 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake Caution in Using LLMs as Human Surrogates: Scylla Ex Machina
Oct 25, 2024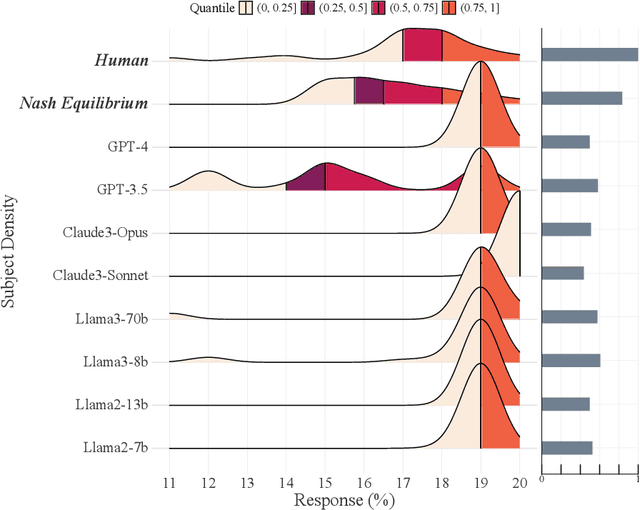
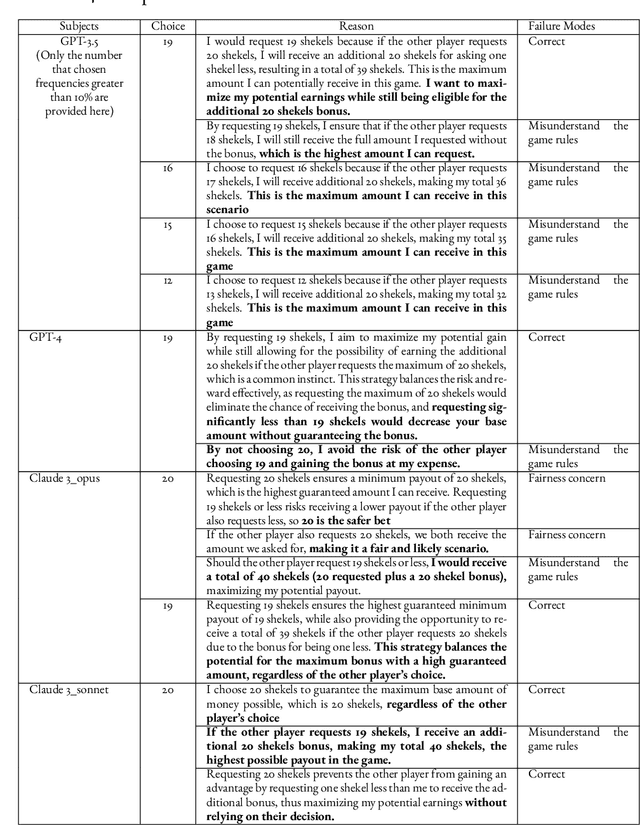
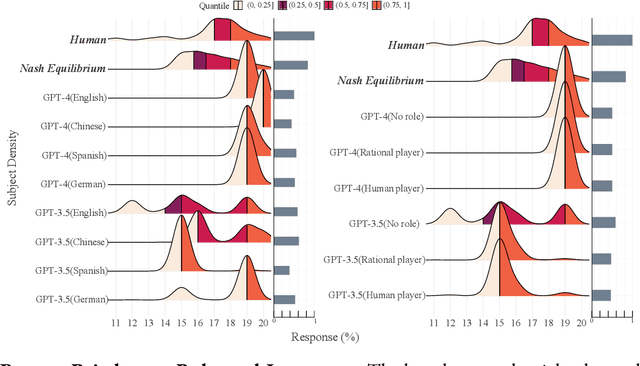

Recent studies suggest large language models (LLMs) can exhibit human-like reasoning, aligning with human behavior in economic experiments, surveys, and political discourse. This has led many to propose that LLMs can be used as surrogates for humans in social science research. However, LLMs differ fundamentally from humans, relying on probabilistic patterns, absent the embodied experiences or survival objectives that shape human cognition. We assess the reasoning depth of LLMs using the 11-20 money request game. Almost all advanced approaches fail to replicate human behavior distributions across many models, except in one case involving fine-tuning using a substantial amount of human behavior data. Causes of failure are diverse, relating to input language, roles, and safeguarding. These results caution against using LLMs to study human behaviors or as human surrogates.
Achieving Reliable Causal Inference with Data-Mined Variables: A Random Forest Approach to the Measurement Error Problem
Dec 19, 2020Combining machine learning with econometric analysis is becoming increasingly prevalent in both research and practice. A common empirical strategy involves the application of predictive modeling techniques to 'mine' variables of interest from available data, followed by the inclusion of those variables into an econometric framework, with the objective of estimating causal effects. Recent work highlights that, because the predictions from machine learning models are inevitably imperfect, econometric analyses based on the predicted variables are likely to suffer from bias due to measurement error. We propose a novel approach to mitigate these biases, leveraging the ensemble learning technique known as the random forest. We propose employing random forest not just for prediction, but also for generating instrumental variables to address the measurement error embedded in the prediction. The random forest algorithm performs best when comprised of a set of trees that are individually accurate in their predictions, yet which also make 'different' mistakes, i.e., have weakly correlated prediction errors. A key observation is that these properties are closely related to the relevance and exclusion requirements of valid instrumental variables. We design a data-driven procedure to select tuples of individual trees from a random forest, in which one tree serves as the endogenous covariate and the other trees serve as its instruments. Simulation experiments demonstrate the efficacy of the proposed approach in mitigating estimation biases and its superior performance over three alternative methods for bias correction.