 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Composite Items Using Multi-Level Preference Information: A Joint Interaction Modeling Approach
Jan 26, 2026With the advancement of machine learning and artificial intelligence technologies, recommender systems have been increasingly used across a vast variety of platforms to efficiently and effectively match users with items. As application contexts become more diverse and complex, there is a growing need for more sophisticated recommendation techniques. One example is the composite item (for example, fashion outfit) recommendation where multiple levels of user preference information might be available and relevant. In this study, we propose JIMA, a joint interaction modeling approach that uses a single model to take advantage of all data from different levels of granularity and incorporate interactions to learn the complex relationships among lower-order (atomic item) and higher-order (composite item) user preferences as well as domain expertise (e.g., on the stylistic fit). We comprehensively evaluate the proposed method and compare it with advanced baselines through multiple simulation studies as well as with real data in both offline and online settings. The results consistently demonstrate the superior performance of the proposed approach.
Just Because You Can, Doesn't Mean You Should: LLMs for Data Fitting
Aug 27, 2025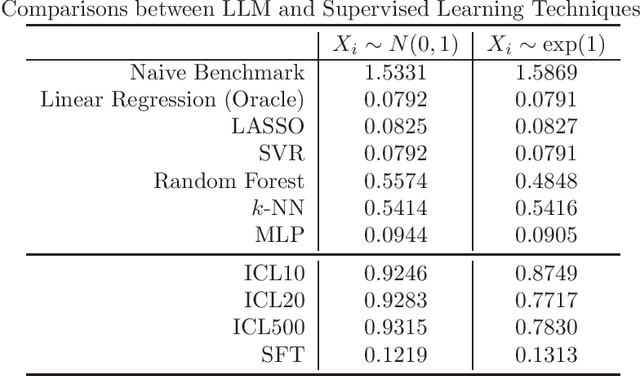
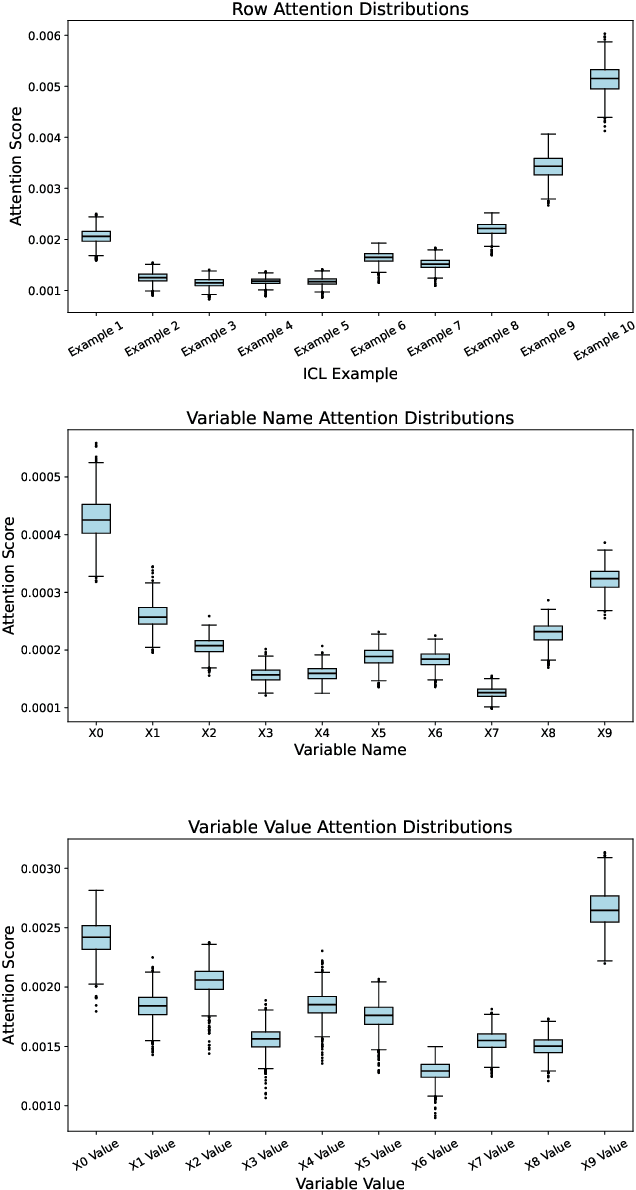
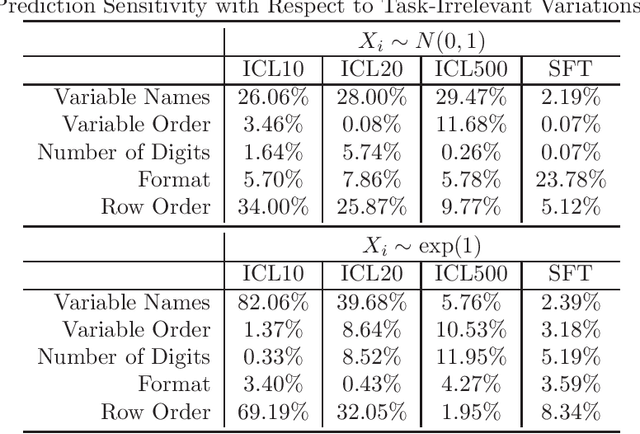
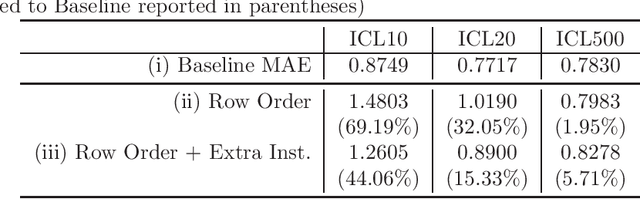
Large Language Models (LLMs) are being applied in a wide array of settings, well beyond the typical language-oriented use cases. In particular, LLMs are increasingly used as a plug-and-play method for fitting data and generating predictions. Prior work has shown that LLMs, via in-context learning or supervised fine-tuning, can perform competitively with many tabular supervised learning techniques in terms of predictive performance. However, we identify a critical vulnerability of using LLMs for data fitting -- making changes to data representation that are completely irrelevant to the underlying learning task can drastically alter LLMs' predictions on the same data. For example, simply changing variable names can sway the size of prediction error by as much as 82% in certain settings. Such prediction sensitivity with respect to task-irrelevant variations manifests under both in-context learning and supervised fine-tuning, for both close-weight and open-weight general-purpose LLMs. Moreover, by examining the attention scores of an open-weight LLM, we discover a non-uniform attention pattern: training examples and variable names/values which happen to occupy certain positions in the prompt receive more attention when output tokens are generated, even though different positions are expected to receive roughly the same attention. This partially explains the sensitivity in the presence of task-irrelevant variations. We also consider a state-of-the-art tabular foundation model (TabPFN) trained specifically for data fitting. Despite being explicitly designed to achieve prediction robustness, TabPFN is still not immune to task-irrelevant variations. Overall, despite LLMs' impressive predictive capabilities, currently they lack even the basic level of robustness to be used as a principled data-fitting tool.
De-centering the (Traditional) User: Multistakeholder Evaluation of Recommender Systems
Jan 09, 2025



Multistakeholder recommender systems are those that account for the impacts and preferences of multiple groups of individuals, not just the end users receiving recommendations. Due to their complexity, evaluating these systems cannot be restricted to the overall utility of a single stakeholder, as is often the case of more mainstream recommender system applications. In this article, we focus our discussion on the intricacies of the evaluation of multistakeholder recommender systems. We bring attention to the different aspects involved in the evaluation of multistakeholder recommender systems - from the range of stakeholders involved (including but not limited to producers and consumers) to the values and specific goals of each relevant stakeholder. Additionally, we discuss how to move from theoretical principles to practical implementation, providing specific use case examples. Finally, we outline open research directions for the RecSys community to explore. We aim to provide guidance to researchers and practitioners about how to think about these complex and domain-dependent issues of evaluation in the course of designing, developing, and researching applications with multistakeholder aspects.
Understanding Longitudinal Dynamics of Recommender Systems with Agent-Based Modeling and Simulation
Aug 25, 2021Today's research in recommender systems is largely based on experimental designs that are static in a sense that they do not consider potential longitudinal effects of providing recommendations to users. In reality, however, various important and interesting phenomena only emerge or become visible over time, e.g., when a recommender system continuously reinforces the popularity of already successful artists on a music streaming site or when recommendations that aim at profit maximization lead to a loss of consumer trust in the long run. In this paper, we discuss how Agent-Based Modeling and Simulation (ABM) techniques can be used to study such important longitudinal dynamics of recommender systems. To that purpose, we provide an overview of the ABM principles, outline a simulation framework for recommender systems based on the literature, and discuss various practical research questions that can be addressed with such an ABM-based simulation framework.
Achieving Reliable Causal Inference with Data-Mined Variables: A Random Forest Approach to the Measurement Error Problem
Dec 19, 2020Combining machine learning with econometric analysis is becoming increasingly prevalent in both research and practice. A common empirical strategy involves the application of predictive modeling techniques to 'mine' variables of interest from available data, followed by the inclusion of those variables into an econometric framework, with the objective of estimating causal effects. Recent work highlights that, because the predictions from machine learning models are inevitably imperfect, econometric analyses based on the predicted variables are likely to suffer from bias due to measurement error. We propose a novel approach to mitigate these biases, leveraging the ensemble learning technique known as the random forest. We propose employing random forest not just for prediction, but also for generating instrumental variables to address the measurement error embedded in the prediction. The random forest algorithm performs best when comprised of a set of trees that are individually accurate in their predictions, yet which also make 'different' mistakes, i.e., have weakly correlated prediction errors. A key observation is that these properties are closely related to the relevance and exclusion requirements of valid instrumental variables. We design a data-driven procedure to select tuples of individual trees from a random forest, in which one tree serves as the endogenous covariate and the other trees serve as its instruments. Simulation experiments demonstrate the efficacy of the proposed approach in mitigating estimation biases and its superior performance over three alternative methods for bias correction.
Improving Sales Forecasting Accuracy: A Tensor Factorization Approach with Demand Awareness
Nov 06, 2020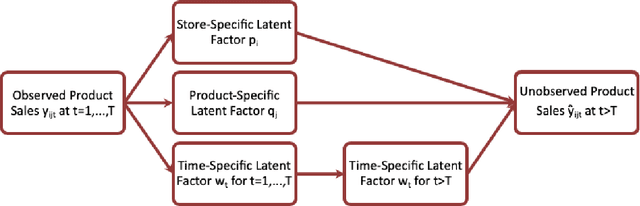
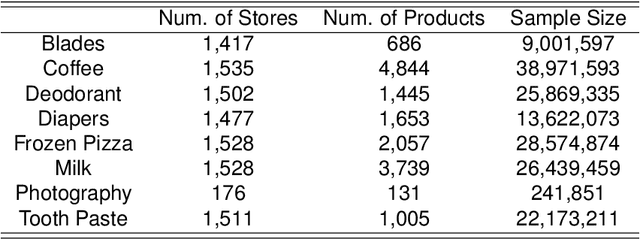
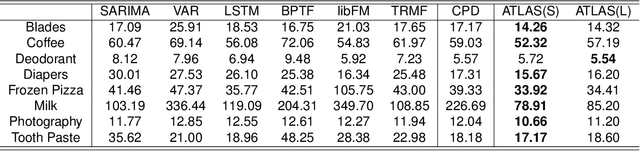
Due to accessible big data collections from consumers, products, and stores, advanced sales forecasting capabilities have drawn great attention from many companies especially in the retail business because of its importance in decision making. Improvement of the forecasting accuracy, even by a small percentage, may have a substantial impact on companies' production and financial planning, marketing strategies, inventory controls, supply chain management, and eventually stock prices. Specifically, our research goal is to forecast the sales of each product in each store in the near future. Motivated by tensor factorization methodologies for personalized context-aware recommender systems, we propose a novel approach called the Advanced Temporal Latent-factor Approach to Sales forecasting (ATLAS), which achieves accurate and individualized prediction for sales by building a single tensor-factorization model across multiple stores and products. Our contribution is a combination of: tensor framework (to leverage information across stores and products), a new regularization function (to incorporate demand dynamics), and extrapolation of tensor into future time periods using state-of-the-art statistical (seasonal auto-regressive integrated moving-average models) and machine-learning (recurrent neural networks) models. The advantages of ATLAS are demonstrated on eight product category datasets collected by the Information Resource, Inc., where a total of 165 million weekly sales transactions from more than 1,500 grocery stores over 15,560 products are analyzed.
Beyond Personalization: Research Directions in Multistakeholder Recommendation
May 01, 2019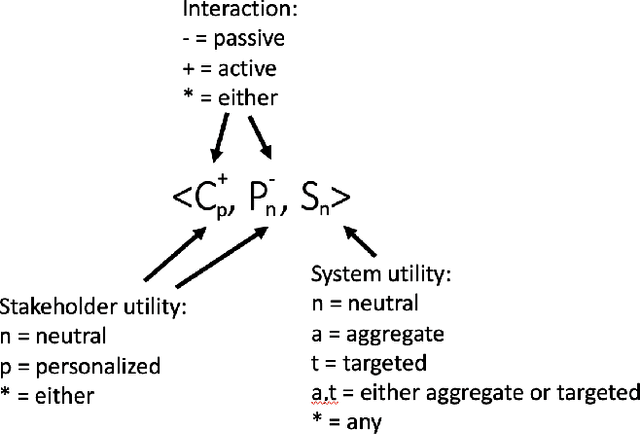

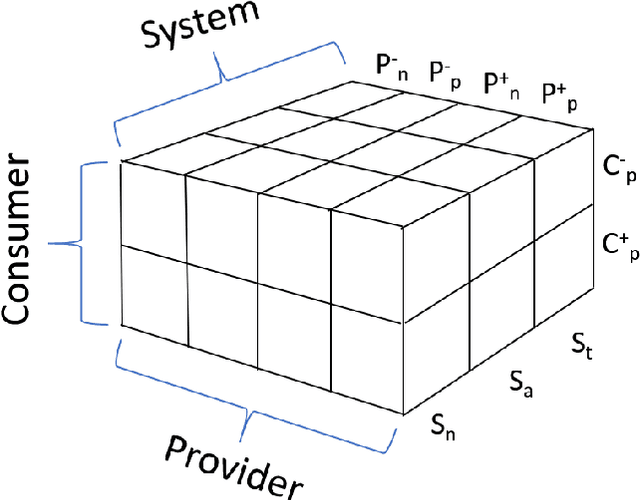
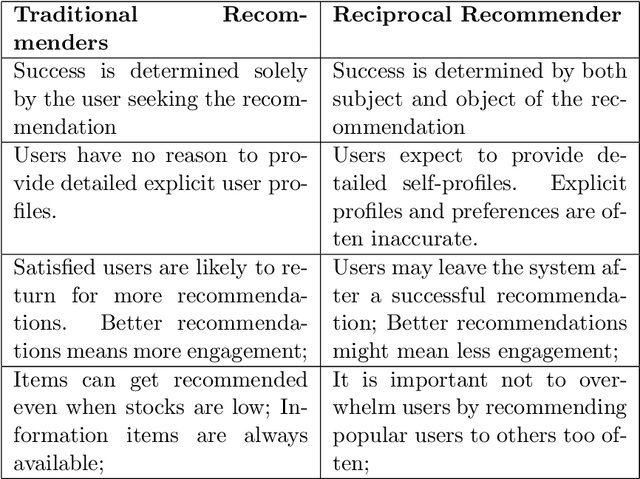
Recommender systems are personalized information access applications; they are ubiquitous in today's online environment, and effective at finding items that meet user needs and tastes. As the reach of recommender systems has extended, it has become apparent that the single-minded focus on the user common to academic research has obscured other important aspects of recommendation outcomes. Properties such as fairness, balance, profitability, and reciprocity are not captured by typical metrics for recommender system evaluation. The concept of multistakeholder recommendation has emerged as a unifying framework for describing and understanding recommendation settings where the end user is not the sole focus. This article describes the origins of multistakeholder recommendation, and the landscape of system designs. It provides illustrative examples of current research, as well as outlining open questions and research directions for the field.
Price and Profit Awareness in Recommender Systems
Jul 25, 2017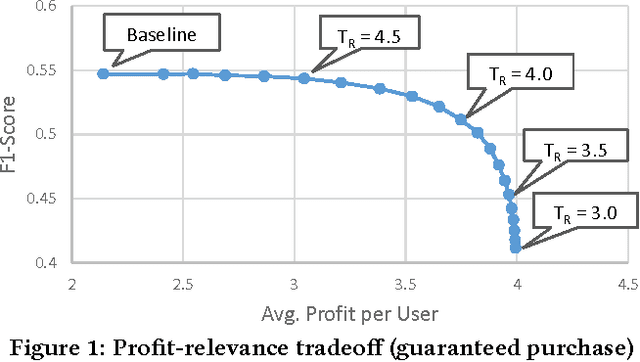

Academic research in the field of recommender systems mainly focuses on the problem of maximizing the users' utility by trying to identify the most relevant items for each user. However, such items are not necessarily the ones that maximize the utility of the service provider (e.g., an online retailer) in terms of the business value, such as profit. One approach to increasing the providers' utility is to incorporate purchase-oriented information, e.g., the price, sales probabilities, and the resulting profit, into the recommendation algorithms. In this paper we specifically focus on price- and profit-aware recommender systems. We provide a brief overview of the relevant literature and use numerical simulations to illustrate the potential business benefit of such approaches.
Data mining for censored time-to-event data: A Bayesian network model for predicting cardiovascular risk from electronic health record data
Apr 08, 2014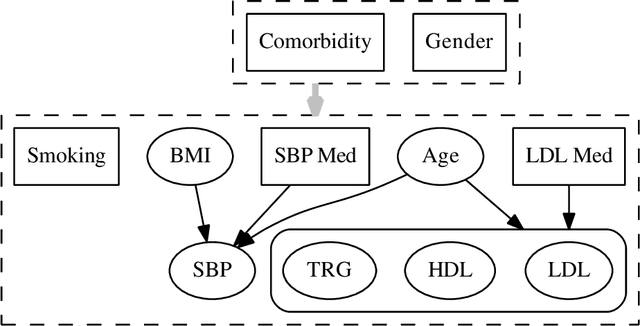


Models for predicting the risk of cardiovascular events based on individual patient characteristics are important tools for managing patient care. Most current and commonly used risk prediction models have been built from carefully selected epidemiological cohorts. However, the homogeneity and limited size of such cohorts restricts the predictive power and generalizability of these risk models to other populations. Electronic health data (EHD) from large health care systems provide access to data on large, heterogeneous, and contemporaneous patient populations. The unique features and challenges of EHD, including missing risk factor information, non-linear relationships between risk factors and cardiovascular event outcomes, and differing effects from different patient subgroups, demand novel machine learning approaches to risk model development. In this paper, we present a machine learning approach based on Bayesian networks trained on EHD to predict the probability of having a cardiovascular event within five years. In such data, event status may be unknown for some individuals as the event time is right-censored due to disenrollment and incomplete follow-up. Since many traditional data mining methods are not well-suited for such data, we describe how to modify both modelling and assessment techniques to account for censored observation times. We show that our approach can lead to better predictive performance than the Cox proportional hazards model (i.e., a regression-based approach commonly used for censored, time-to-event data) or a Bayesian network with {\em{ad hoc}} approaches to right-censoring. Our techniques are motivated by and illustrated on data from a large U.S. Midwestern health care system.
A Naive Bayes machine learning approach to risk prediction using censored, time-to-event data
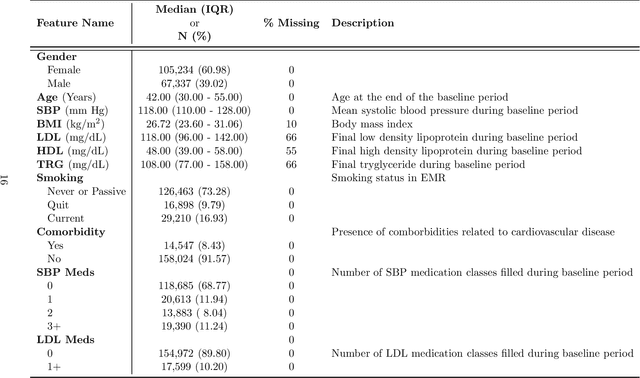
Apr 08, 2014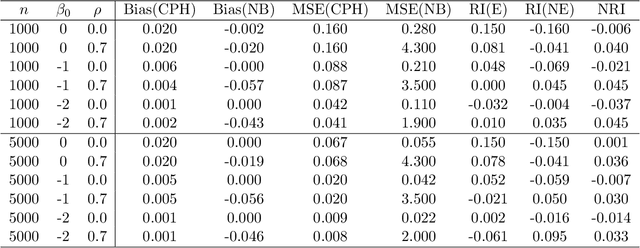
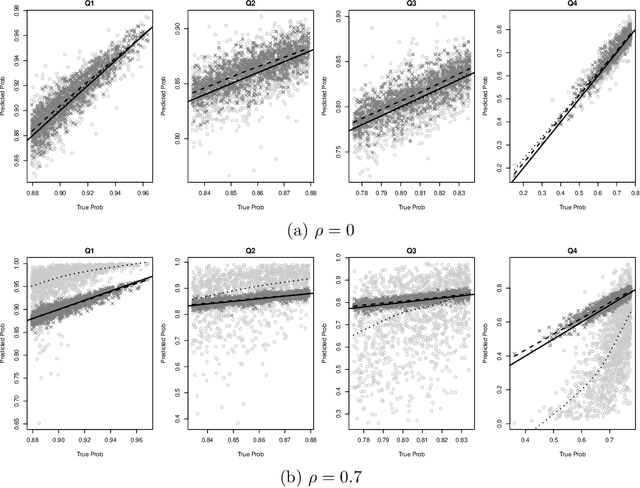
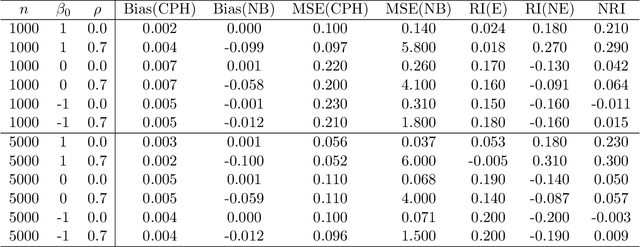
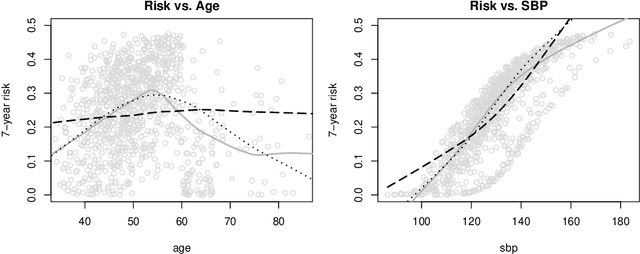
Predicting an individual's risk of experiencing a future clinical outcome is a statistical task with important consequences for both practicing clinicians and public health experts. Modern observational databases such as electronic health records (EHRs) provide an alternative to the longitudinal cohort studies traditionally used to construct risk models, bringing with them both opportunities and challenges. Large sample sizes and detailed covariate histories enable the use of sophisticated machine learning techniques to uncover complex associations and interactions, but observational databases are often ``messy,'' with high levels of missing data and incomplete patient follow-up. In this paper, we propose an adaptation of the well-known Naive Bayes (NB) machine learning approach for classification to time-to-event outcomes subject to censoring. We compare the predictive performance of our method to the Cox proportional hazards model which is commonly used for risk prediction in healthcare populations, and illustrate its application to prediction of cardiovascular risk using an EHR dataset from a large Midwest integrated healthcare system.