 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human-Labeled Data through Dynamic Automatic Conflict Resolution
Paper and Code
Dec 08, 2020
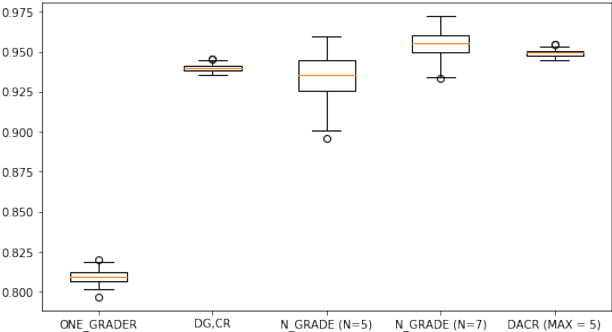

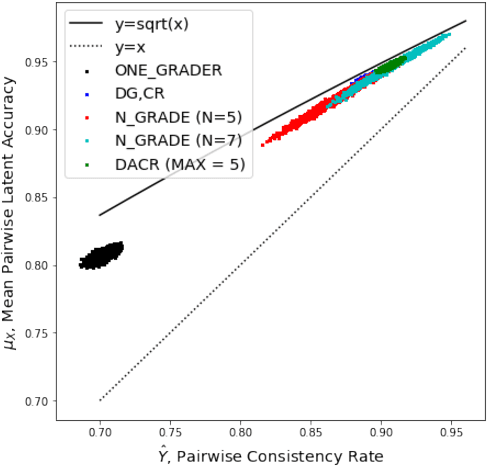
This paper develops and implements a scalable methodology for (a) estimating the noisiness of labels produced by a typical crowdsourcing semantic annotation task, and (b) reducing the resulting error of the labeling process by as much as 20-30% in comparison to other common labeling strategies. Importantly, this new approach to the labeling process, which we name Dynamic Automatic Conflict Resolution (DACR), does not require a ground truth dataset and is instead based on inter-project annotation inconsistencies. This makes DACR not only more accurate but also available to a broad range of labeling tasks. In what follows we present results from a text classification task performed at scale for a commercial personal assistant, and evaluate the inherent ambiguity uncovered by this annotation strategy as compared to other common labeling strategies.