed method is evaluated on two publicly available datasets, ROL and HEV-I. The experimental results showcase the promising performance of the Fusion-GRU, demonstrating its effectiveness in predicting future bounding boxes of traffic agents.