 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022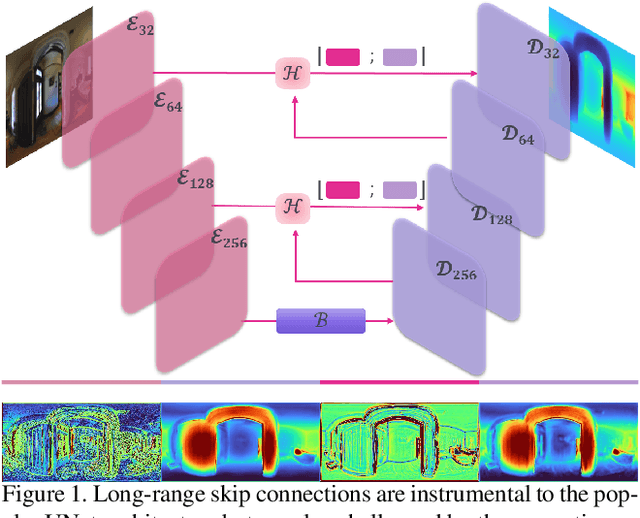

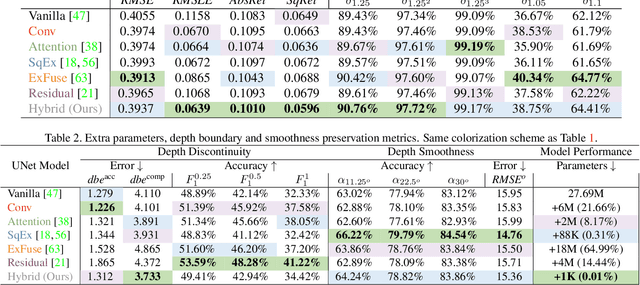
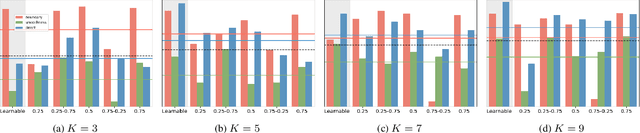
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
Monocular Spherical Depth Estimation with Explicitly Connected Weak Layout Cues
Jun 22, 2022
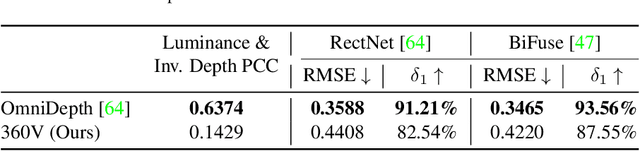
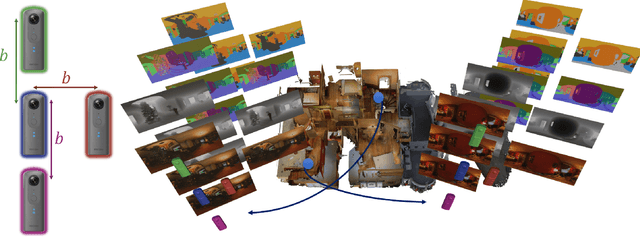

Spherical cameras capture scenes in a holistic manner and have been used for room layout estimation. Recently, with the availability of appropriate datasets, there has also been progress in depth estimation from a single omnidirectional image. While these two tasks are complementary, few works have been able to explore them in parallel to advance indoor geometric perception, and those that have done so either relied on synthetic data, or used small scale datasets, as few options are available that include both layout annotations and dense depth maps in real scenes. This is partly due to the necessity of manual annotations for room layouts. In this work, we move beyond this limitation and generate a 360 geometric vision (360V) dataset that includes multiple modalities, multi-view stereo data and automatically generated weak layout cues. We also explore an explicit coupling between the two tasks to integrate them into a singleshot trained model. We rely on depth-based layout reconstruction and layout-based depth attention, demonstrating increased performance across both tasks. By using single 360 cameras to scan rooms, the opportunity for facile and quick building-scale 3D scanning arises.
* Project page at https://vcl3d.github.io/ExplicitLayoutDepth/
A benchmark with decomposed distribution shifts for 360 monocular depth estimation
Dec 01, 2021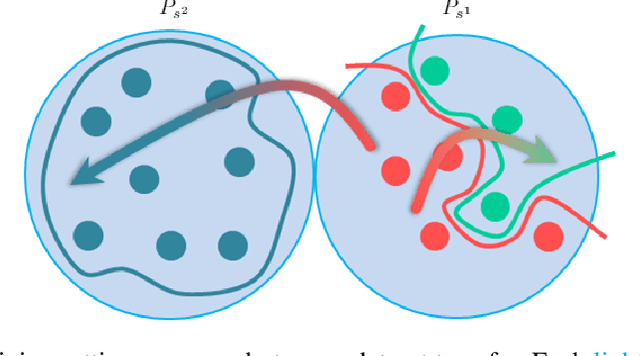



In this work we contribute a distribution shift benchmark for a computer vision task; monocular depth estimation. Our differentiation is the decomposition of the wider distribution shift of uncontrolled testing on in-the-wild data, to three distinct distribution shifts. Specifically, we generate data via synthesis and analyze them to produce covariate (color input), prior (depth output) and concept (their relationship) distribution shifts. We also synthesize combinations and show how each one is indeed a different challenge to address, as stacking them produces increased performance drops and cannot be addressed horizontally using standard approaches.
Pano3D: A Holistic Benchmark and a Solid Baseline for $360^o$ Depth Estimation
Sep 06, 2021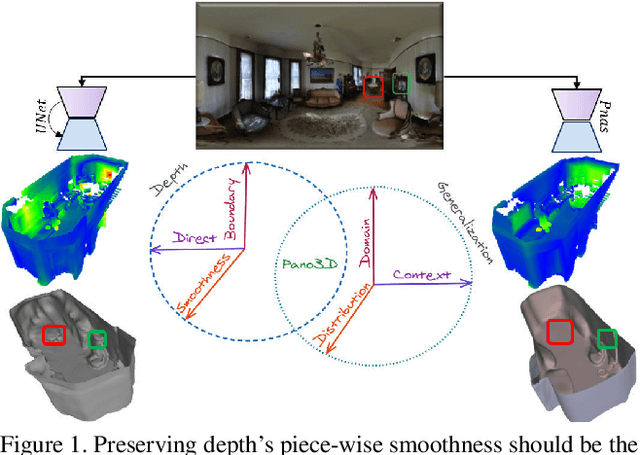
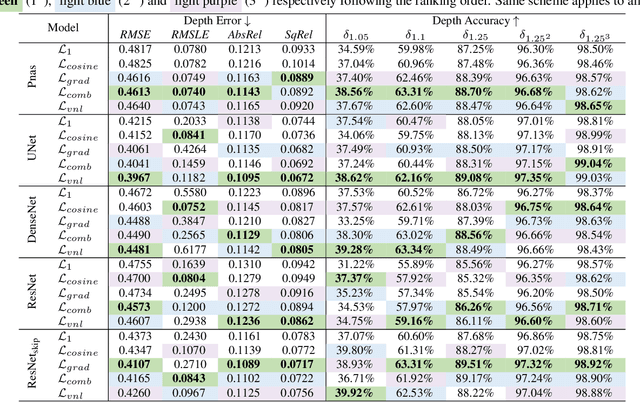

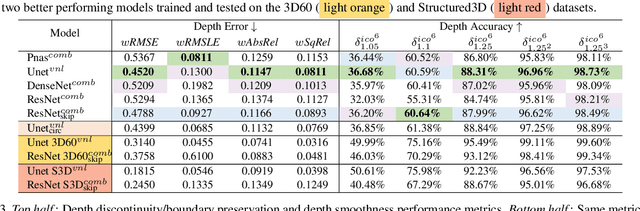
Pano3D is a new benchmark for depth estimation from spherical panoramas. It aims to assess performance across all depth estimation traits, the primary direct depth estimation performance targeting precision and accuracy, and also the secondary traits, boundary preservation, and smoothness. Moreover, Pano3D moves beyond typical intra-dataset evaluation to inter-dataset performance assessment. By disentangling the capacity to generalize to unseen data into different test splits, Pano3D represents a holistic benchmark for $360^o$ depth estimation. We use it as a basis for an extended analysis seeking to offer insights into classical choices for depth estimation. This results in a solid baseline for panoramic depth that follow-up works can build upon to steer future progress.
Single-Shot Cuboids: Geodesics-based End-to-end Manhattan Aligned Layout Estimation from Spherical Panoramas
Feb 09, 2021
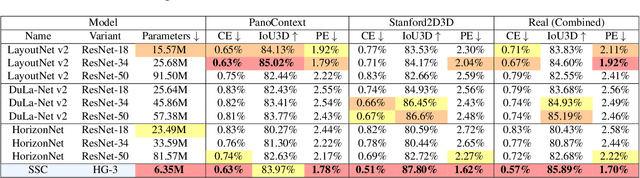


It has been shown that global scene understanding tasks like layout estimation can benefit from wider field of views, and specifically spherical panoramas. While much progress has been made recently, all previous approaches rely on intermediate representations and postprocessing to produce Manhattan-aligned estimates. In this work we show how to estimate full room layouts in a single-shot, eliminating the need for postprocessing. Our work is the first to directly infer Manhattan-aligned outputs. To achieve this, our data-driven model exploits direct coordinate regression and is supervised end-to-end. As a result, we can explicitly add quasi-Manhattan constraints, which set the necessary conditions for a homography-based Manhattan alignment module. Finally, we introduce the geodesic heatmaps and loss and a boundary-aware center of mass calculation that facilitate higher quality keypoint estimation in the spherical domain. Our models and code are publicly available at https://vcl3d.github.io/SingleShotCuboids/.
Deep Lighting Environment Map Estimation from Spherical Panoramas
May 16, 2020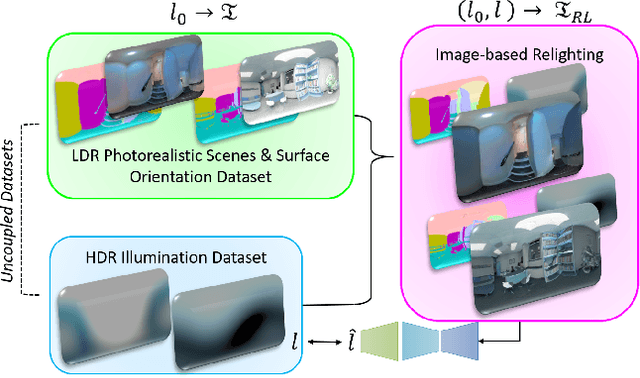
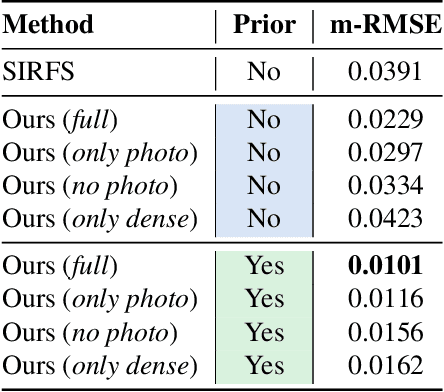


Estimating a scene's lighting is a very important task when compositing synthetic content within real environments, with applications in mixed reality and post-production. In this work we present a data-driven model that estimates an HDR lighting environment map from a single LDR monocular spherical panorama. In addition to being a challenging and ill-posed problem, the lighting estimation task also suffers from a lack of facile illumination ground truth data, a fact that hinders the applicability of data-driven methods. We approach this problem differently, exploiting the availability of surface geometry to employ image-based relighting as a data generator and supervision mechanism. This relies on a global Lambertian assumption that helps us overcome issues related to pre-baked lighting. We relight our training data and complement the model's supervision with a photometric loss, enabled by a differentiable image-based relighting technique. Finally, since we predict spherical spectral coefficients, we show that by imposing a distribution prior on the predicted coefficients, we can greatly boost performance. Code and models available at https://vcl3d.github.io/DeepPanoramaLighting.
Spherical View Synthesis for Self-Supervised 360 Depth Estimation
Sep 17, 2019
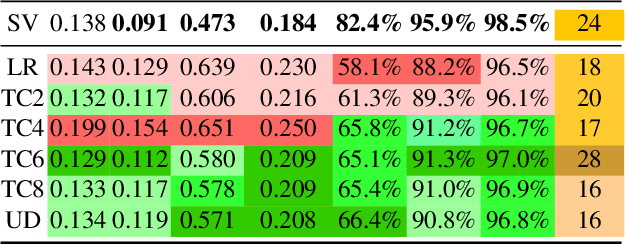

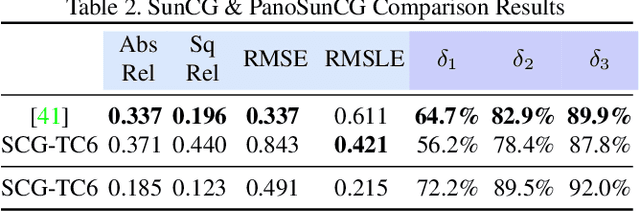
Learning based approaches for depth perception are limited by the availability of clean training data. This has led to the utilization of view synthesis as an indirect objective for learning depth estimation using efficient data acquisition procedures. Nonetheless, most research focuses on pinhole based monocular vision, with scarce works presenting results for omnidirectional input. In this work, we explore spherical view synthesis for learning monocular 360 depth in a self-supervised manner and demonstrate its feasibility. Under a purely geometrically derived formulation we present results for horizontal and vertical baselines, as well as for the trinocular case. Further, we show how to better exploit the expressiveness of traditional CNNs when applied to the equirectangular domain in an efficient manner. Finally, given the availability of ground truth depth data, our work is uniquely positioned to compare view synthesis against direct supervision in a consistent and fair manner. The results indicate that alternative research directions might be better suited to enable higher quality depth perception. Our data, models and code are publicly available at https://vcl3d.github.io/SphericalViewSynthesis/.