 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Long Tail: Efficient Item-wise Sharpness-Aware Minimization for LLM-based Recommender Systems
Mar 13, 2026Large Language Model-based Recommender Systems (LRSs) have recently emerged as a new paradigm in sequential recommendation by directly adopting LLMs as backbones. While LRSs demonstrate strong knowledge utilization and instruction-following abilities, they have not been systematically studied under the long-standing long-tail problem. In this paper, we conduct an empirical study and reveal that LRSs face two distinct types of long-tail: i) prior long-tail, inherited implicitly from pretraining corpora, and ii) data long-tail, originating from skewed recommendation datasets. Our analysis shows that both contribute to the performance disparity between head and tail items, with the intersection of the two heads exhibiting an even stronger head effect. Nevertheless, the overall performance distribution in LRSs, especially on the tail, remains dominated by the data long-tail. To address this challenge, we propose Efficient Item-wise Sharpness-Aware Minimization (EISAM), a novel optimization framework that improves tail-item performance by adaptively regularizing the loss landscape at the item level. EISAM introduces an efficient penalty design that captures fine-grained item-specific sharpness while maintaining computational scalability for LLMs. In addition, we derive a generalization bound for EISAM. Our theoretical analysis shows that the bound decreases at a faster rate under our item-wise regularization, offering theoretical support for its effectiveness. Extensive experiments on three real-world datasets demonstrate that EISAM significantly boosts tail-item recommendation performance while preserving overall quality, establishing the first systematic solution to the long-tail problem in LRSs.
Fine-Grained Zero-Shot Composed Image Retrieval with Complementary Visual-Semantic Integration
Jan 20, 2026Zero-shot composed image retrieval (ZS-CIR) is a rapidly growing area with significant practical applications, allowing users to retrieve a target image by providing a reference image and a relative caption describing the desired modifications. Existing ZS-CIR methods often struggle to capture fine-grained changes and integrate visual and semantic information effectively. They primarily rely on either transforming the multimodal query into a single text using image-to-text models or employing large language models for target image description generation, approaches that often fail to capture complementary visual information and complete semantic context. To address these limitations, we propose a novel Fine-Grained Zero-Shot Composed Image Retrieval method with Complementary Visual-Semantic Integration (CVSI). Specifically, CVSI leverages three key components: (1) Visual Information Extraction, which not only extracts global image features but also uses a pre-trained mapping network to convert the image into a pseudo token, combining it with the modification text and the objects most likely to be added. (2) Semantic Information Extraction, which involves using a pre-trained captioning model to generate multiple captions for the reference image, followed by leveraging an LLM to generate the modified captions and the objects most likely to be added. (3) Complementary Information Retrieval, which integrates information extracted from both the query and database images to retrieve the target image, enabling the system to efficiently handle retrieval queries in a variety of situations. Extensive experiments on three public datasets (e.g., CIRR, CIRCO, and FashionIQ) demonstrate that CVSI significantly outperforms existing state-of-the-art methods. Our code is available at https://github.com/yyc6631/CVSI.
SpatialTree: How Spatial Abilities Branch Out in MLLMs
Dec 23, 2025Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.
Using GUI Agent for Electronic Design Automation
Dec 12, 2025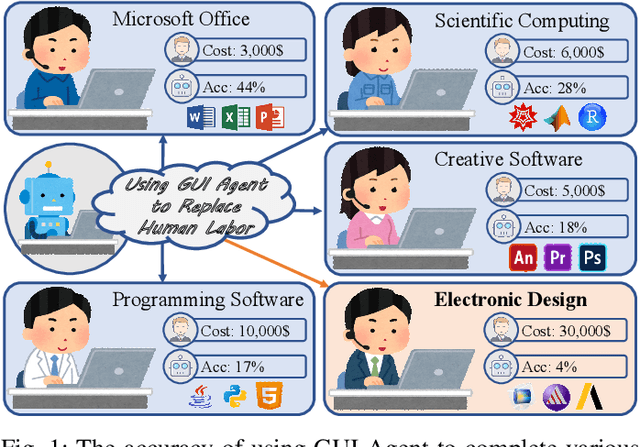
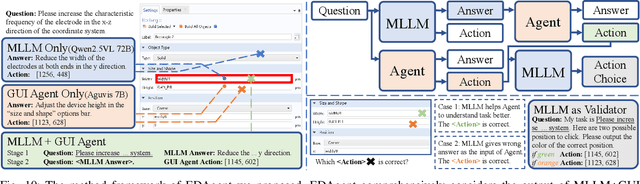
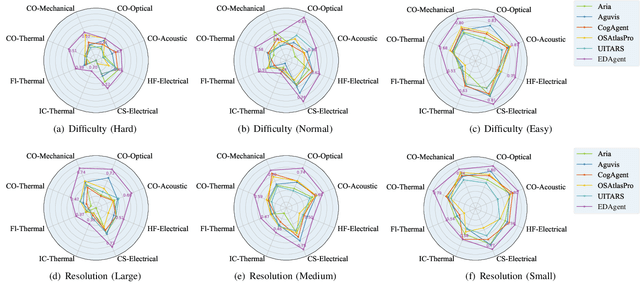
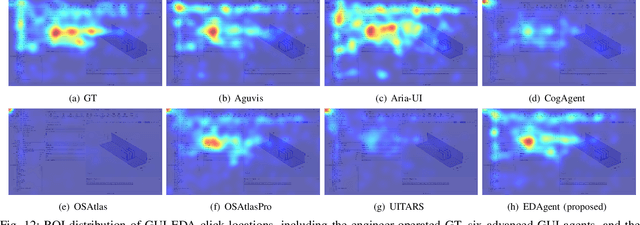
Graphical User Interface (GUI) agents adopt an end-to-end paradigm that maps a screenshot to an action sequence, thereby automating repetitive tasks in virtual environments. However, existing GUI agents are evaluated almost exclusively on commodity software such as Microsoft Word and Excel. Professional Computer-Aided Design (CAD) suites promise an order-of-magnitude higher economic return, yet remain the weakest performance domain for existing agents and are still far from replacing expert Electronic-Design-Automation (EDA) engineers. We therefore present the first systematic study that deploys GUI agents for EDA workflows. Our contributions are: (1) a large-scale dataset named GUI-EDA, including 5 CAD tools and 5 physical domains, comprising 2,000+ high-quality screenshot-answer-action pairs recorded by EDA scientists and engineers during real-world component design; (2) a comprehensive benchmark that evaluates 30+ mainstream GUI agents, demonstrating that EDA tasks constitute a major, unsolved challenge; and (3) an EDA-specialized metric named EDAgent, equipped with a reflection mechanism that achieves reliable performance on industrial CAD software and, for the first time, outperforms Ph.D. students majored in Electrical Engineering. This work extends GUI agents from generic office automation to specialized, high-value engineering domains and offers a new avenue for advancing EDA productivity. The dataset will be released at: https://github.com/aiben-ch/GUI-EDA.
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Dec 11, 2025The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.
Martian World Models: Controllable Video Synthesis with Physically Accurate 3D Reconstructions
Jul 10, 2025



Synthesizing realistic Martian landscape videos is crucial for mission rehearsal and robotic simulation. However, this task poses unique challenges due to the scarcity of high-quality Martian data and the significant domain gap between Martian and terrestrial imagery. To address these challenges, we propose a holistic solution composed of two key components: 1) A data curation pipeline Multimodal Mars Synthesis (M3arsSynth), which reconstructs 3D Martian environments from real stereo navigation images, sourced from NASA's Planetary Data System (PDS), and renders high-fidelity multiview 3D video sequences. 2) A Martian terrain video generator, MarsGen, which synthesizes novel videos visually realistic and geometrically consistent with the 3D structure encoded in the data. Our M3arsSynth engine spans a wide range of Martian terrains and acquisition dates, enabling the generation of physically accurate 3D surface models at metric-scale resolution. MarsGen, fine-tuned on M3arsSynth data, synthesizes videos conditioned on an initial image frame and, optionally, camera trajectories or textual prompts, allowing for video generation in novel environments. Experimental results show that our approach outperforms video synthesis models trained on terrestrial datasets, achieving superior visual fidelity and 3D structural consistency.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025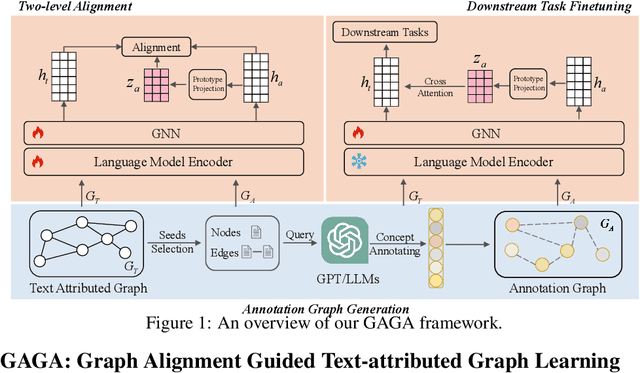
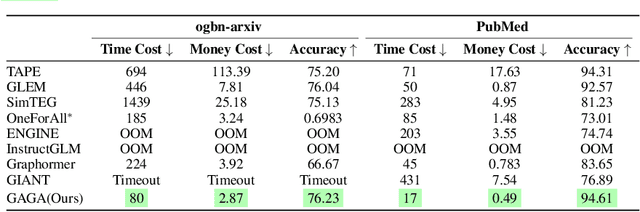
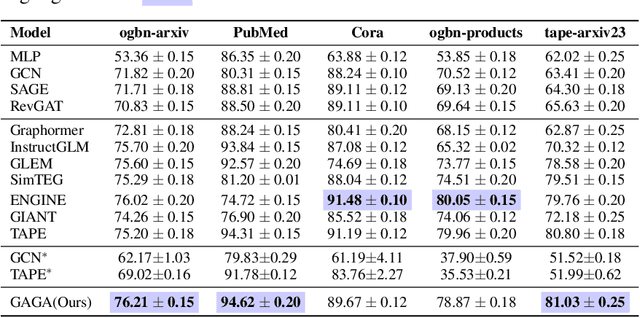
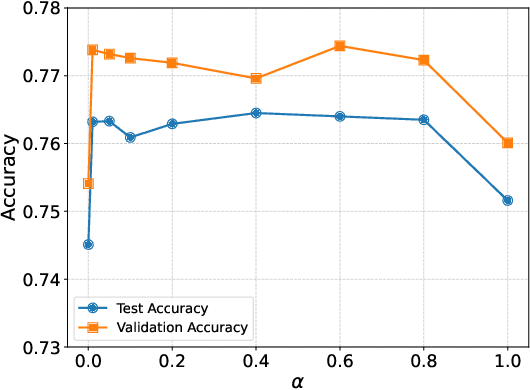
In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Combining Incomplete Observational and Randomized Data for Heterogeneous Treatment Effects
Oct 28, 2024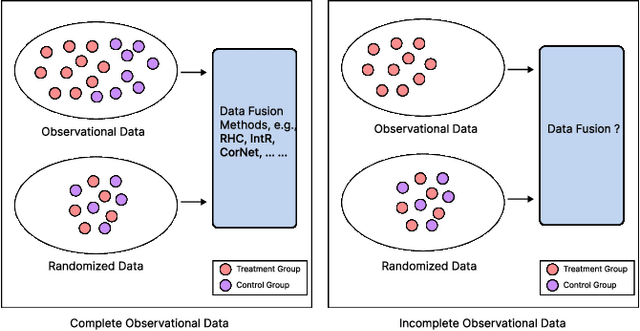
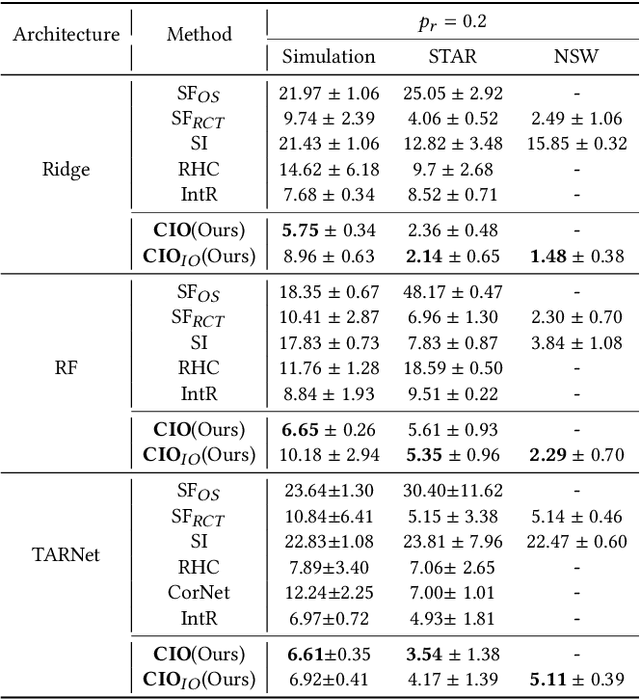
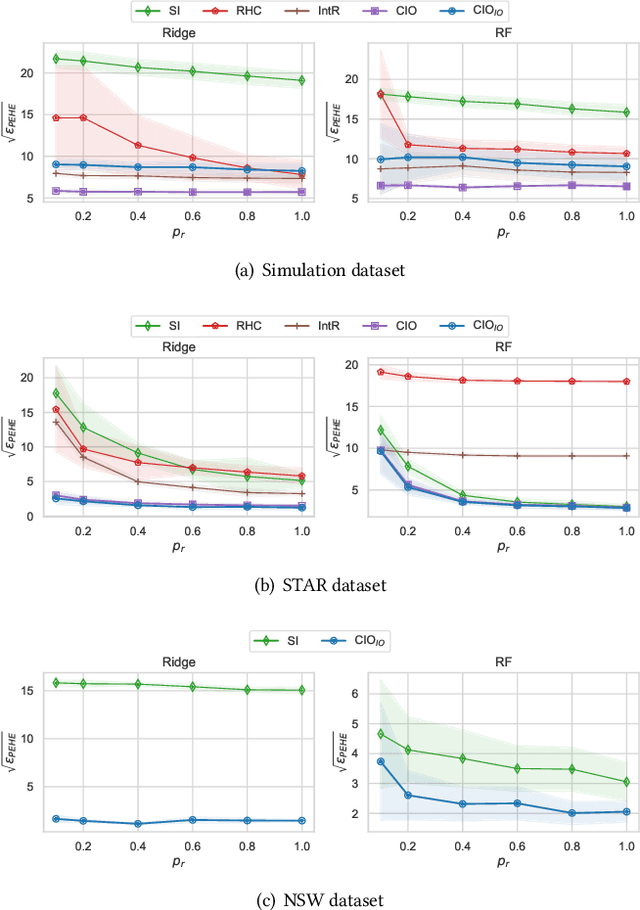
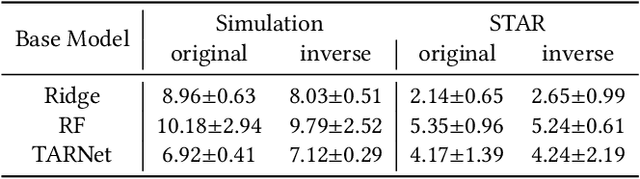
Data from observational studies (OSs) is widely available and readily obtainable yet frequently contains confounding biases. On the other hand, data derived from randomized controlled trials (RCTs) helps to reduce these biases; however, it is expensive to gather, resulting in a tiny size of randomized data. For this reason, effectively fusing observational data and randomized data to better estimate heterogeneous treatment effects (HTEs) has gained increasing attention. However, existing methods for integrating observational data with randomized data must require \textit{complete} observational data, meaning that both treated subjects and untreated subjects must be included in OSs. This prerequisite confines the applicability of such methods to very specific situations, given that including all subjects, whether treated or untreated, in observational studies is not consistently achievable. In our paper, we propose a resilient approach to \textbf{C}ombine \textbf{I}ncomplete \textbf{O}bservational data and randomized data for HTE estimation, which we abbreviate as \textbf{CIO}. The CIO is capable of estimating HTEs efficiently regardless of the completeness of the observational data, be it full or partial. Concretely, a confounding bias function is first derived using the pseudo-experimental group from OSs, in conjunction with the pseudo-control group from RCTs, via an effect estimation procedure. This function is subsequently utilized as a corrective residual to rectify the observed outcomes of observational data during the HTE estimation by combining the available observational data and the all randomized data. To validate our approach, we have conducted experiments on a synthetic dataset and two semi-synthetic datasets.
A Causal Explainable Guardrails for Large Language Models
May 07, 2024


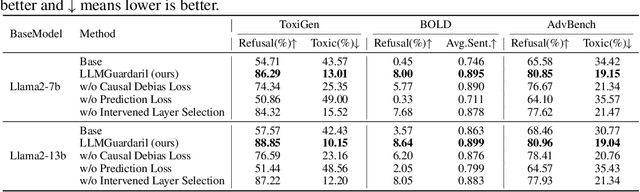
Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs towards desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardaril, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardaril systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardaril's effectiveness in steering LLMs towards desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes. We discuss the limitations and future research directions, highlighting the need for ongoing research to address the ethical implications of large language models.