 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Single-shot Motion Synthesis
Jun 04, 2024Despite the recent advances in the so-called "cold start" generation from text prompts, their needs in data and computing resources, as well as the ambiguities around intellectual property and privacy concerns pose certain counterarguments for their utility. An interesting and relatively unexplored alternative has been the introduction of unconditional synthesis from a single sample, which has led to interesting generative applications. In this paper we focus on single-shot motion generation and more specifically on accelerating the training time of a Generative Adversarial Network (GAN). In particular, we tackle the challenge of GAN's equilibrium collapse when using mini-batch training by carefully annealing the weights of the loss functions that prevent mode collapse. Additionally, we perform statistical analysis in the generator and discriminator models to identify correlations between training stages and enable transfer learning. Our improved GAN achieves competitive quality and diversity on the Mixamo benchmark when compared to the original GAN architecture and a single-shot diffusion model, while being up to x6.8 faster in training time from the former and x1.75 from the latter. Finally, we demonstrate the ability of our improved GAN to mix and compose motion with a single forward pass. Project page available at https://moverseai.github.io/single-shot.
BundleMoCap: Efficient, Robust and Smooth Motion Capture from Sparse Multiview Videos
Nov 21, 2023



Capturing smooth motions from videos using markerless techniques typically involves complex processes such as temporal constraints, multiple stages with data-driven regression and optimization, and bundle solving over temporal windows. These processes can be inefficient and require tuning multiple objectives across stages. In contrast, BundleMoCap introduces a novel and efficient approach to this problem. It solves the motion capture task in a single stage, eliminating the need for temporal smoothness objectives while still delivering smooth motions. BundleMoCap outperforms the state-of-the-art without increasing complexity. The key concept behind BundleMoCap is manifold interpolation between latent keyframes. By relying on a local manifold smoothness assumption, we can efficiently solve a bundle of frames using a single code. Additionally, the method can be implemented as a sliding window optimization and requires only the first frame to be properly initialized, reducing the overall computational burden. BundleMoCap's strength lies in its ability to achieve high-quality motion capture results with simplicity and efficiency. More details can be found at https://moverseai.github.io/bundle/.
Noise-in, Bias-out: Balanced and Real-time MoCap Solving
Sep 25, 2023



Real-time optical Motion Capture (MoCap) systems have not benefited from the advances in modern data-driven modeling. In this work we apply machine learning to solve noisy unstructured marker estimates in real-time and deliver robust marker-based MoCap even when using sparse affordable sensors. To achieve this we focus on a number of challenges related to model training, namely the sourcing of training data and their long-tailed distribution. Leveraging representation learning we design a technique for imbalanced regression that requires no additional data or labels and improves the performance of our model in rare and challenging poses. By relying on a unified representation, we show that training such a model is not bound to high-end MoCap training data acquisition, and exploit the advances in marker-less MoCap to acquire the necessary data. Finally, we take a step towards richer and affordable MoCap by adapting a body model-based inverse kinematics solution to account for measurement and inference uncertainty, further improving performance and robustness. Project page: https://moverseai.github.io/noise-tail
KBody: Towards general, robust, and aligned monocular whole-body estimation
Apr 25, 2023KBody is a method for fitting a low-dimensional body model to an image. It follows a predict-and-optimize approach, relying on data-driven model estimates for the constraints that will be used to solve for the body's parameters. Acknowledging the importance of high quality correspondences, it leverages ``virtual joints" to improve fitting performance, disentangles the optimization between the pose and shape parameters, and integrates asymmetric distance fields to strike a balance in terms of pose and shape capturing capacity, as well as pixel alignment. We also show that generative model inversion offers a strong appearance prior that can be used to complete partial human images and used as a building block for generalized and robust monocular body fitting. Project page: https://klothed.github.io/KBody.
* 11 pages, 6 figures, 58 supplemental figures, project page https://klothed.github.io/KBody , also posted at with high-res images http://graphics.berkeley.edu/papers/Zioulis-KBT-2023-06
Hybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022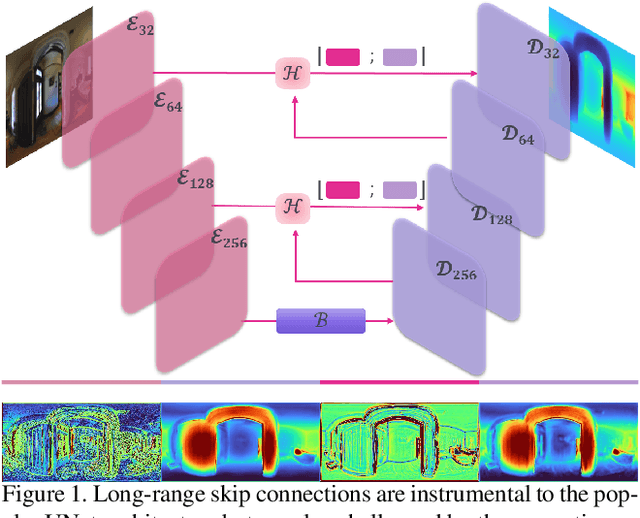

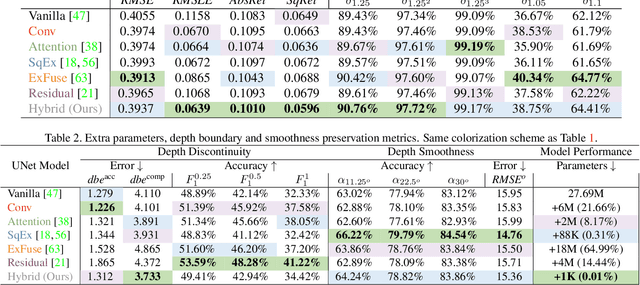
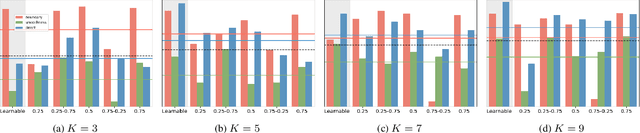
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
Monocular Spherical Depth Estimation with Explicitly Connected Weak Layout Cues
Jun 22, 2022
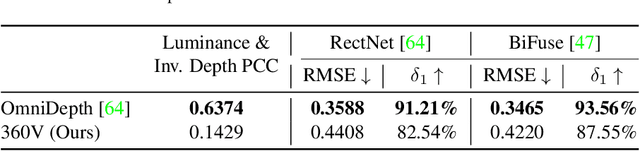
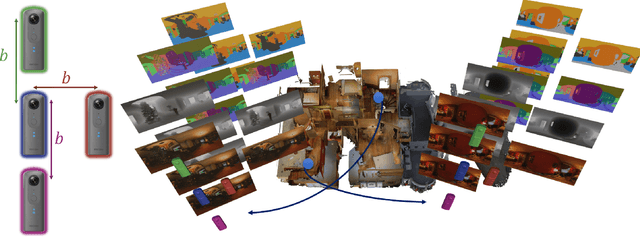

Spherical cameras capture scenes in a holistic manner and have been used for room layout estimation. Recently, with the availability of appropriate datasets, there has also been progress in depth estimation from a single omnidirectional image. While these two tasks are complementary, few works have been able to explore them in parallel to advance indoor geometric perception, and those that have done so either relied on synthetic data, or used small scale datasets, as few options are available that include both layout annotations and dense depth maps in real scenes. This is partly due to the necessity of manual annotations for room layouts. In this work, we move beyond this limitation and generate a 360 geometric vision (360V) dataset that includes multiple modalities, multi-view stereo data and automatically generated weak layout cues. We also explore an explicit coupling between the two tasks to integrate them into a singleshot trained model. We rely on depth-based layout reconstruction and layout-based depth attention, demonstrating increased performance across both tasks. By using single 360 cameras to scan rooms, the opportunity for facile and quick building-scale 3D scanning arises.
* Project page at https://vcl3d.github.io/ExplicitLayoutDepth/
Towards Full-to-Empty Room Generation with Structure-Aware Feature Encoding and Soft Semantic Region-Adaptive Normalization
Dec 10, 2021


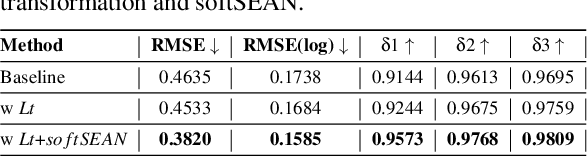
The task of transforming a furnished room image into a background-only is extremely challenging since it requires making large changes regarding the scene context while still preserving the overall layout and style. In order to acquire photo-realistic and structural consistent background, existing deep learning methods either employ image inpainting approaches or incorporate the learning of the scene layout as an individual task and leverage it later in a not fully differentiable semantic region-adaptive normalization module. To tackle these drawbacks, we treat scene layout generation as a feature linear transformation problem and propose a simple yet effective adjusted fully differentiable soft semantic region-adaptive normalization module (softSEAN) block. We showcase the applicability in diminished reality and depth estimation tasks, where our approach besides the advantages of mitigating training complexity and non-differentiability issues, surpasses the compared methods both quantitatively and qualitatively. Our softSEAN block can be used as a drop-in module for existing discriminative and generative models. Implementation is available on vcl3d.github.io/PanoDR/.
A benchmark with decomposed distribution shifts for 360 monocular depth estimation
Dec 01, 2021



In this work we contribute a distribution shift benchmark for a computer vision task; monocular depth estimation. Our differentiation is the decomposition of the wider distribution shift of uncontrolled testing on in-the-wild data, to three distinct distribution shifts. Specifically, we generate data via synthesis and analyze them to produce covariate (color input), prior (depth output) and concept (their relationship) distribution shifts. We also synthesize combinations and show how each one is indeed a different challenge to address, as stacking them produces increased performance drops and cannot be addressed horizontally using standard approaches.
On Coordinate Decoding for Keypoint Estimation Tasks
Oct 19, 2021
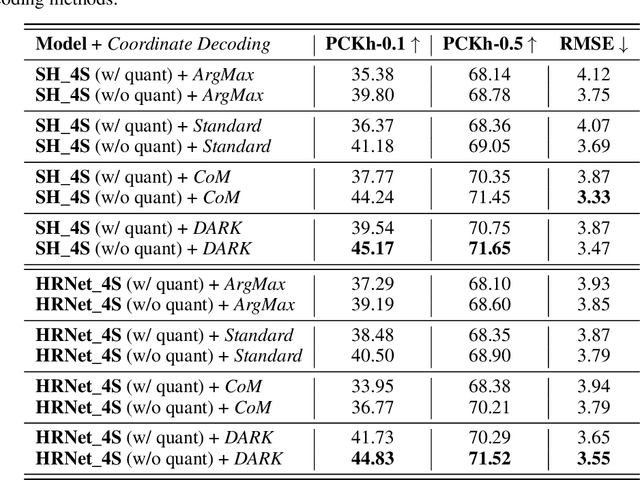


A series of 2D (and 3D) keypoint estimation tasks are built upon heatmap coordinate representation, i.e. a probability map that allows for learnable and spatially aware encoding and decoding of keypoint coordinates on grids, even allowing for sub-pixel coordinate accuracy. In this report, we aim to reproduce the findings of DARK that investigated the 2D heatmap representation by highlighting the importance of the encoding of the ground truth heatmap and the decoding of the predicted heatmap to keypoint coordinates. The authors claim that a) a more principled distribution-aware coordinate decoding method overcomes the limitations of the standard techniques widely used in the literature, and b), that the reconstruction of heatmaps from ground-truth coordinates by generating accurate and continuous heatmap distributions lead to unbiased model training, contrary to the standard coordinate encoding process that quantizes the keypoint coordinates on the resolution of the input image grid.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

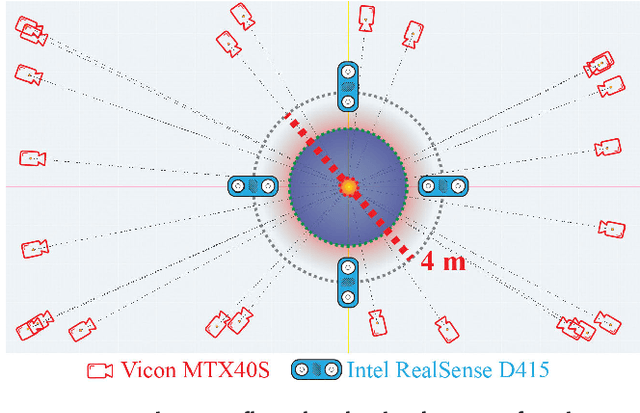
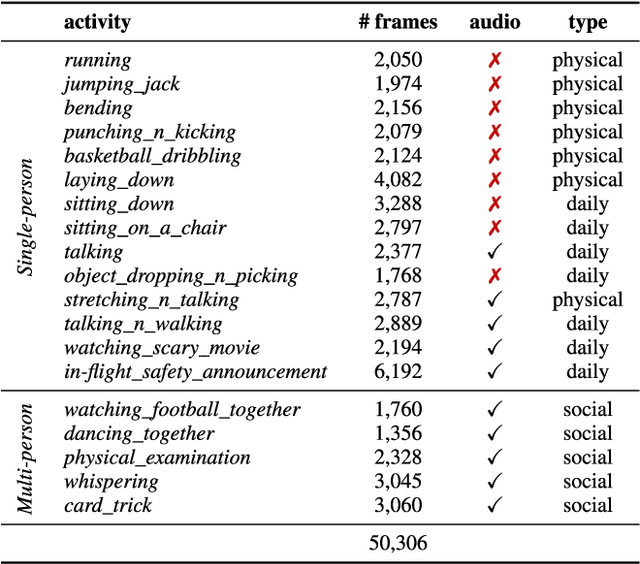
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.