 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pitfalls of Growing Group Complexity: LLMs and Social Choice-Based Aggregation for Group Recommendations
May 08, 2025Large Language Models (LLMs) are increasingly applied in recommender systems aimed at both individuals and groups. Previously, Group Recommender Systems (GRS) often used social choice-based aggregation strategies to derive a single recommendation based on the preferences of multiple people. In this paper, we investigate under which conditions language models can perform these strategies correctly based on zero-shot learning and analyse whether the formatting of the group scenario in the prompt affects accuracy. We specifically focused on the impact of group complexity (number of users and items), different LLMs, different prompting conditions, including In-Context learning or generating explanations, and the formatting of group preferences. Our results show that performance starts to deteriorate when considering more than 100 ratings. However, not all language models were equally sensitive to growing group complexity. Additionally, we showed that In-Context Learning (ICL) can significantly increase the performance at higher degrees of group complexity, while adding other prompt modifications, specifying domain cues or prompting for explanations, did not impact accuracy. We conclude that future research should include group complexity as a factor in GRS evaluation due to its effect on LLM performance. Furthermore, we showed that formatting the group scenarios differently, such as rating lists per user or per item, affected accuracy. All in all, our study implies that smaller LLMs are capable of generating group recommendations under the right conditions, making the case for using smaller models that require less computing power and costs.
De-centering the (Traditional) User: Multistakeholder Evaluation of Recommender Systems
Jan 09, 2025Multistakeholder recommender systems are those that account for the impacts and preferences of multiple groups of individuals, not just the end users receiving recommendations. Due to their complexity, evaluating these systems cannot be restricted to the overall utility of a single stakeholder, as is often the case of more mainstream recommender system applications. In this article, we focus our discussion on the intricacies of the evaluation of multistakeholder recommender systems. We bring attention to the different aspects involved in the evaluation of multistakeholder recommender systems - from the range of stakeholders involved (including but not limited to producers and consumers) to the values and specific goals of each relevant stakeholder. Additionally, we discuss how to move from theoretical principles to practical implementation, providing specific use case examples. Finally, we outline open research directions for the RecSys community to explore. We aim to provide guidance to researchers and practitioners about how to think about these complex and domain-dependent issues of evaluation in the course of designing, developing, and researching applications with multistakeholder aspects.
Does SpatioTemporal information benefit Two video summarization benchmarks?
Oct 04, 2024An important aspect of summarizing videos is understanding the temporal context behind each part of the video to grasp what is and is not important. Video summarization models have in recent years modeled spatio-temporal relationships to represent this information. These models achieved state-of-the-art correlation scores on important benchmark datasets. However, what has not been reviewed is whether spatio-temporal relationships are even required to achieve state-of-the-art results. Previous work in activity recognition has found biases, by prioritizing static cues such as scenes or objects, over motion information. In this paper we inquire if similar spurious relationships might influence the task of video summarization. To do so, we analyse the role that temporal information plays on existing benchmark datasets. We first estimate a baseline with temporally invariant models to see how well such models rank on benchmark datasets (TVSum and SumMe). We then disrupt the temporal order of the videos to investigate the impact it has on existing state-of-the-art models. One of our findings is that the temporally invariant models achieve competitive correlation scores that are close to the human baselines on the TVSum dataset. We also demonstrate that existing models are not affected by temporal perturbations. Furthermore, with certain disruption strategies that shuffle fixed time segments, we can actually improve their correlation scores. With these results, we find that spatio-temporal relationship play a minor role and we raise the question whether these benchmarks adequately model the task of video summarization. Code available at: https://github.com/AashGan/TemporalPerturbSum
Creating Healthy Friction: Determining Stakeholder Requirements of Job Recommendation Explanations
Sep 24, 2024



The increased use of information retrieval in recruitment, primarily through job recommender systems (JRSs), can have a large impact on job seekers, recruiters, and companies. As a result, such systems have been determined to be high-risk in recent legislature. This requires JRSs to be trustworthy and transparent, allowing stakeholders to understand why specific recommendations were made. To fulfill this requirement, the stakeholders' exact preferences and needs need to be determined. To do so, we evaluated an explainable job recommender system using a realistic, task-based, mixed-design user study (n=30) in which stakeholders had to make decisions based on the model's explanations. This mixed-methods evaluation consisted of two objective metrics - correctness and efficiency, along with three subjective metrics - trust, transparency, and usefulness. These metrics were evaluated twice per participant, once using real explanations and once using random explanations. The study included a qualitative analysis following a think-aloud protocol while performing tasks adapted to each stakeholder group. We find that providing stakeholders with real explanations does not significantly improve decision-making speed and accuracy. Our results showed a non-significant trend for the real explanations to outperform the random ones on perceived trust, usefulness, and transparency of the system for all stakeholder types. We determine that stakeholders benefit more from interacting with explanations as decision support capable of providing healthy friction, rather than as previously-assumed persuasive tools.
Evaluation of Human-Understandability of Global Model Explanations using Decision Tree
Sep 18, 2023In explainable artificial intelligence (XAI) research, the predominant focus has been on interpreting models for experts and practitioners. Model agnostic and local explanation approaches are deemed interpretable and sufficient in many applications. However, in domains like healthcare, where end users are patients without AI or domain expertise, there is an urgent need for model explanations that are more comprehensible and instil trust in the model's operations. We hypothesise that generating model explanations that are narrative, patient-specific and global(holistic of the model) would enable better understandability and enable decision-making. We test this using a decision tree model to generate both local and global explanations for patients identified as having a high risk of coronary heart disease. These explanations are presented to non-expert users. We find a strong individual preference for a specific type of explanation. The majority of participants prefer global explanations, while a smaller group prefers local explanations. A task based evaluation of mental models of these participants provide valuable feedback to enhance narrative global explanations. This, in turn, guides the design of health informatics systems that are both trustworthy and actionable.
A Co-design Study for Multi-Stakeholder Job Recommender System Explanations
Sep 11, 2023Recent legislation proposals have significantly increased the demand for eXplainable Artificial Intelligence (XAI) in many businesses, especially in so-called `high-risk' domains, such as recruitment. Within recruitment, AI has become commonplace, mainly in the form of job recommender systems (JRSs), which try to match candidates to vacancies, and vice versa. However, common XAI techniques often fall short in this domain due to the different levels and types of expertise of the individuals involved, making explanations difficult to generalize. To determine the explanation preferences of the different stakeholder types - candidates, recruiters, and companies - we created and validated a semi-structured interview guide. Using grounded theory, we structurally analyzed the results of these interviews and found that different stakeholder types indeed have strongly differing explanation preferences. Candidates indicated a preference for brief, textual explanations that allow them to quickly judge potential matches. On the other hand, hiring managers preferred visual graph-based explanations that provide a more technical and comprehensive overview at a glance. Recruiters found more exhaustive textual explanations preferable, as those provided them with more talking points to convince both parties of the match. Based on these findings, we describe guidelines on how to design an explanation interface that fulfills the requirements of all three stakeholder types. Furthermore, we provide the validated interview guide, which can assist future research in determining the explanation preferences of different stakeholder types.
Beyond Digital "Echo Chambers": The Role of Viewpoint Diversity in Political Discussion
Dec 18, 2022Increasingly taking place in online spaces, modern political conversations are typically perceived to be unproductively affirming -- siloed in so called ``echo chambers'' of exclusively like-minded discussants. Yet, to date we lack sufficient means to measure viewpoint diversity in conversations. To this end, in this paper, we operationalize two viewpoint metrics proposed for recommender systems and adapt them to the context of social media conversations. This is the first study to apply these two metrics (Representation and Fragmentation) to real world data and to consider the implications for online conversations specifically. We apply these measures to two topics -- daylight savings time (DST), which serves as a control, and the more politically polarized topic of immigration. We find that the diversity scores for both Fragmentation and Representation are lower for immigration than for DST. Further, we find that while pro-immigrant views receive consistent pushback on the platform, anti-immigrant views largely operate within echo chambers. We observe less severe yet similar patterns for DST. Taken together, Representation and Fragmentation paint a meaningful and important new picture of viewpoint diversity.
"It's Not Just Hate'': A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Oct 28, 2022Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed by optimizing time or annotator agreement. We make a case for nuanced efforts in an interdisciplinary setting for annotating offensive online speech. Detecting offensive content is rapidly becoming one of the most important real-world NLP tasks. However, most datasets use a single binary label, e.g., for hate or incivility, even though each concept is multi-faceted. This modeling choice severely limits nuanced insights, but also performance. We show that a more fine-grained multi-label approach to predicting incivility and hateful or intolerant content addresses both conceptual and performance issues. We release a novel dataset of over 40,000 tweets about immigration from the US and UK, annotated with six labels for different aspects of incivility and intolerance. Our dataset not only allows for a more nuanced understanding of harmful speech online, models trained on it also outperform or match performance on benchmark datasets.
Operationalizing Framing to Support MultiperspectiveRecommendations of Opinion Pieces
Jan 15, 2021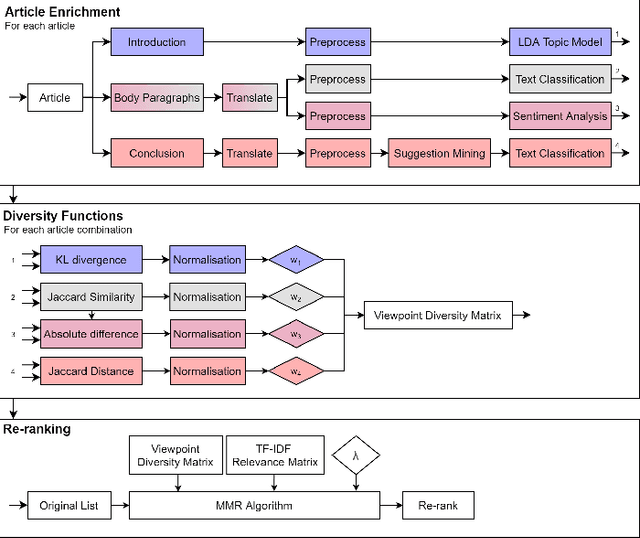


Diversity in personalized news recommender systems is often defined as dissimilarity, and based on topic diversity (e.g., corona versus farmers strike). Diversity in news media, however, is understood as multiperspectivity (e.g., different opinions on corona measures), and arguably a key responsibility of the press in a democratic society. While viewpoint diversity is often considered synonymous with source diversity in communication science domain, in this paper, we take a computational view. We operationalize the notion of framing, adopted from communication science. We apply this notion to a re-ranking of topic-relevant recommended lists, to form the basis of a novel viewpoint diversification method. Our offline evaluation indicates that the proposed method is capable of enhancing the viewpoint diversity of recommendation lists according to a diversity metric from literature. In an online study, on the Blendle platform, a Dutch news aggregator platform, with more than 2000 users, we found that users are willing to consume viewpoint diverse news recommendations. We also found that presentation characteristics significantly influence the reading behaviour of diverse recommendations. These results suggest that future research on presentation aspects of recommendations can be just as important as novel viewpoint diversification methods to truly achieve multiperspectivity in online news environments.
Helping users discover perspectives: Enhancing opinion mining with joint topic models
Oct 23, 2020

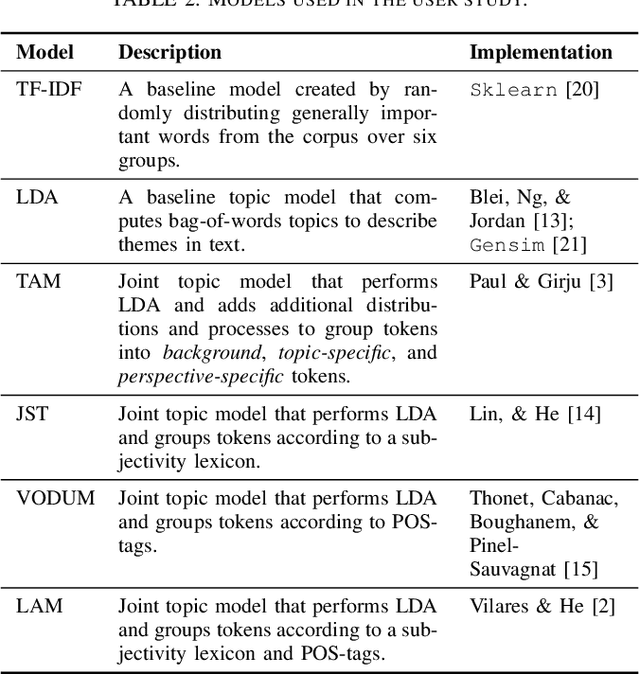
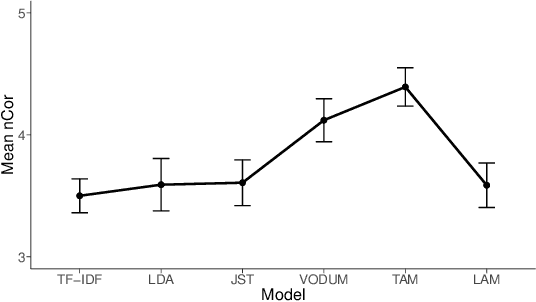
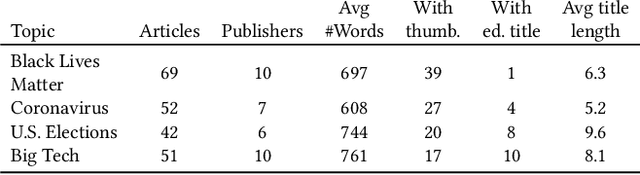
Support or opposition concerning a debated claim such as abortion should be legal can have different underlying reasons, which we call perspectives. This paper explores how opinion mining can be enhanced with joint topic modeling, to identify distinct perspectives within the topic, providing an informative overview from unstructured text. We evaluate four joint topic models (TAM, JST, VODUM, and LAM) in a user study assessing human understandability of the extracted perspectives. Based on the results, we conclude that joint topic models such as TAM can discover perspectives that align with human judgments. Moreover, our results suggest that users are not influenced by their pre-existing stance on the topic of abortion when interpreting the output of topic models.