 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Disclosure, Less Trust? How the Level of Detail about AI Use in News Writing Affects Readers' Trust
Jan 14, 2026As artificial intelligence (AI) is increasingly integrated into news production, calls for transparency about the use of AI have gained considerable traction. Recent studies suggest that AI disclosures can lead to a ``transparency dilemma'', where disclosure reduces readers' trust. However, little is known about how the \textit{level of detail} in AI disclosures influences trust and contributes to this dilemma within the news context. In this 3$\times$2$\times$2 mixed factorial study with 40 participants, we investigate how three levels of AI disclosures (none, one-line, detailed) across two types of news (politics and lifestyle) and two levels of AI involvement (low and high) affect news readers' trust. We measured trust using the News Media Trust questionnaire, along with two decision behaviors: source-checking and subscription decisions. Questionnaire responses and subscription rates showed a decline in trust only for detailed AI disclosures, whereas source-checking behavior increased for both one-line and detailed disclosures, with the effect being more pronounced for detailed disclosures. Insights from semi-structured interviews suggest that source-checking behavior was primarily driven by interest in the topic, followed by trust, whereas trust was the main factor influencing subscription decisions. Around two-thirds of participants expressed a preference for detailed disclosures, while most participants who preferred one-line indicated a need for detail-on-demand disclosure formats. Our findings show that not all AI disclosures lead to a transparency dilemma, but instead reflect a trade-off between readers' desire for more transparency and their trust in AI-assisted news content.
Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
May 16, 2024
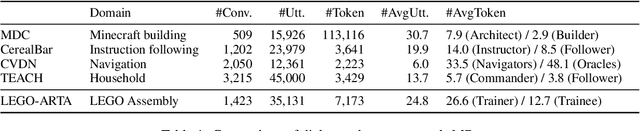
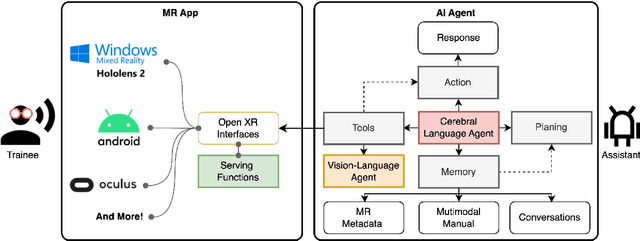

Autonomous artificial intelligence (AI) agents have emerged as promising protocols for automatically understanding the language-based environment, particularly with the exponential development of large language models (LLMs). However, a fine-grained, comprehensive understanding of multimodal environments remains under-explored. This work designs an autonomous workflow tailored for integrating AI agents seamlessly into extended reality (XR) applications for fine-grained training. We present a demonstration of a multimodal fine-grained training assistant for LEGO brick assembly in a pilot XR environment. Specifically, we design a cerebral language agent that integrates LLM with memory, planning, and interaction with XR tools and a vision-language agent, enabling agents to decide their actions based on past experiences. Furthermore, we introduce LEGO-MRTA, a multimodal fine-grained assembly dialogue dataset synthesized automatically in the workflow served by a commercial LLM. This dataset comprises multimodal instruction manuals, conversations, XR responses, and vision question answering. Last, we present several prevailing open-resource LLMs as benchmarks, assessing their performance with and without fine-tuning on the proposed dataset. We anticipate that the broader impact of this workflow will advance the development of smarter assistants for seamless user interaction in XR environments, fostering research in both AI and HCI communities.
PointPCA+: Extending PointPCA objective quality assessment metric
Nov 23, 2023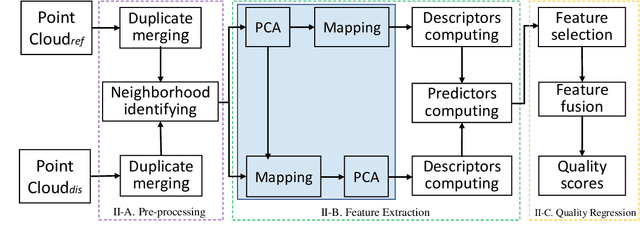


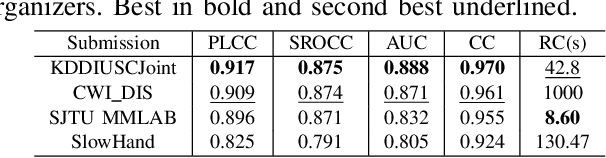
A computationally-simplified and descriptor-richer Point Cloud Quality Assessment (PCQA) metric, namely PointPCA+, is proposed in this paper, which is an extension of PointPCA. PointPCA proposed a set of perceptually-relevant descriptors based on PCA decomposition that were applied to both the geometry and texture data of point clouds for full reference PCQA. PointPCA+ employs PCA only on the geometry data while enriching existing geometry and texture descriptors, that are computed more efficiently. Similarly to PointPCA, a total quality score is obtained through a learning-based fusion of individual predictions from geometry and texture descriptors that capture local shape and appearance properties, respectively. Before feature fusion, a feature selection module is introduced to choose the most effective features from a proposed super-set. Experimental results show that PointPCA+ achieves high predictive performance against subjective ground truth scores obtained from publicly available datasets. The code is available at \url{https://github.com/cwi-dis/pointpca_suite/}.
Volumetric video streaming: Current approaches and implementations
Sep 05, 2022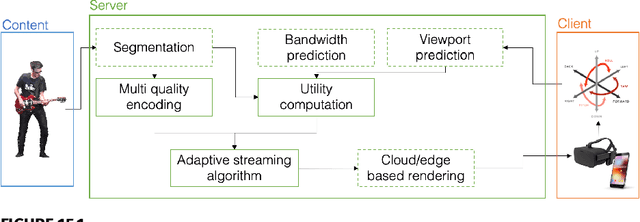

The rise of capturing systems for objects and scenes in 3D with increased fidelity and immersion has led to the popularity of volumetric video contents that can be seen from any position and angle in 6 degrees of freedom navigation. Such contents need large volumes of data to accurately represent the real world. Thus, novel optimization solutions and delivery systems are needed to enable volumetric video streaming over bandwidth-limited networks. In this chapter, we discuss theoretical approaches to volumetric video streaming optimization, through compression solutions, as well as network and user adaptation, for high-end and low-powered devices. Moreover, we present an overview of existing end-to-end systems, and we point to the future of volumetric video streaming.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

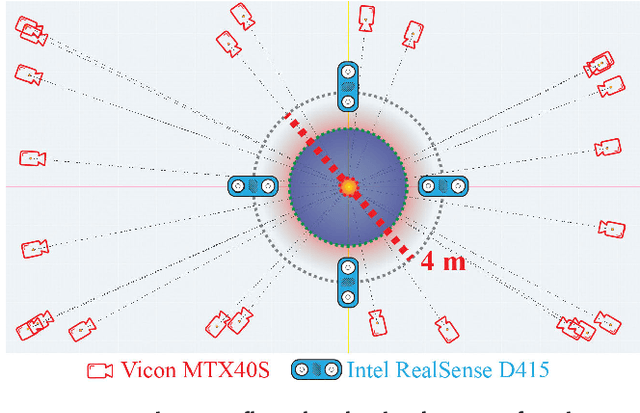
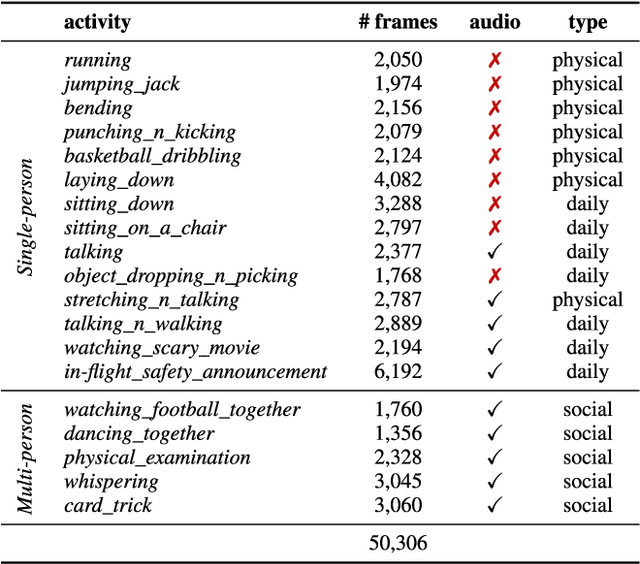
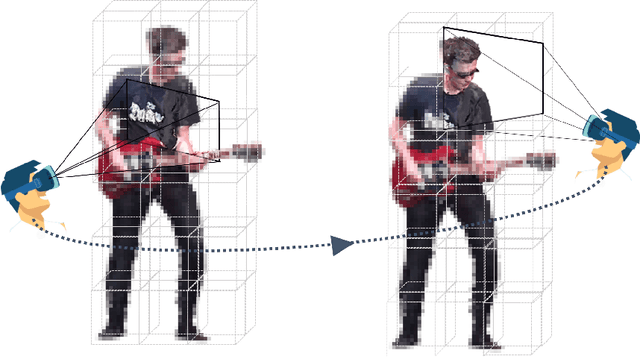
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.