 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashDP: Private Training Large Language Models with Efficient DP-SGD
Jul 01, 2025As large language models (LLMs) increasingly underpin technological advancements, the privacy of their training data emerges as a critical concern. Differential Privacy (DP) serves as a rigorous mechanism to protect this data, yet its integration via Differentially Private Stochastic Gradient Descent (DP-SGD) introduces substantial challenges, primarily due to the complexities of per-sample gradient clipping. Current explicit methods, such as Opacus, necessitate extensive storage for per-sample gradients, significantly inflating memory requirements. Conversely, implicit methods like GhostClip reduce storage needs by recalculating gradients multiple times, which leads to inefficiencies due to redundant computations. This paper introduces FlashDP, an innovative cache-friendly per-layer DP-SGD that consolidates necessary operations into a single task, calculating gradients only once in a fused manner. This approach not only diminishes memory movement by up to \textbf{50\%} but also cuts down redundant computations by \textbf{20\%}, compared to previous methods. Consequently, FlashDP does not increase memory demands and achieves a \textbf{90\%} throughput compared to the Non-DP method on a four-A100 system during the pre-training of the Llama-13B model, while maintaining parity with standard per-layer clipped DP-SGD in terms of accuracy. These advancements establish FlashDP as a pivotal development for efficient and privacy-preserving training of LLMs. FlashDP's code has been open-sourced in https://github.com/kaustpradalab/flashdp.
AnchorFormer: Differentiable Anchor Attention for Efficient Vision Transformer
May 22, 2025Recently, vision transformers (ViTs) have achieved excellent performance on vision tasks by measuring the global self-attention among the image patches. Given $n$ patches, they will have quadratic complexity such as $\mathcal{O}(n^2)$ and the time cost is high when splitting the input image with a small granularity. Meanwhile, the pivotal information is often randomly gathered in a few regions of an input image, some tokens may not be helpful for the downstream tasks. To handle this problem, we introduce an anchor-based efficient vision transformer (AnchorFormer), which employs the anchor tokens to learn the pivotal information and accelerate the inference. Firstly, by estimating the bipartite attention between the anchors and tokens, the complexity will be reduced from $\mathcal{O}(n^2)$ to $\mathcal{O}(mn)$, where $m$ is an anchor number and $m < n$. Notably, by representing the anchors with the neurons in a neural layer, we can differentiable learn these distributions and approximate global self-attention through the Markov process. Moreover, we extend the proposed model to three downstream tasks including classification, detection, and segmentation. Extensive experiments show the effectiveness of our AnchorFormer, e.g., achieving up to a 9.0% higher accuracy or 46.7% FLOPs reduction on ImageNet classification, 81.3% higher mAP on COCO detection under comparable FLOPs, as compared to the current baselines.
ZO2: Scalable Zeroth-Order Fine-Tuning for Extremely Large Language Models with Limited GPU Memory
Mar 16, 2025Fine-tuning large pre-trained LLMs generally demands extensive GPU memory. Traditional first-order optimizers like SGD encounter substantial difficulties due to increased memory requirements from storing activations and gradients during both the forward and backward phases as the model size expands. Alternatively, zeroth-order (ZO) techniques can compute gradients using just forward operations, eliminating the need to store activations. Furthermore, by leveraging CPU capabilities, it's feasible to enhance both the memory and processing power available to a single GPU. We propose a novel framework, ZO2 (Zeroth-Order Offloading), for efficient zeroth-order fine-tuning of LLMs with only limited GPU memory. Our framework dynamically shifts model parameters between the CPU and GPU as required, optimizing computation flow and maximizing GPU usage by minimizing downtime. This integration of parameter adjustments with ZO's double forward operations reduces unnecessary data movement, enhancing the fine-tuning efficacy. Additionally, our framework supports an innovative low-bit precision approach in AMP mode to streamline data exchanges between the CPU and GPU. Employing this approach allows us to fine-tune extraordinarily large models, such as the OPT-175B with more than 175 billion parameters, on a mere 18GB GPU--achievements beyond the reach of traditional methods. Moreover, our framework achieves these results with almost no additional time overhead and absolutely no accuracy loss compared to standard zeroth-order methods. ZO2's code has been open-sourced in https://github.com/liangyuwang/zo2.
MagicGeo: Training-Free Text-Guided Geometric Diagram Generation
Feb 19, 2025Geometric diagrams are critical in conveying mathematical and scientific concepts, yet traditional diagram generation methods are often manual and resource-intensive. While text-to-image generation has made strides in photorealistic imagery, creating accurate geometric diagrams remains a challenge due to the need for precise spatial relationships and the scarcity of geometry-specific datasets. This paper presents MagicGeo, a training-free framework for generating geometric diagrams from textual descriptions. MagicGeo formulates the diagram generation process as a coordinate optimization problem, ensuring geometric correctness through a formal language solver, and then employs coordinate-aware generation. The framework leverages the strong language translation capability of large language models, while formal mathematical solving ensures geometric correctness. We further introduce MagicGeoBench, a benchmark dataset of 220 geometric diagram descriptions, and demonstrate that MagicGeo outperforms current methods in both qualitative and quantitative evaluations. This work provides a scalable, accurate solution for automated diagram generation, with significant implications for educational and academic applications.
Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
May 16, 2024
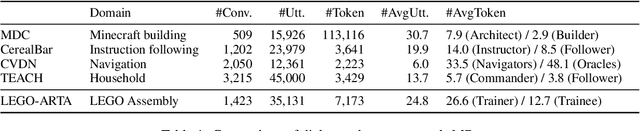
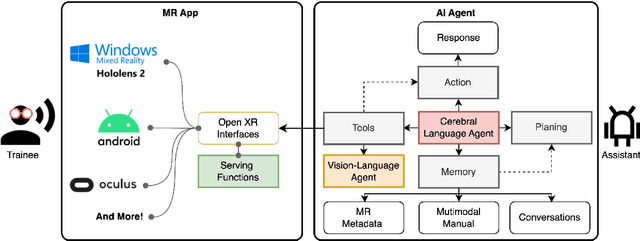

Autonomous artificial intelligence (AI) agents have emerged as promising protocols for automatically understanding the language-based environment, particularly with the exponential development of large language models (LLMs). However, a fine-grained, comprehensive understanding of multimodal environments remains under-explored. This work designs an autonomous workflow tailored for integrating AI agents seamlessly into extended reality (XR) applications for fine-grained training. We present a demonstration of a multimodal fine-grained training assistant for LEGO brick assembly in a pilot XR environment. Specifically, we design a cerebral language agent that integrates LLM with memory, planning, and interaction with XR tools and a vision-language agent, enabling agents to decide their actions based on past experiences. Furthermore, we introduce LEGO-MRTA, a multimodal fine-grained assembly dialogue dataset synthesized automatically in the workflow served by a commercial LLM. This dataset comprises multimodal instruction manuals, conversations, XR responses, and vision question answering. Last, we present several prevailing open-resource LLMs as benchmarks, assessing their performance with and without fine-tuning on the proposed dataset. We anticipate that the broader impact of this workflow will advance the development of smarter assistants for seamless user interaction in XR environments, fostering research in both AI and HCI communities.
On Knowledge Editing in Federated Learning: Perspectives, Challenges, and Future Directions
Jun 02, 2023As Federated Learning (FL) has gained increasing attention, it has become widely acknowledged that straightforwardly applying stochastic gradient descent (SGD) on the overall framework when learning over a sequence of tasks results in the phenomenon known as ``catastrophic forgetting''. Consequently, much FL research has centered on devising federated increasing learning methods to alleviate forgetting while augmenting knowledge. On the other hand, forgetting is not always detrimental. The selective amnesia, also known as federated unlearning, which entails the elimination of specific knowledge, can address privacy concerns and create additional ``space'' for acquiring new knowledge. However, there is a scarcity of extensive surveys that encompass recent advancements and provide a thorough examination of this issue. In this manuscript, we present an extensive survey on the topic of knowledge editing (augmentation/removal) in Federated Learning, with the goal of summarizing the state-of-the-art research and expanding the perspective for various domains. Initially, we introduce an integrated paradigm, referred to as Federated Editable Learning (FEL), by reevaluating the entire lifecycle of FL. Secondly, we provide a comprehensive overview of existing methods, evaluate their position within the proposed paradigm, and emphasize the current challenges they face. Lastly, we explore potential avenues for future research and identify unresolved issues.
DualMix: Unleashing the Potential of Data Augmentation for Online Class-Incremental Learning
Mar 14, 2023



Online Class-Incremental (OCI) learning has sparked new approaches to expand the previously trained model knowledge from sequentially arriving data streams with new classes. Unfortunately, OCI learning can suffer from catastrophic forgetting (CF) as the decision boundaries for old classes can become inaccurate when perturbated by new ones. Existing literature have applied the data augmentation (DA) to alleviate the model forgetting, while the role of DA in OCI has not been well understood so far. In this paper, we theoretically show that augmented samples with lower correlation to the original data are more effective in preventing forgetting. However, aggressive augmentation may also reduce the consistency between data and corresponding labels, which motivates us to exploit proper DA to boost the OCI performance and prevent the CF problem. We propose the Enhanced Mixup (EnMix) method that mixes the augmented samples and their labels simultaneously, which is shown to enhance the sample diversity while maintaining strong consistency with corresponding labels. Further, to solve the class imbalance problem, we design an Adaptive Mixup (AdpMix) method to calibrate the decision boundaries by mixing samples from both old and new classes and dynamically adjusting the label mixing ratio. Our approach is demonstrated to be effective on several benchmark datasets through extensive experiments, and it is shown to be compatible with other replay-based techniques.
FedTune: A Deep Dive into Efficient Federated Fine-Tuning with Pre-trained Transformers
Nov 15, 2022Federated Learning (FL) is an emerging paradigm that enables distributed users to collaboratively and iteratively train machine learning models without sharing their private data. Motivated by the effectiveness and robustness of self-attention-based architectures, researchers are turning to using pre-trained Transformers (i.e., foundation models) instead of traditional convolutional neural networks in FL to leverage their excellent transfer learning capabilities. Despite recent progress, how pre-trained Transformer models play a role in FL remains obscure, that is, how to efficiently fine-tune these pre-trained models in FL and how FL users could benefit from this new paradigm. In this paper, we explore this issue and demonstrate that the fine-tuned Transformers achieve extraordinary performance on FL, and that the lightweight fine-tuning method facilitates a fast convergence rate and low communication costs. Concretely, we conduct a rigorous empirical study of three tuning methods (i.e., modifying the input, adding extra modules, and adjusting the backbone) using two types of pre-trained models (i.e., vision-language models and vision models) for FL. Our experiments show that 1) Fine-tuning the bias term of the backbone performs best when relying on a strong pre-trained model; 2) The vision-language model (e.g., CLIP) outperforms the pure vision model (e.g., ViT) and is more robust to the few-shot settings; 3) Compared to pure local training, FL with pre-trained models has a higher accuracy because it alleviates the problem of over-fitting. We will release our code and encourage further exploration of pre-trained Transformers and FL.
PMR: Prototypical Modal Rebalance for Multimodal Learning
Nov 14, 2022



Multimodal learning (MML) aims to jointly exploit the common priors of different modalities to compensate for their inherent limitations. However, existing MML methods often optimize a uniform objective for different modalities, leading to the notorious "modality imbalance" problem and counterproductive MML performance. To address the problem, some existing methods modulate the learning pace based on the fused modality, which is dominated by the better modality and eventually results in a limited improvement on the worse modal. To better exploit the features of multimodal, we propose Prototypical Modality Rebalance (PMR) to perform stimulation on the particular slow-learning modality without interference from other modalities. Specifically, we introduce the prototypes that represent general features for each class, to build the non-parametric classifiers for uni-modal performance evaluation. Then, we try to accelerate the slow-learning modality by enhancing its clustering toward prototypes. Furthermore, to alleviate the suppression from the dominant modality, we introduce a prototype-based entropy regularization term during the early training stage to prevent premature convergence. Besides, our method only relies on the representations of each modality and without restrictions from model structures and fusion methods, making it with great application potential for various scenarios.
Demystify Self-Attention in Vision Transformers from a Semantic Perspective: Analysis and Application
Nov 13, 2022


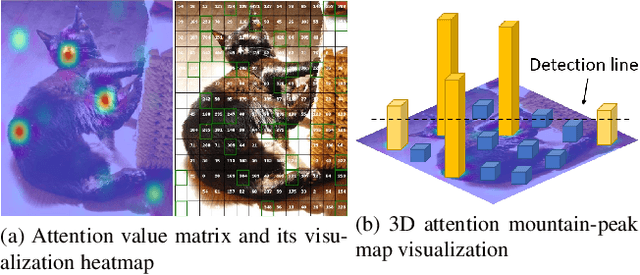
Self-attention mechanisms, especially multi-head self-attention (MSA), have achieved great success in many fields such as computer vision and natural language processing. However, many existing vision transformer (ViT) works simply inherent transformer designs from NLP to adapt vision tasks, while ignoring the fundamental difference between ``how MSA works in image and language settings''. Language naturally contains highly semantic structures that are directly interpretable by humans. Its basic unit (word) is discrete without redundant information, which readily supports interpretable studies on MSA mechanisms of language transformer. In contrast, visual data exhibits a fundamentally different structure: Its basic unit (pixel) is a natural low-level representation with significant redundancies in the neighbourhood, which poses obvious challenges to the interpretability of MSA mechanism in ViT. In this paper, we introduce a typical image processing technique, i.e., scale-invariant feature transforms (SIFTs), which maps low-level representations into mid-level spaces, and annotates extensive discrete keypoints with semantically rich information. Next, we construct a weighted patch interrelation analysis based on SIFT keypoints to capture the attention patterns hidden in patches with different semantic concentrations Interestingly, we find this quantitative analysis is not only an effective complement to the interpretability of MSA mechanisms in ViT, but can also be applied to 1) spurious correlation discovery and ``prompting'' during model inference, 2) and guided model pre-training acceleration. Experimental results on both applications show significant advantages over baselines, demonstrating the efficacy of our method.