 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes SpatioTemporal information benefit Two video summarization benchmarks?
Oct 04, 2024An important aspect of summarizing videos is understanding the temporal context behind each part of the video to grasp what is and is not important. Video summarization models have in recent years modeled spatio-temporal relationships to represent this information. These models achieved state-of-the-art correlation scores on important benchmark datasets. However, what has not been reviewed is whether spatio-temporal relationships are even required to achieve state-of-the-art results. Previous work in activity recognition has found biases, by prioritizing static cues such as scenes or objects, over motion information. In this paper we inquire if similar spurious relationships might influence the task of video summarization. To do so, we analyse the role that temporal information plays on existing benchmark datasets. We first estimate a baseline with temporally invariant models to see how well such models rank on benchmark datasets (TVSum and SumMe). We then disrupt the temporal order of the videos to investigate the impact it has on existing state-of-the-art models. One of our findings is that the temporally invariant models achieve competitive correlation scores that are close to the human baselines on the TVSum dataset. We also demonstrate that existing models are not affected by temporal perturbations. Furthermore, with certain disruption strategies that shuffle fixed time segments, we can actually improve their correlation scores. With these results, we find that spatio-temporal relationship play a minor role and we raise the question whether these benchmarks adequately model the task of video summarization. Code available at: https://github.com/AashGan/TemporalPerturbSum
Navigating WebAI: Training Agents to Complete Web Tasks with Large Language Models and Reinforcement Learning
May 01, 2024Recent advancements in language models have demonstrated remarkable improvements in various natural language processing (NLP) tasks such as web navigation. Supervised learning (SL) approaches have achieved impressive performance while utilizing significantly less training data compared to previous methods. However, these SL-based models fall short when compared to reinforcement learning (RL) approaches, which have shown superior results. In this paper, we propose a novel approach that combines SL and RL techniques over the MiniWoB benchmark to leverage the strengths of both methods. We also address a critical limitation in previous models' understanding of HTML content, revealing a tendency to memorize target elements rather than comprehend the underlying structure. To rectify this, we propose methods to enhance true understanding and present a new baseline of results. Our experiments demonstrate that our approach outperforms previous SL methods on certain tasks using less data and narrows the performance gap with RL models, achieving 43.58\% average accuracy in SL and 36.69\% when combined with a multimodal RL approach. This study sets a new direction for future web navigation and offers insights into the limitations and potential of language modeling for computer tasks.
* ACM 2024, Avila Spain. 9 pages
Fashion Object Detection for Tops & Bottoms
May 29, 2023

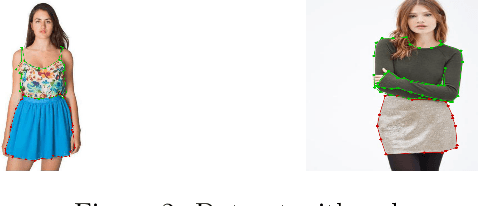
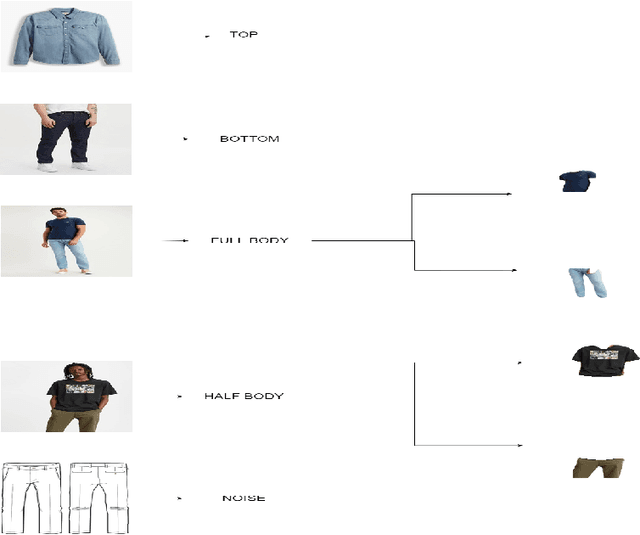
Fashion is one of the largest world's industries and computer vision techniques have been becoming more popular in recent years, in particular, for tasks such as object detection and apparel segmentation. Even with the rapid growth in computer vision solutions, specifically for the fashion industry, many problems are far for being resolved. Therefore, not at all times, adjusting out-of-the-box pre-trained computer vision models will provide the desired solution. In the present paper is proposed a pipeline that takes a noisy image with a person and specifically detects the regions with garments that are bottoms or tops. Our solution implements models that are capable of finding human parts in an image e.g. full-body vs half-body, or no human is found. Then, other models knowing that there's a human and its composition (e.g. not always we have a full-body) finds the bounding boxes/regions of the image that very likely correspond to a bottom or a top. For the creation of bounding boxes/regions task, a benchmark dataset was specifically prepared. The results show that the Mask RCNN solution is robust, and generalized enough to be used and scalable in unseen apparel/fashion data.
Key Information Extraction From Documents: Evaluation And Generator
Jun 09, 2021
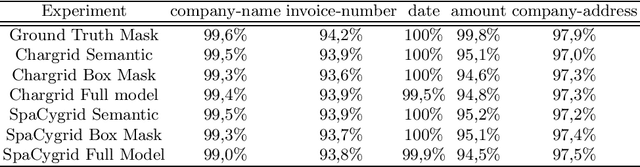
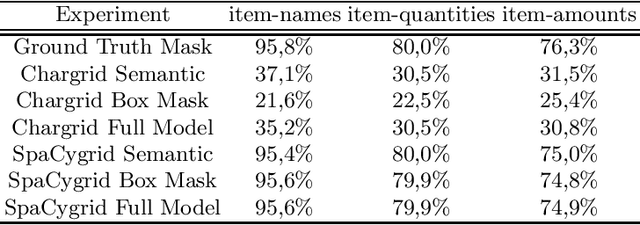
Extracting information from documents usually relies on natural language processing methods working on one-dimensional sequences of text. In some cases, for example, for the extraction of key information from semi-structured documents, such as invoice-documents, spatial and formatting information of text are crucial to understand the contextual meaning. Convolutional neural networks are already common in computer vision models to process and extract relationships in multidimensional data. Therefore, natural language processing models have already been combined with computer vision models in the past, to benefit from e.g. positional information and to improve performance of these key information extraction models. Existing models were either trained on unpublished data sets or on an annotated collection of receipts, which did not focus on PDF-like documents. Hence, in this research project a template-based document generator was created to compare state-of-the-art models for information extraction. An existing information extraction model "Chargrid" (Katti et al., 2019) was reconstructed and the impact of a bounding box regression decoder, as well as the impact of an NLP pre-processing step was evaluated for information extraction from documents. The results have shown that NLP based pre-processing is beneficial for model performance. However, the use of a bounding box regression decoder increases the model performance only for fields that do not follow a rectangular shape.
Being the center of attention: A Person-Context CNN framework for Personality Recognition
Oct 15, 2019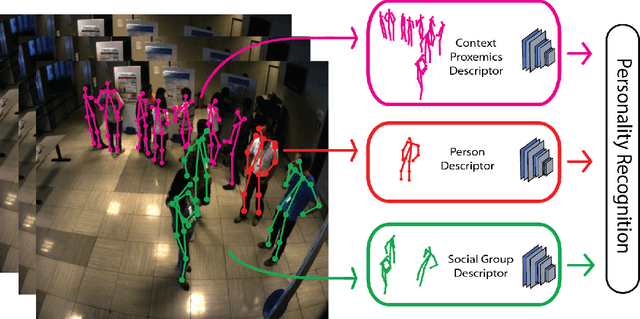
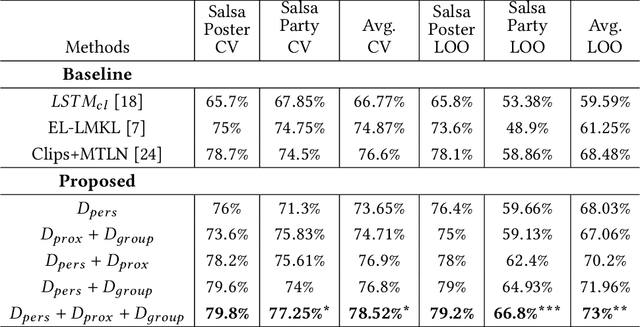
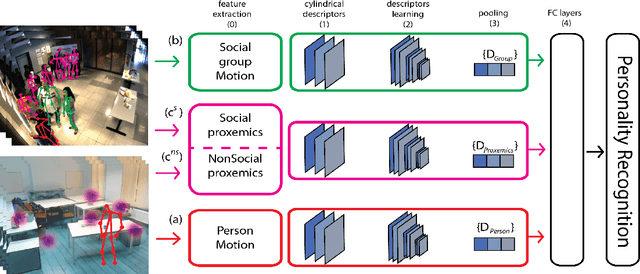
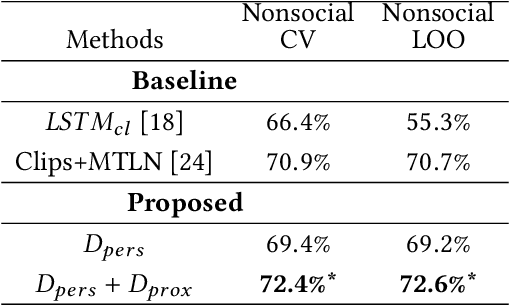
This paper proposes a novel study on personality recognition using video data from different scenarios. Our goal is to jointly model nonverbal behavioral cues with contextual information for a robust, multi-scenario, personality recognition system. Therefore, we build a novel multi-stream Convolutional Neural Network framework (CNN), which considers multiple sources of information. From a given scenario, we extract spatio-temporal motion descriptors from every individual in the scene, spatio-temporal motion descriptors encoding social group dynamics, and proxemics descriptors to encode the interaction with the surrounding context. All the proposed descriptors are mapped to the same feature space facilitating the overall learning effort. Experiments on two public datasets demonstrate the effectiveness of jointly modeling the mutual Person-Context information, outperforming the state-of-the art-results for personality recognition in two different scenarios. Lastly, we present CNN class activation maps for each personality trait, shedding light on behavioral patterns linked with personality attributes.