 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Full-to-Empty Room Generation with Structure-Aware Feature Encoding and Soft Semantic Region-Adaptive Normalization
Dec 10, 2021


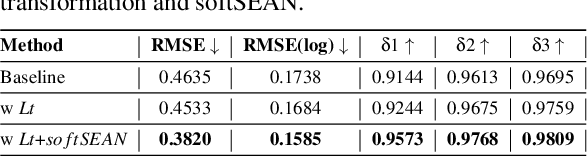
The task of transforming a furnished room image into a background-only is extremely challenging since it requires making large changes regarding the scene context while still preserving the overall layout and style. In order to acquire photo-realistic and structural consistent background, existing deep learning methods either employ image inpainting approaches or incorporate the learning of the scene layout as an individual task and leverage it later in a not fully differentiable semantic region-adaptive normalization module. To tackle these drawbacks, we treat scene layout generation as a feature linear transformation problem and propose a simple yet effective adjusted fully differentiable soft semantic region-adaptive normalization module (softSEAN) block. We showcase the applicability in diminished reality and depth estimation tasks, where our approach besides the advantages of mitigating training complexity and non-differentiability issues, surpasses the compared methods both quantitatively and qualitatively. Our softSEAN block can be used as a drop-in module for existing discriminative and generative models. Implementation is available on vcl3d.github.io/PanoDR/.
Pano3D: A Holistic Benchmark and a Solid Baseline for $360^o$ Depth Estimation
Sep 06, 2021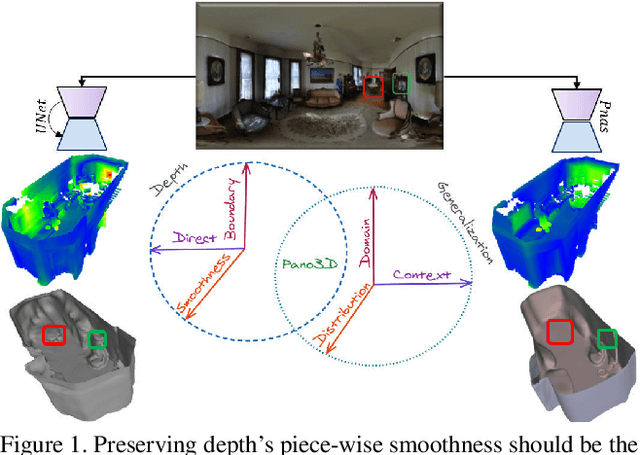
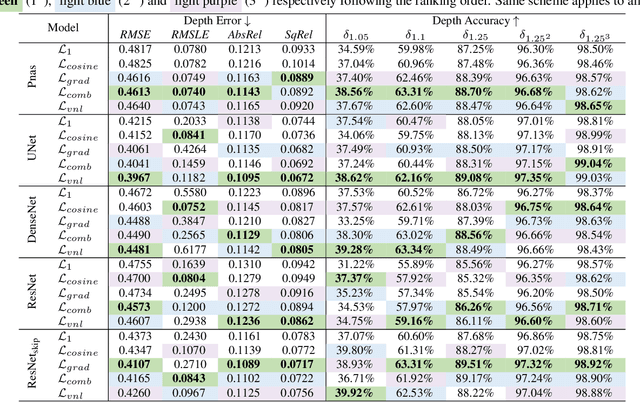

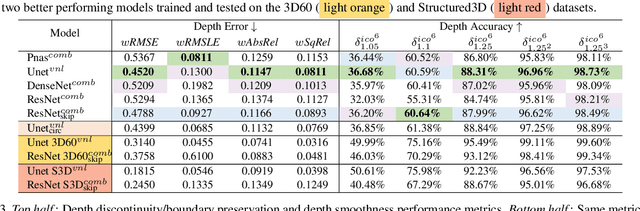
Pano3D is a new benchmark for depth estimation from spherical panoramas. It aims to assess performance across all depth estimation traits, the primary direct depth estimation performance targeting precision and accuracy, and also the secondary traits, boundary preservation, and smoothness. Moreover, Pano3D moves beyond typical intra-dataset evaluation to inter-dataset performance assessment. By disentangling the capacity to generalize to unseen data into different test splits, Pano3D represents a holistic benchmark for $360^o$ depth estimation. We use it as a basis for an extended analysis seeking to offer insights into classical choices for depth estimation. This results in a solid baseline for panoramic depth that follow-up works can build upon to steer future progress.
Deep Lighting Environment Map Estimation from Spherical Panoramas
May 16, 2020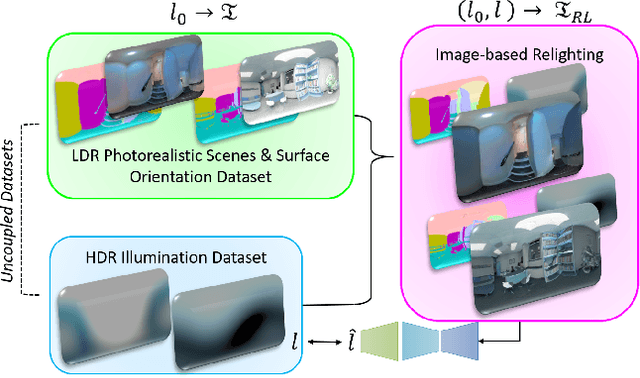
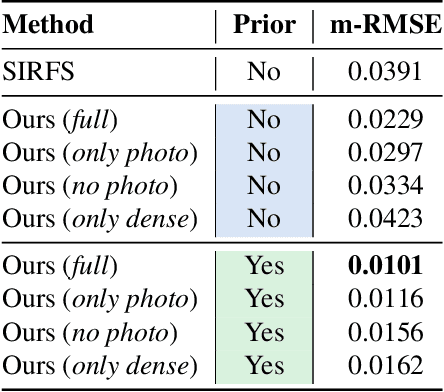


Estimating a scene's lighting is a very important task when compositing synthetic content within real environments, with applications in mixed reality and post-production. In this work we present a data-driven model that estimates an HDR lighting environment map from a single LDR monocular spherical panorama. In addition to being a challenging and ill-posed problem, the lighting estimation task also suffers from a lack of facile illumination ground truth data, a fact that hinders the applicability of data-driven methods. We approach this problem differently, exploiting the availability of surface geometry to employ image-based relighting as a data generator and supervision mechanism. This relies on a global Lambertian assumption that helps us overcome issues related to pre-baked lighting. We relight our training data and complement the model's supervision with a photometric loss, enabled by a differentiable image-based relighting technique. Finally, since we predict spherical spectral coefficients, we show that by imposing a distribution prior on the predicted coefficients, we can greatly boost performance. Code and models available at https://vcl3d.github.io/DeepPanoramaLighting.
Restyling Data: Application to Unsupervised Domain Adaptation
Sep 24, 2019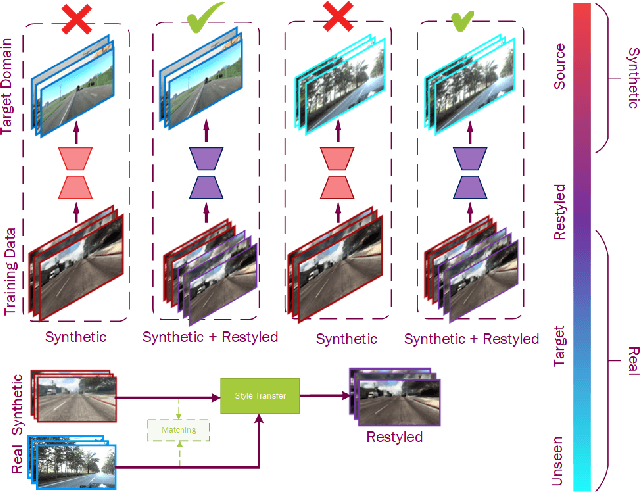



Machine learning is driven by data, yet while their availability is constantly increasing, training data require laborious, time consuming and error-prone labelling or ground truth acquisition, which in some cases is very difficult or even impossible. Recent works have resorted to synthetic data generation, but the inferior performance of models trained on synthetic data when applied to the real world, introduced the challenge of unsupervised domain adaptation. In this work we investigate an unsupervised domain adaptation technique that descends from another perspective, in order to avoid the complexity of adversarial training and cycle consistencies. We exploit the recent advances in photorealistic style transfer and take a fully data driven approach. While this concept is already implicitly formulated within the intricate objectives of domain adaptation GANs, we take an explicit approach and apply it directly as data pre-processing. The resulting technique is scalable, efficient and easy to implement, offers competitive performance to the complex state-of-the-art alternatives and can open up new pathways for domain adaptation.
$360^o$ Surface Regression with a Hyper-Sphere Loss
Sep 16, 2019

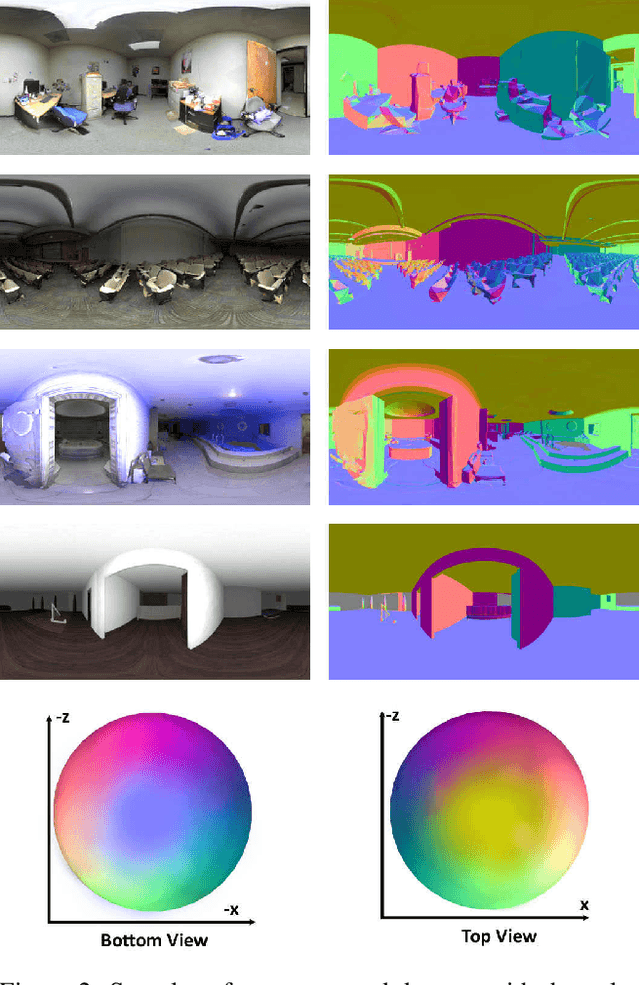
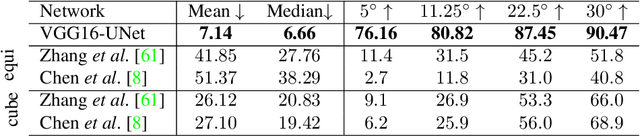
Omnidirectional vision is becoming increasingly relevant as more efficient $360^o$ image acquisition is now possible. However, the lack of annotated $360^o$ datasets has hindered the application of deep learning techniques on spherical content. This is further exaggerated on tasks where ground truth acquisition is difficult, such as monocular surface estimation. While recent research approaches on the 2D domain overcome this challenge by relying on generating normals from depth cues using RGB-D sensors, this is very difficult to apply on the spherical domain. In this work, we address the unavailability of sufficient $360^o$ ground truth normal data, by leveraging existing 3D datasets and remodelling them via rendering. We present a dataset of $360^o$ images of indoor spaces with their corresponding ground truth surface normal, and train a deep convolutional neural network (CNN) on the task of monocular 360 surface estimation. We achieve this by minimizing a novel angular loss function defined on the hyper-sphere using simple quaternion algebra. We put an effort to appropriately compare with other state of the art methods trained on planar datasets and finally, present the practical applicability of our trained model on a spherical image re-lighting task using completely unseen data by qualitatively showing the promising generalization ability of our dataset and model. The dataset is available at: vcl3d.github.io/HyperSphereSurfaceRegression.