 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining, Analyzing, and Probing Representations of Self-Supervised Learning Models for Sensor-based Human Activity Recognition
Apr 14, 2023



In recent years, self-supervised learning (SSL) frameworks have been extensively applied to sensor-based Human Activity Recognition (HAR) in order to learn deep representations without data annotations. While SSL frameworks reach performance almost comparable to supervised models, studies on interpreting representations learnt by SSL models are limited. Nevertheless, modern explainability methods could help to unravel the differences between SSL and supervised representations: how they are being learnt, what properties of input data they preserve, and when SSL can be chosen over supervised training. In this paper, we aim to analyze deep representations of two recent SSL frameworks, namely SimCLR and VICReg. Specifically, the emphasis is made on (i) comparing the robustness of supervised and SSL models to corruptions in input data; (ii) explaining predictions of deep learning models using saliency maps and highlighting what input channels are mostly used for predicting various activities; (iii) exploring properties encoded in SSL and supervised representations using probing. Extensive experiments on two single-device datasets (MobiAct and UCI-HAR) have shown that self-supervised learning representations are significantly more robust to noise in unseen data compared to supervised models. In contrast, features learnt by the supervised approaches are more homogeneous across subjects and better encode the nature of activities.
Unsupervised Interpretable Basis Extraction for Concept-Based Visual Explanations
Mar 19, 2023



An important line of research attempts to explain CNN image classifier predictions and intermediate layer representations in terms of human understandable concepts. In this work, we expand on previous works in the literature that use annotated concept datasets to extract interpretable feature space directions and propose an unsupervised post-hoc method to extract a disentangling interpretable basis by looking for the rotation of the feature space that explains sparse one-hot thresholded transformed representations of pixel activations. We do experimentation with existing popular CNNs and demonstrate the effectiveness of our method in extracting an interpretable basis across network architectures and training datasets. We make extensions to the existing basis interpretability metrics found in the literature and show that, intermediate layer representations become more interpretable when transformed to the bases extracted with our method. Finally, using the basis interpretability metrics, we compare the bases extracted with our method with the bases derived with a supervised approach and find that, in one aspect, the proposed unsupervised approach has a strength that constitutes a limitation of the supervised one and give potential directions for future research.
Temporal Feature Alignment in Contrastive Self-Supervised Learning for Human Activity Recognition
Oct 07, 2022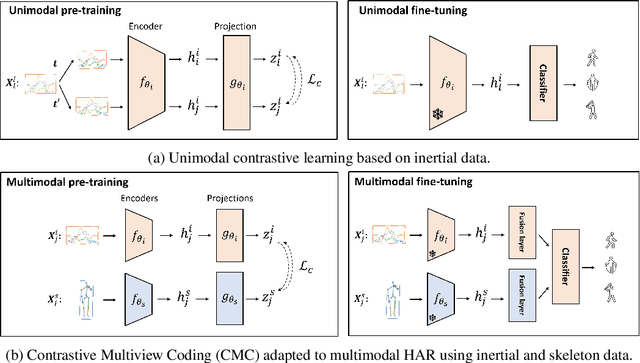
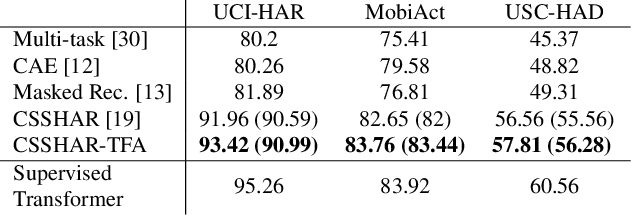
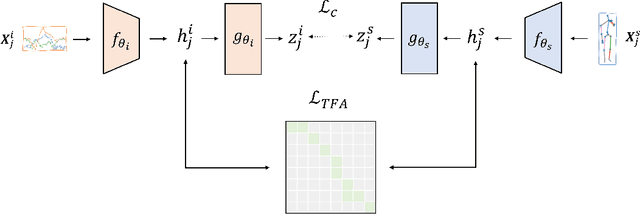
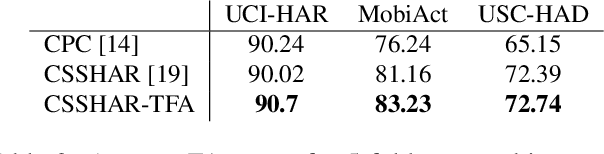
Automated Human Activity Recognition has long been a problem of great interest in human-centered and ubiquitous computing. In the last years, a plethora of supervised learning algorithms based on deep neural networks has been suggested to address this problem using various modalities. While every modality has its own limitations, there is one common challenge. Namely, supervised learning requires vast amounts of annotated data which is practically hard to collect. In this paper, we benefit from the self-supervised learning paradigm (SSL) that is typically used to learn deep feature representations from unlabeled data. Moreover, we upgrade a contrastive SSL framework, namely SimCLR, widely used in various applications by introducing a temporal feature alignment procedure for Human Activity Recognition. Specifically, we propose integrating a dynamic time warping (DTW) algorithm in a latent space to force features to be aligned in a temporal dimension. Extensive experiments have been conducted for the unimodal scenario with inertial modality as well as in multimodal settings using inertial and skeleton data. According to the obtained results, the proposed approach has a great potential in learning robust feature representations compared to the recent SSL baselines, and clearly outperforms supervised models in semi-supervised learning. The code for the unimodal case is available via the following link: https://github.com/bulatkh/csshar_tfa.
Contrastive Learning with Cross-Modal Knowledge Mining for Multimodal Human Activity Recognition
May 20, 2022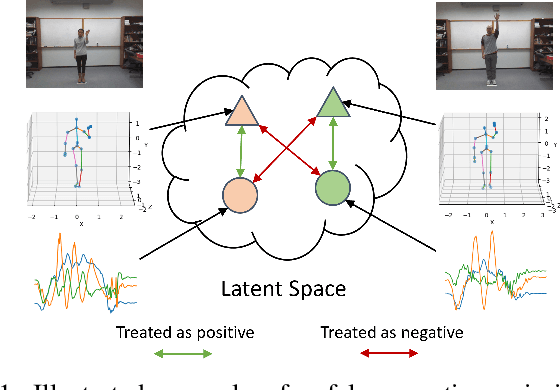
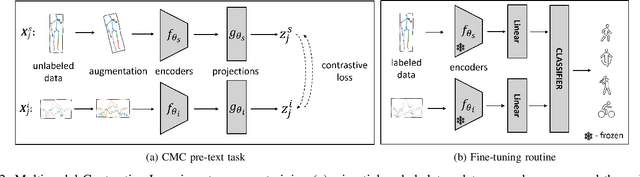
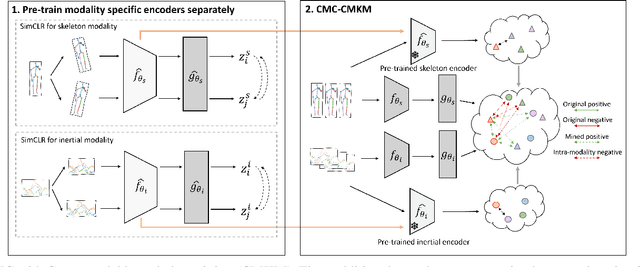
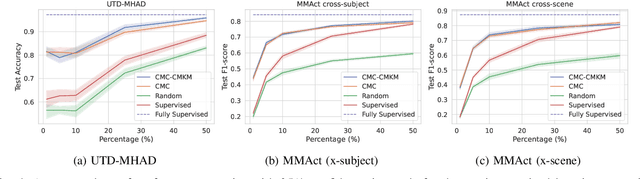
Human Activity Recognition is a field of research where input data can take many forms. Each of the possible input modalities describes human behaviour in a different way, and each has its own strengths and weaknesses. We explore the hypothesis that leveraging multiple modalities can lead to better recognition. Since manual annotation of input data is expensive and time-consuming, the emphasis is made on self-supervised methods which can learn useful feature representations without any ground truth labels. We extend a number of recent contrastive self-supervised approaches for the task of Human Activity Recognition, leveraging inertial and skeleton data. Furthermore, we propose a flexible, general-purpose framework for performing multimodal self-supervised learning, named Contrastive Multiview Coding with Cross-Modal Knowledge Mining (CMC-CMKM). This framework exploits modality-specific knowledge in order to mitigate the limitations of typical self-supervised frameworks. The extensive experiments on two widely-used datasets demonstrate that the suggested framework significantly outperforms contrastive unimodal and multimodal baselines on different scenarios, including fully-supervised fine-tuning, activity retrieval and semi-supervised learning. Furthermore, it shows performance competitive even compared to supervised methods.
Being the center of attention: A Person-Context CNN framework for Personality Recognition
Oct 15, 2019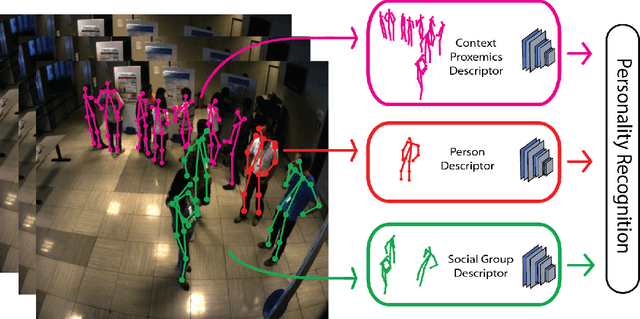
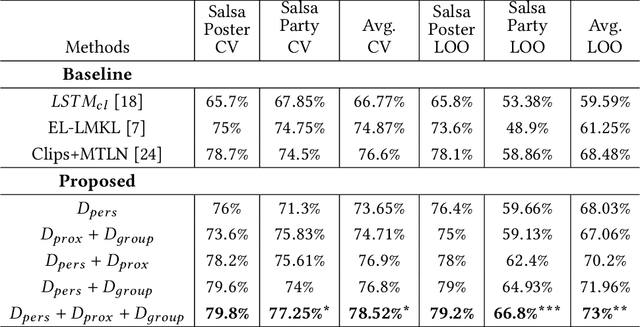
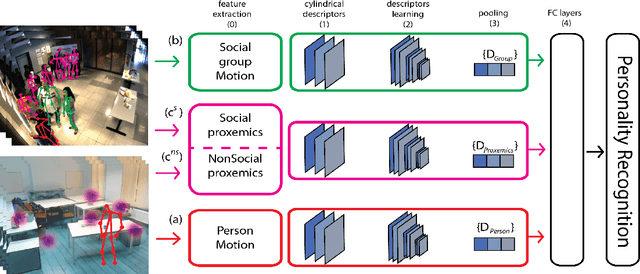
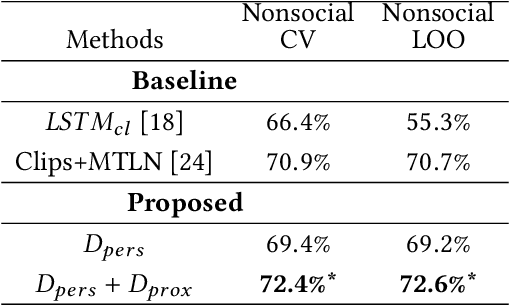
This paper proposes a novel study on personality recognition using video data from different scenarios. Our goal is to jointly model nonverbal behavioral cues with contextual information for a robust, multi-scenario, personality recognition system. Therefore, we build a novel multi-stream Convolutional Neural Network framework (CNN), which considers multiple sources of information. From a given scenario, we extract spatio-temporal motion descriptors from every individual in the scene, spatio-temporal motion descriptors encoding social group dynamics, and proxemics descriptors to encode the interaction with the surrounding context. All the proposed descriptors are mapped to the same feature space facilitating the overall learning effort. Experiments on two public datasets demonstrate the effectiveness of jointly modeling the mutual Person-Context information, outperforming the state-of-the art-results for personality recognition in two different scenarios. Lastly, we present CNN class activation maps for each personality trait, shedding light on behavioral patterns linked with personality attributes.