 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

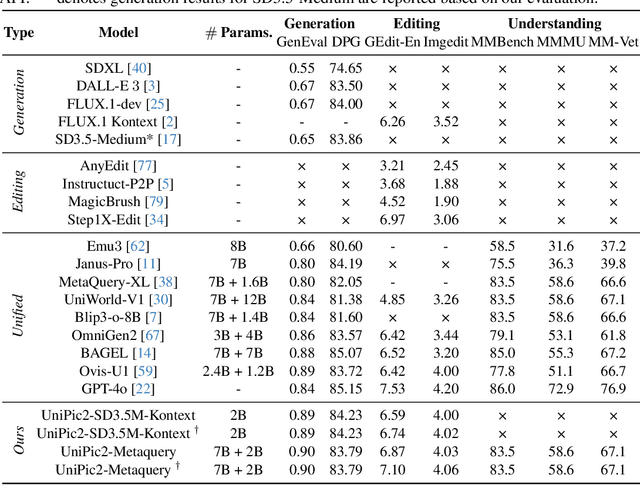
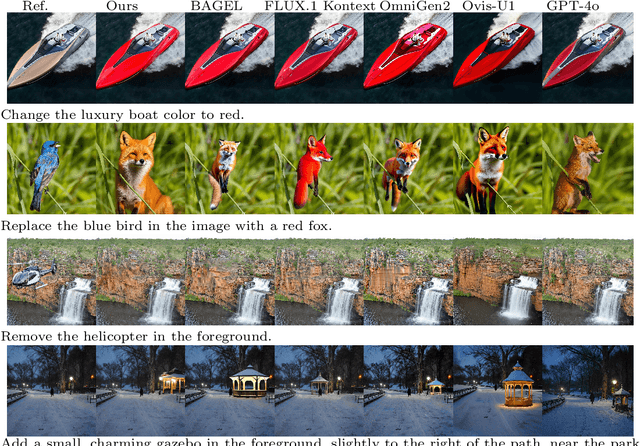
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Evaluation of Habitat Robotics using Large Language Models
Jul 08, 2025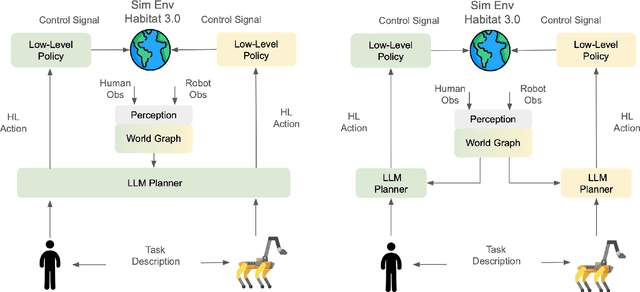
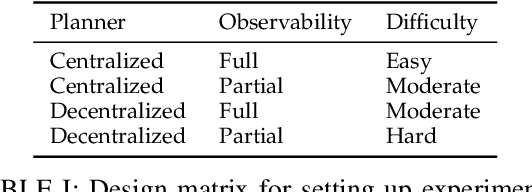
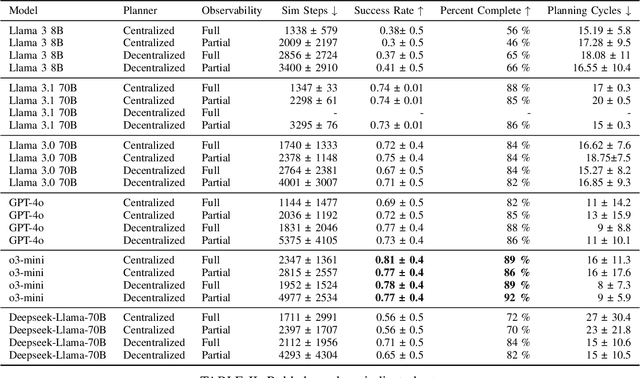
This paper focuses on evaluating the effectiveness of Large Language Models at solving embodied robotic tasks using the Meta PARTNER benchmark. Meta PARTNR provides simplified environments and robotic interactions within randomized indoor kitchen scenes. Each randomized kitchen scene is given a task where two robotic agents cooperatively work together to solve the task. We evaluated multiple frontier models on Meta PARTNER environments. Our results indicate that reasoning models like OpenAI o3-mini outperform non-reasoning models like OpenAI GPT-4o and Llama 3 when operating in PARTNR's robotic embodied environments. o3-mini displayed outperform across centralized, decentralized, full observability, and partial observability configurations. This provides a promising avenue of research for embodied robotic development.
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
May 28, 2025Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys -- the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
A Simulation Study of Passing Drivers' Responses to the Automated Truck-Mounted Attenuator System in Road Maintenance
Aug 01, 2022



The Autonomous Truck-Mounted Attenuator (ATMA) system is a lead-follower vehicle system based on autonomous driving and connected vehicle technologies. The lead truck performs maintenance tasks on the road, and the unmanned follower truck is designed to improve the visibility of the moving work zone to passing vehicles and to protect workers and equipment. While the ATMA has been under testing by transportation maintenance and operations agencies in recent years, a simulator-based testing capability is a supplement, especially if human subjects are involved. This paper aims to discover how passing drivers perceive, understand, and react to the ATMA system in road maintenance accordingly. A driving simulator for ATMA studies is developed for collecting the driving data. Then, driving simulation experiments were performed, wherein a screen-based eye tracker collected sixteen subjects' gaze points and pupil diameters. Data analysis has evidenced the changes in the visual attention pattern of subjects when they were passing the ATMA. On average, the ATMA starts to attract subjects' attention from 500 ft behind the follower truck. Most (87.50%) understood the follower truck's protection purpose, and the majority (86.67%) reasoned the association between the two trucks. But still, many (43.75%) did not recognize that ATMA is a connected autonomous vehicle system. While all subjects safely changed lanes and attempted to pass the slow-moving ATMA, their inadequate understanding of ATMA is a potential risk, like cutting into the ATAM. Results implied that transportation maintenance and operations agencies should take this into consideration in establishing the deployment guidance.
Improving Human-Labeled Data through Dynamic Automatic Conflict Resolution
Dec 08, 2020
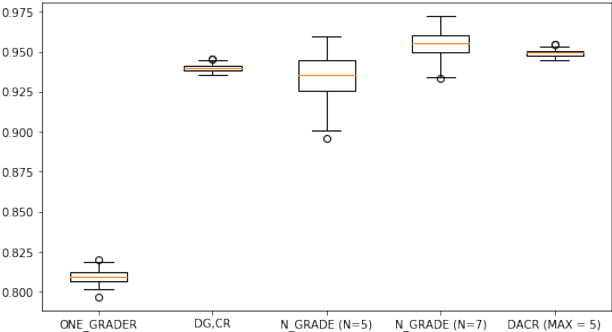

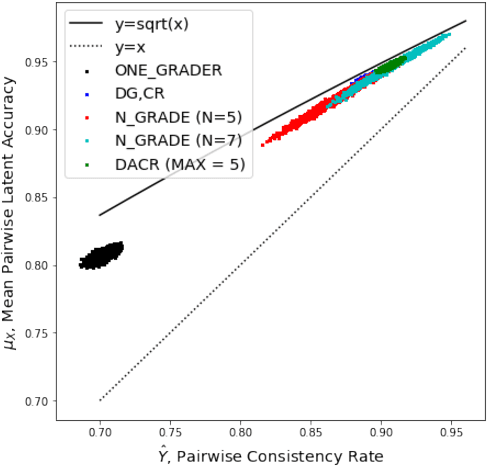
This paper develops and implements a scalable methodology for (a) estimating the noisiness of labels produced by a typical crowdsourcing semantic annotation task, and (b) reducing the resulting error of the labeling process by as much as 20-30% in comparison to other common labeling strategies. Importantly, this new approach to the labeling process, which we name Dynamic Automatic Conflict Resolution (DACR), does not require a ground truth dataset and is instead based on inter-project annotation inconsistencies. This makes DACR not only more accurate but also available to a broad range of labeling tasks. In what follows we present results from a text classification task performed at scale for a commercial personal assistant, and evaluate the inherent ambiguity uncovered by this annotation strategy as compared to other common labeling strategies.
Improving Sales Forecasting Accuracy: A Tensor Factorization Approach with Demand Awareness
Nov 06, 2020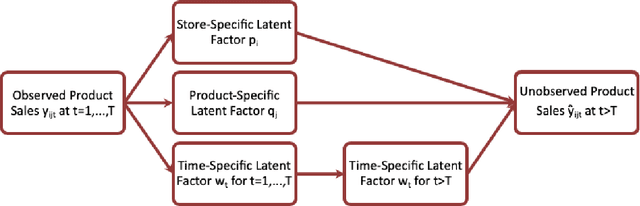
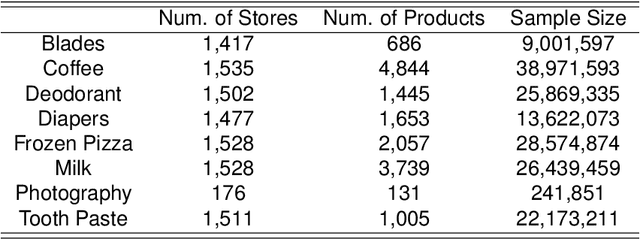
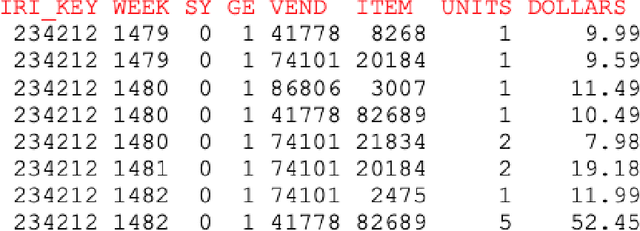
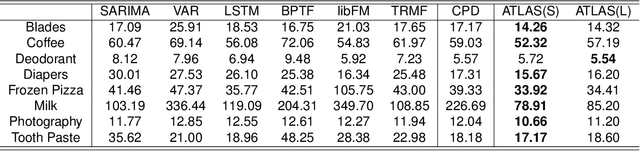
Due to accessible big data collections from consumers, products, and stores, advanced sales forecasting capabilities have drawn great attention from many companies especially in the retail business because of its importance in decision making. Improvement of the forecasting accuracy, even by a small percentage, may have a substantial impact on companies' production and financial planning, marketing strategies, inventory controls, supply chain management, and eventually stock prices. Specifically, our research goal is to forecast the sales of each product in each store in the near future. Motivated by tensor factorization methodologies for personalized context-aware recommender systems, we propose a novel approach called the Advanced Temporal Latent-factor Approach to Sales forecasting (ATLAS), which achieves accurate and individualized prediction for sales by building a single tensor-factorization model across multiple stores and products. Our contribution is a combination of: tensor framework (to leverage information across stores and products), a new regularization function (to incorporate demand dynamics), and extrapolation of tensor into future time periods using state-of-the-art statistical (seasonal auto-regressive integrated moving-average models) and machine-learning (recurrent neural networks) models. The advantages of ATLAS are demonstrated on eight product category datasets collected by the Information Resource, Inc., where a total of 165 million weekly sales transactions from more than 1,500 grocery stores over 15,560 products are analyzed.
Predicting Customer Call Intent by Analyzing Phone Call Transcripts based on CNN for Multi-Class Classification
Jul 08, 2019

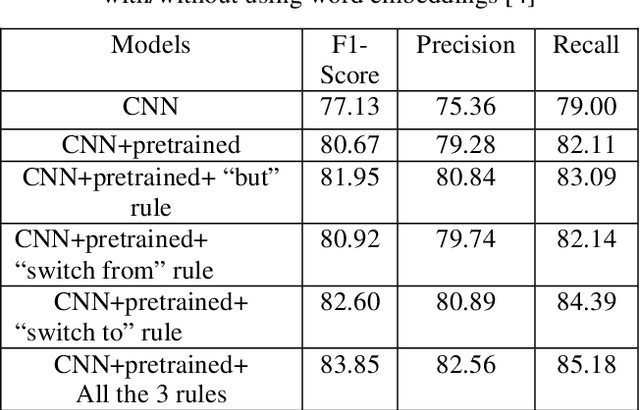
Auto dealerships receive thousands of calls daily from customers who are interested in sales, service, vendors and jobseekers. With so many calls, it is very important for auto dealers to understand the intent of these calls to provide positive customer experiences that ensure customer satisfaction, deep customer engagement to boost sales and revenue, and optimum allocation of agents or customer service representatives across the business. In this paper, we define the problem of customer phone call intent as a multi-class classification problem stemming from the large database of recorded phone call transcripts. To solve this problem, we develop a convolutional neural network (CNN)-based supervised learning model to classify the customer calls into four intent categories: sales, service, vendor and jobseeker. Experimental results show that with the thrust of our scalable data labeling method to provide sufficient training data, the CNN-based predictive model performs very well on long text classification according to the quantitative metrics of F1-Score, precision, recall, and accuracy.