 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Direction to Choose? An Analysis on the Representation Power of Self-Supervised ViTs in Downstream Tasks
Sep 18, 2025Self-Supervised Learning (SSL) for Vision Transformers (ViTs) has recently demonstrated considerable potential as a pre-training strategy for a variety of computer vision tasks, including image classification and segmentation, both in standard and few-shot downstream contexts. Two pre-training objectives dominate the landscape of SSL techniques: Contrastive Learning and Masked Image Modeling. Features (or tokens) extracted from the final transformer attention block -- specifically, the keys, queries, and values -- as well as features obtained after the final block's feed-forward layer, have become a common foundation for addressing downstream tasks. However, in many existing approaches, these pre-trained ViT features are further processed through additional transformation layers, often involving lightweight heads or combined with distillation, to achieve superior task performance. Although such methods can improve task outcomes, to the best of our knowledge, a comprehensive analysis of the intrinsic representation capabilities of unaltered ViT features has yet to be conducted. This study aims to bridge this gap by systematically evaluating the use of these unmodified features across image classification and segmentation tasks, in both standard and few-shot contexts. The classification and segmentation rules that we use are either hyperplane based (as in logistic regression) or cosine-similarity based, both of which rely on the presence of interpretable directions in the ViT's latent space. Based on the previous rules and without the use of additional feature transformations, we conduct an analysis across token types, tasks, and pre-trained ViT models. This study provides insights into the optimal choice for token type and decision rule based on the task, context, and the pre-training objective, while reporting detailed findings on two widely-used datasets.
Unsupervised Interpretable Basis Extraction for Concept-Based Visual Explanations
Mar 19, 2023



An important line of research attempts to explain CNN image classifier predictions and intermediate layer representations in terms of human understandable concepts. In this work, we expand on previous works in the literature that use annotated concept datasets to extract interpretable feature space directions and propose an unsupervised post-hoc method to extract a disentangling interpretable basis by looking for the rotation of the feature space that explains sparse one-hot thresholded transformed representations of pixel activations. We do experimentation with existing popular CNNs and demonstrate the effectiveness of our method in extracting an interpretable basis across network architectures and training datasets. We make extensions to the existing basis interpretability metrics found in the literature and show that, intermediate layer representations become more interpretable when transformed to the bases extracted with our method. Finally, using the basis interpretability metrics, we compare the bases extracted with our method with the bases derived with a supervised approach and find that, in one aspect, the proposed unsupervised approach has a strength that constitutes a limitation of the supervised one and give potential directions for future research.
Cross-Stitched Multi-task Dual Recursive Networks for Unified Single Image Deraining and Desnowing
Nov 15, 2022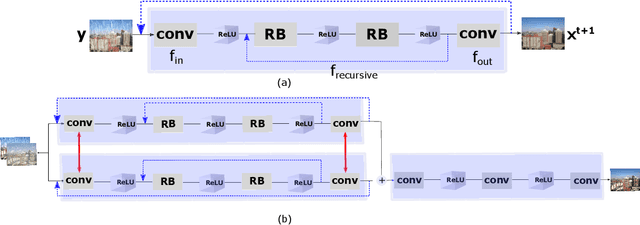
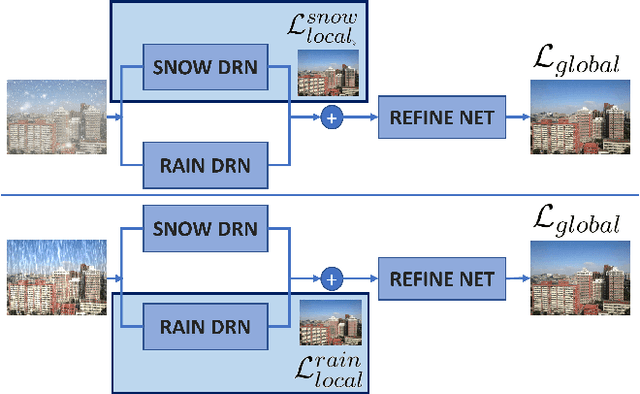

We present the Cross-stitched Multi-task Unified Dual Recursive Network (CMUDRN) model targeting the task of unified deraining and desnowing in a multi-task learning setting. This unified model borrows from the basic Dual Recursive Network (DRN) architecture developed by Cai et al. The proposed model makes use of cross-stitch units that enable multi-task learning across two separate DRN models, each tasked for single image deraining and desnowing, respectively. By fixing cross-stitch units at several layers of basic task-specific DRN networks, we perform multi-task learning over the two separate DRN models. To enable blind image restoration, on top of these structures we employ a simple neural fusion scheme which merges the output of each DRN. The separate task-specific DRN models and the fusion scheme are simultaneously trained by enforcing local and global supervision. Local supervision is applied on the two DRN submodules, and global supervision is applied on the data fusion submodule of the proposed model. Consequently, we both enable feature sharing across task-specific DRN models and control the image restoration behavior of the DRN submodules. An ablation study shows the strength of the hypothesized CMUDRN model, and experiments indicate that its performance is comparable or better than baseline DRN models on the single image deraining and desnowing tasks. Moreover, CMUDRN enables blind image restoration for the two underlying image restoration tasks, by unifying task-specific image restoration pipelines via a naive parametric fusion scheme. The CMUDRN implementation is available at https://github.com/VCL3D/CMUDRN.
Towards Full-to-Empty Room Generation with Structure-Aware Feature Encoding and Soft Semantic Region-Adaptive Normalization
Dec 10, 2021


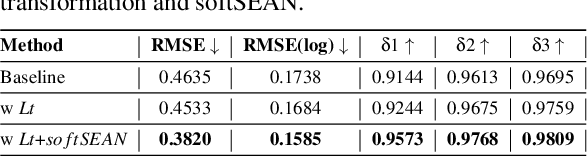
The task of transforming a furnished room image into a background-only is extremely challenging since it requires making large changes regarding the scene context while still preserving the overall layout and style. In order to acquire photo-realistic and structural consistent background, existing deep learning methods either employ image inpainting approaches or incorporate the learning of the scene layout as an individual task and leverage it later in a not fully differentiable semantic region-adaptive normalization module. To tackle these drawbacks, we treat scene layout generation as a feature linear transformation problem and propose a simple yet effective adjusted fully differentiable soft semantic region-adaptive normalization module (softSEAN) block. We showcase the applicability in diminished reality and depth estimation tasks, where our approach besides the advantages of mitigating training complexity and non-differentiability issues, surpasses the compared methods both quantitatively and qualitatively. Our softSEAN block can be used as a drop-in module for existing discriminative and generative models. Implementation is available on vcl3d.github.io/PanoDR/.
Deep Soft Procrustes for Markerless Volumetric Sensor Alignment
Mar 23, 2020



With the advent of consumer grade depth sensors, low-cost volumetric capture systems are easier to deploy. Their wider adoption though depends on their usability and by extension on the practicality of spatially aligning multiple sensors. Most existing alignment approaches employ visual patterns, e.g. checkerboards, or markers and require high user involvement and technical knowledge. More user-friendly and easier-to-use approaches rely on markerless methods that exploit geometric patterns of a physical structure. However, current SoA approaches are bounded by restrictions in the placement and the number of sensors. In this work, we improve markerless data-driven correspondence estimation to achieve more robust and flexible multi-sensor spatial alignment. In particular, we incorporate geometric constraints in an end-to-end manner into a typical segmentation based model and bridge the intermediate dense classification task with the targeted pose estimation one. This is accomplished by a soft, differentiable procrustes analysis that regularizes the segmentation and achieves higher extrinsic calibration performance in expanded sensor placement configurations, while being unrestricted by the number of sensors of the volumetric capture system. Our model is experimentally shown to achieve similar results with marker-based methods and outperform the markerless ones, while also being robust to the pose variations of the calibration structure. Code and pretrained models are available at https://vcl3d.github.io/StructureNet/.
Self-Supervised Deep Depth Denoising
Sep 04, 2019
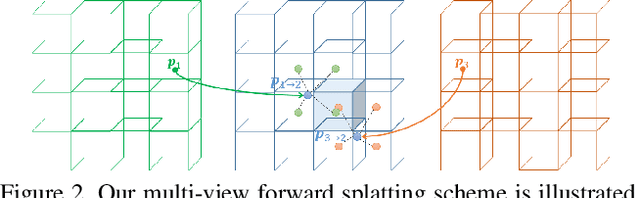
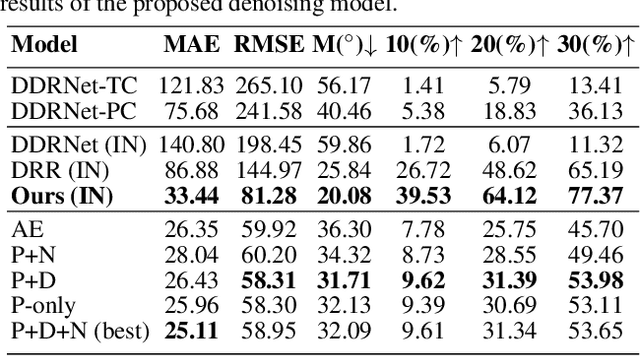
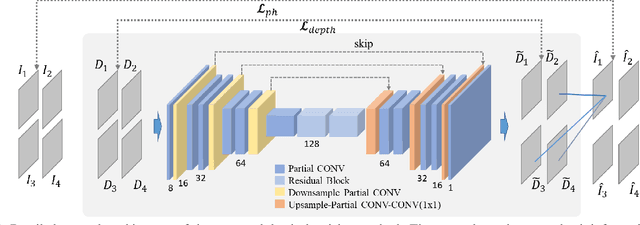
Depth perception is considered an invaluable source of information for various vision tasks. However, depth maps acquired using consumer-level sensors still suffer from non-negligible noise. This fact has recently motivated researchers to exploit traditional filters, as well as the deep learning paradigm, in order to suppress the aforementioned non-uniform noise, while preserving geometric details. Despite the effort, deep depth denoising is still an open challenge mainly due to the lack of clean data that could be used as ground truth. In this paper, we propose a fully convolutional deep autoencoder that learns to denoise depth maps, surpassing the lack of ground truth data. Specifically, the proposed autoencoder exploits multiple views of the same scene from different points of view in order to learn to suppress noise in a self-supervised end-to-end manner using depth and color information during training, yet only depth during inference. To enforce selfsupervision, we leverage a differentiable rendering technique to exploit photometric supervision, which is further regularized using geometric and surface priors. As the proposed approach relies on raw data acquisition, a large RGB-D corpus is collected using Intel RealSense sensors. Complementary to a quantitative evaluation, we demonstrate the effectiveness of the proposed self-supervised denoising approach on established 3D reconstruction applications. Code is avalable at https://github.com/VCL3D/DeepDepthDenoising
A Low-Cost, Flexible and Portable Volumetric Capturing System
Sep 03, 2019



Multi-view capture systems are complex systems to engineer. They require technical knowledge to install and intricate processes to setup related mainly to the sensors' spatial alignment (i.e. external calibration). However, with the ongoing developments in new production methods, we are now at a position where the production of high quality realistic 3D assets is possible even with commodity sensors. Nonetheless, the capturing systems developed with these methods are heavily intertwined with the methods themselves, relying on custom solutions and seldom - if not at all - publicly available. In light of this, we design, develop and publicly offer a multi-view capture system based on the latest RGB-D sensor technology. For our system, we develop a portable and easy-to-use external calibration method that greatly reduces the effort and knowledge required, as well as simplify the overall process.
Non-linear Convolution Filters for CNN-based Learning
Aug 23, 2017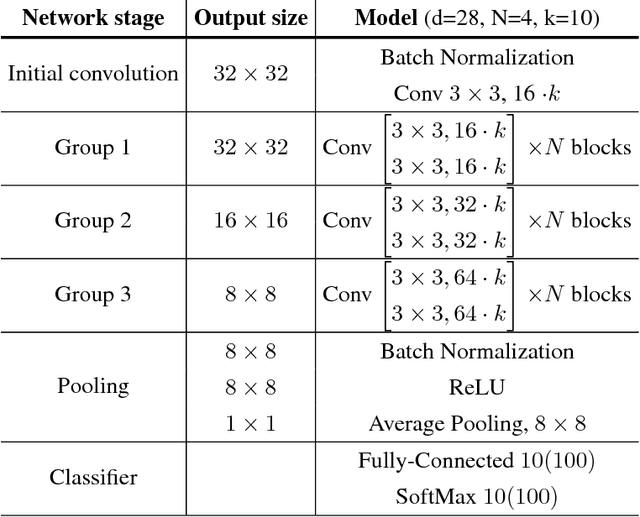
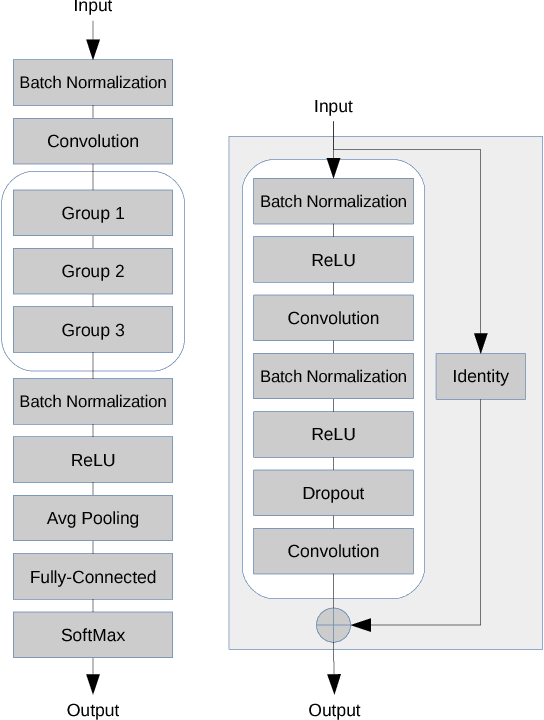
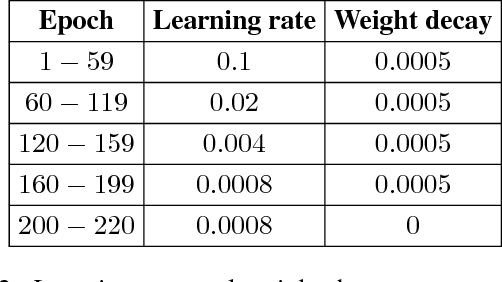
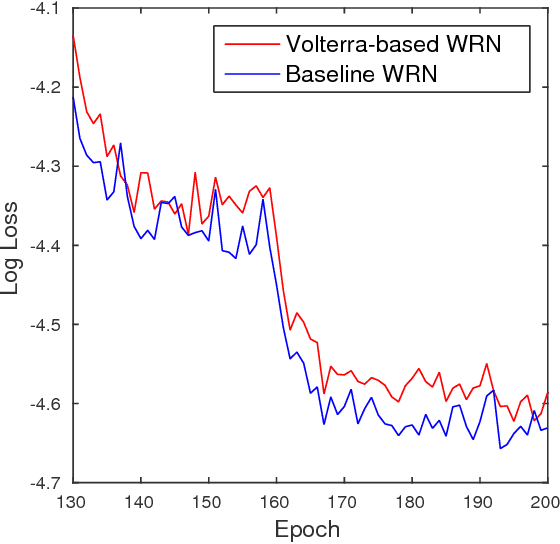
During the last years, Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance in image classification. Their architectures have largely drawn inspiration by models of the primate visual system. However, while recent research results of neuroscience prove the existence of non-linear operations in the response of complex visual cells, little effort has been devoted to extend the convolution technique to non-linear forms. Typical convolutional layers are linear systems, hence their expressiveness is limited. To overcome this, various non-linearities have been used as activation functions inside CNNs, while also many pooling strategies have been applied. We address the issue of developing a convolution method in the context of a computational model of the visual cortex, exploring quadratic forms through the Volterra kernels. Such forms, constituting a more rich function space, are used as approximations of the response profile of visual cells. Our proposed second-order convolution is tested on CIFAR-10 and CIFAR-100. We show that a network which combines linear and non-linear filters in its convolutional layers, can outperform networks that use standard linear filters with the same architecture, yielding results competitive with the state-of-the-art on these datasets.