 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting LLM Output Length via Entropy-Guided Representations
Feb 12, 2026The long-tailed distribution of sequence lengths in LLM serving and reinforcement learning (RL) sampling causes significant computational waste due to excessive padding in batched inference. Existing methods rely on auxiliary models for static length prediction, but they incur high overhead, generalize poorly, and fail in stochastic "one-to-many" sampling scenarios. We introduce a lightweight framework that reuses the main model's internal hidden states for efficient length prediction. Our framework features two core components: 1) Entropy-Guided Token Pooling (EGTP), which uses on-the-fly activations and token entropy for highly accurate static prediction with negligible cost, and 2) Progressive Length Prediction (PLP), which dynamically estimates the remaining length at each decoding step to handle stochastic generation. To validate our approach, we build and release ForeLen, a comprehensive benchmark with long-sequence, Chain-of-Thought, and RL data. On ForeLen, EGTP achieves state-of-the-art accuracy, reducing MAE by 29.16\% over the best baseline. Integrating our methods with a length-aware scheduler yields significant end-to-end throughput gains. Our work provides a new technical and evaluation baseline for efficient LLM inference.
Understanding the Impact of Differentially Private Training on Memorization of Long-Tailed Data
Feb 01, 2026Recent research shows that modern deep learning models achieve high predictive accuracy partly by memorizing individual training samples. Such memorization raises serious privacy concerns, motivating the widespread adoption of differentially private training algorithms such as DP-SGD. However, a growing body of empirical work shows that DP-SGD often leads to suboptimal generalization performance, particularly on long-tailed data that contain a large number of rare or atypical samples. Despite these observations, a theoretical understanding of this phenomenon remains largely unexplored, and existing differential privacy analysis are difficult to extend to the nonconvex and nonsmooth neural networks commonly used in practice. In this work, we develop the first theoretical framework for analyzing DP-SGD on long-tailed data from a feature learning perspective. We show that the test error of DP-SGD-trained models on the long-tailed subpopulation is significantly larger than the overall test error over the entire dataset. Our analysis further characterizes the training dynamics of DP-SGD, demonstrating how gradient clipping and noise injection jointly adversely affect the model's ability to memorize informative but underrepresented samples. Finally, we validate our theoretical findings through extensive experiments on both synthetic and real-world datasets.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025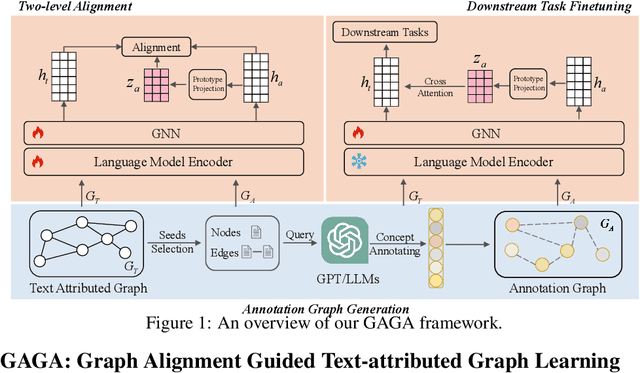
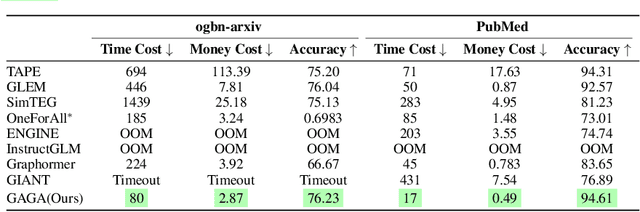
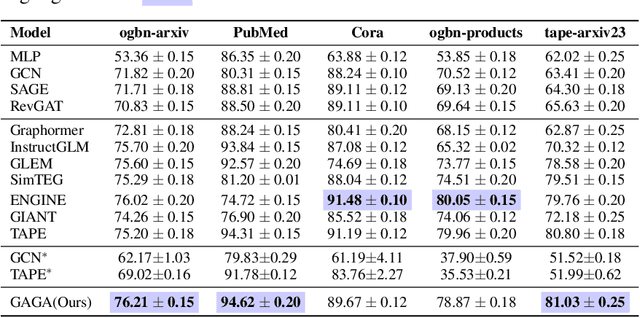
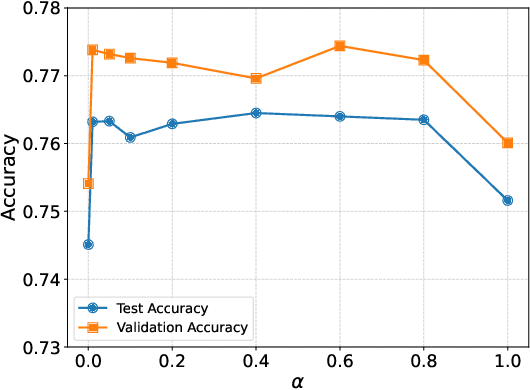
In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
ZO2: Scalable Zeroth-Order Fine-Tuning for Extremely Large Language Models with Limited GPU Memory
Mar 16, 2025Fine-tuning large pre-trained LLMs generally demands extensive GPU memory. Traditional first-order optimizers like SGD encounter substantial difficulties due to increased memory requirements from storing activations and gradients during both the forward and backward phases as the model size expands. Alternatively, zeroth-order (ZO) techniques can compute gradients using just forward operations, eliminating the need to store activations. Furthermore, by leveraging CPU capabilities, it's feasible to enhance both the memory and processing power available to a single GPU. We propose a novel framework, ZO2 (Zeroth-Order Offloading), for efficient zeroth-order fine-tuning of LLMs with only limited GPU memory. Our framework dynamically shifts model parameters between the CPU and GPU as required, optimizing computation flow and maximizing GPU usage by minimizing downtime. This integration of parameter adjustments with ZO's double forward operations reduces unnecessary data movement, enhancing the fine-tuning efficacy. Additionally, our framework supports an innovative low-bit precision approach in AMP mode to streamline data exchanges between the CPU and GPU. Employing this approach allows us to fine-tune extraordinarily large models, such as the OPT-175B with more than 175 billion parameters, on a mere 18GB GPU--achievements beyond the reach of traditional methods. Moreover, our framework achieves these results with almost no additional time overhead and absolutely no accuracy loss compared to standard zeroth-order methods. ZO2's code has been open-sourced in https://github.com/liangyuwang/zo2.
Evaluating Data Influence in Meta Learning
Jan 27, 2025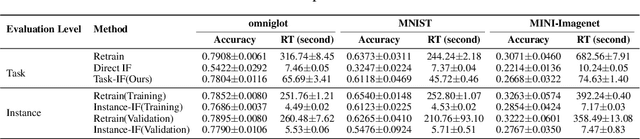
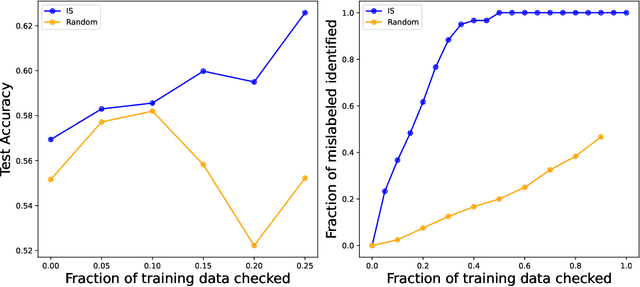
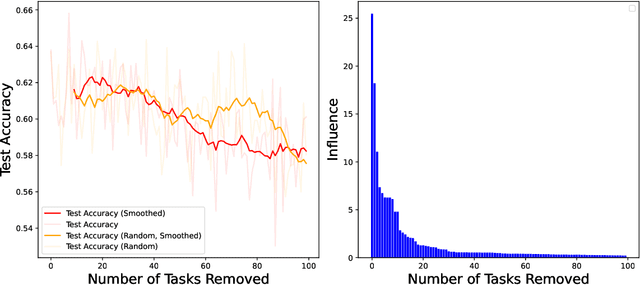
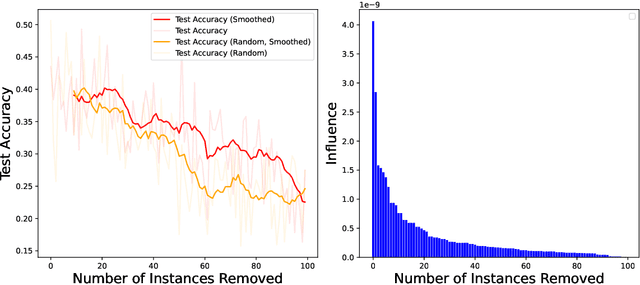
As one of the most fundamental models, meta learning aims to effectively address few-shot learning challenges. However, it still faces significant issues related to the training data, such as training inefficiencies due to numerous low-contribution tasks in large datasets and substantial noise from incorrect labels. Thus, training data attribution methods are needed for meta learning. However, the dual-layer structure of mata learning complicates the modeling of training data contributions because of the interdependent influence between meta-parameters and task-specific parameters, making existing data influence evaluation tools inapplicable or inaccurate. To address these challenges, based on the influence function, we propose a general data attribution evaluation framework for meta-learning within the bilevel optimization framework. Our approach introduces task influence functions (task-IF) and instance influence functions (instance-IF) to accurately assess the impact of specific tasks and individual data points in closed forms. This framework comprehensively models data contributions across both the inner and outer training processes, capturing the direct effects of data points on meta-parameters as well as their indirect influence through task-specific parameters. We also provide several strategies to enhance computational efficiency and scalability. Experimental results demonstrate the framework's effectiveness in training data evaluation via several downstream tasks.
Dissecting Misalignment of Multimodal Large Language Models via Influence Function
Nov 18, 2024Multi-modal Large Language models (MLLMs) are always trained on data from diverse and unreliable sources, which may contain misaligned or mislabeled text-image pairs. This frequently causes robustness issues and hallucinations, leading to performance degradation. Data valuation is an efficient way to detect and trace these misalignments. Nevertheless, existing methods are computationally expensive for MLLMs. While computationally efficient, the classical influence functions are inadequate for contrastive learning models because they were originally designed for pointwise loss. Additionally, contrastive learning involves minimizing the distance between the modalities of positive samples and maximizing the distance between the modalities of negative samples. This requires us to evaluate the influence of samples from both perspectives. To tackle these challenges, we introduce the Extended Influence Function for Contrastive Loss (ECIF), an influence function crafted for contrastive loss. ECIF considers both positive and negative samples and provides a closed-form approximation of contrastive learning models, eliminating the need for retraining. Building upon ECIF, we develop a series of algorithms for data evaluation in MLLM, misalignment detection, and misprediction trace-back tasks. Experimental results demonstrate our ECIF advances the transparency and interpretability of MLLMs by offering a more accurate assessment of data impact and model alignment compared to traditional baseline methods.
Semi-supervised Concept Bottleneck Models
Jun 27, 2024Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.