 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models with Heavy-Tailed Targets: Score Estimation and Sampling Guarantees
Jan 10, 2026Score-based diffusion models have become a powerful framework for generative modeling, with score estimation as a central statistical bottleneck. Existing guarantees for score estimation largely focus on light-tailed targets or rely on restrictive assumptions such as compact support, which are often violated by heavy-tailed data in practice. In this work, we study conventional (Gaussian) score-based diffusion models when the target distribution is heavy-tailed and belongs to a Sobolev class with smoothness parameter $β>0$. We consider both exponential and polynomial tail decay, indexed by a tail parameter $γ$. Using kernel density estimation, we derive sharp minimax rates for score estimation, revealing a qualitative dichotomy: under exponential tails, the rate matches the light-tailed case up to polylogarithmic factors, whereas under polynomial tails the rate depends explicitly on $γ$. We further provide sampling guarantees for the associated continuous reverse dynamics. In total variation, the generated distribution converges at the minimax optimal rate $n^{-β/(2β+d)}$ under exponential tails (up to logarithmic factors), and at a $γ$-dependent rate under polynomial tails. Whether the latter sampling rate is minimax optimal remains an open question. These results characterize the statistical limits of score estimation and the resulting sampling accuracy for heavy-tailed targets, extending diffusion theory beyond the light-tailed setting.
Rethinking Recurrent Neural Networks for Time Series Forecasting: A Reinforced Recurrent Encoder with Prediction-Oriented Proximal Policy Optimization
Jan 07, 2026Time series forecasting plays a crucial role in contemporary engineering information systems for supporting decision-making across various industries, where Recurrent Neural Networks (RNNs) have been widely adopted due to their capability in modeling sequential data. Conventional RNN-based predictors adopt an encoder-only strategy with sliding historical windows as inputs to forecast future values. However, this approach treats all time steps and hidden states equally without considering their distinct contributions to forecasting, leading to suboptimal performance. To address this limitation, we propose a novel Reinforced Recurrent Encoder with Prediction-oriented Proximal Policy Optimization, RRE-PPO4Pred, which significantly improves time series modeling capacity and forecasting accuracy of the RNN models. The core innovations of this method are: (1) A novel Reinforced Recurrent Encoder (RRE) framework that enhances RNNs by formulating their internal adaptation as a Markov Decision Process, creating a unified decision environment capable of learning input feature selection, hidden skip connection, and output target selection; (2) An improved Prediction-oriented Proximal Policy Optimization algorithm, termed PPO4Pred, which is equipped with a Transformer-based agent for temporal reasoning and develops a dynamic transition sampling strategy to enhance sampling efficiency; (3) A co-evolutionary optimization paradigm to facilitate the learning of the RNN predictor and the policy agent, providing adaptive and interactive time series modeling. Comprehensive evaluations on five real-world datasets indicate that our method consistently outperforms existing baselines, and attains accuracy better than state-of-the-art Transformer models, thus providing an advanced time series predictor in engineering informatics.
Improving Autoformalization Using Direct Dependency Retrieval
Nov 15, 2025The convergence of deep learning and formal mathematics has spurred research in formal verification. Statement autoformalization, a crucial first step in this process, aims to translate informal descriptions into machine-verifiable representations but remains a significant challenge. The core difficulty lies in the fact that existing methods often suffer from a lack of contextual awareness, leading to hallucination of formal definitions and theorems. Furthermore, current retrieval-augmented approaches exhibit poor precision and recall for formal library dependency retrieval, and lack the scalability to effectively leverage ever-growing public datasets. To bridge this gap, we propose a novel retrieval-augmented framework based on DDR (\textit{Direct Dependency Retrieval}) for statement autoformalization. Our DDR method directly generates candidate library dependencies from natural language mathematical descriptions and subsequently verifies their existence within the formal library via an efficient suffix array check. Leveraging this efficient search mechanism, we constructed a dependency retrieval dataset of over 500,000 samples and fine-tuned a high-precision DDR model. Experimental results demonstrate that our DDR model significantly outperforms SOTA methods in both retrieval precision and recall. Consequently, an autoformalizer equipped with DDR shows consistent performance advantages in both single-attempt accuracy and multi-attempt stability compared to models using traditional selection-based RAG methods.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
Locality Preserving Markovian Transition for Instance Retrieval
Jun 05, 2025Diffusion-based re-ranking methods are effective in modeling the data manifolds through similarity propagation in affinity graphs. However, positive signals tend to diminish over several steps away from the source, reducing discriminative power beyond local regions. To address this issue, we introduce the Locality Preserving Markovian Transition (LPMT) framework, which employs a long-term thermodynamic transition process with multiple states for accurate manifold distance measurement. The proposed LPMT first integrates diffusion processes across separate graphs using Bidirectional Collaborative Diffusion (BCD) to establish strong similarity relationships. Afterwards, Locality State Embedding (LSE) encodes each instance into a distribution for enhanced local consistency. These distributions are interconnected via the Thermodynamic Markovian Transition (TMT) process, enabling efficient global retrieval while maintaining local effectiveness. Experimental results across diverse tasks confirm the effectiveness of LPMT for instance retrieval.
GIFStream: 4D Gaussian-based Immersive Video with Feature Stream
May 12, 2025Immersive video offers a 6-Dof-free viewing experience, potentially playing a key role in future video technology. Recently, 4D Gaussian Splatting has gained attention as an effective approach for immersive video due to its high rendering efficiency and quality, though maintaining quality with manageable storage remains challenging. To address this, we introduce GIFStream, a novel 4D Gaussian representation using a canonical space and a deformation field enhanced with time-dependent feature streams. These feature streams enable complex motion modeling and allow efficient compression by leveraging temporal correspondence and motion-aware pruning. Additionally, we incorporate both temporal and spatial compression networks for end-to-end compression. Experimental results show that GIFStream delivers high-quality immersive video at 30 Mbps, with real-time rendering and fast decoding on an RTX 4090. Project page: https://xdimlab.github.io/GIFStream
Language Guided Concept Bottleneck Models for Interpretable Continual Learning
Mar 30, 2025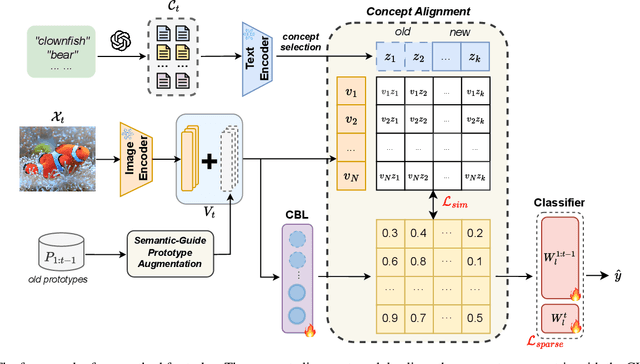
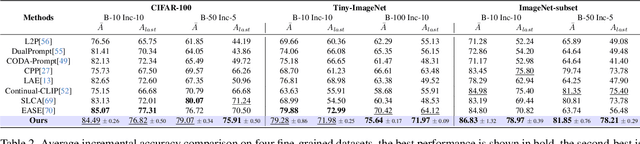
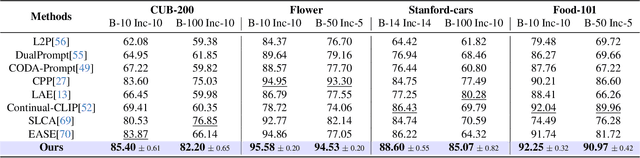
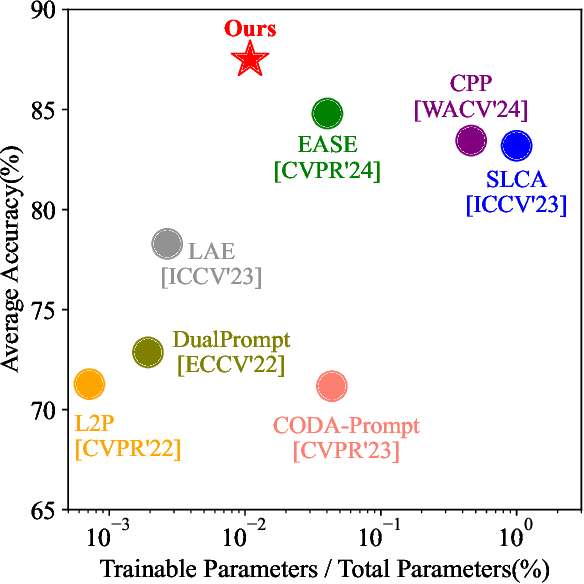
Continual learning (CL) aims to enable learning systems to acquire new knowledge constantly without forgetting previously learned information. CL faces the challenge of mitigating catastrophic forgetting while maintaining interpretability across tasks. Most existing CL methods focus primarily on preserving learned knowledge to improve model performance. However, as new information is introduced, the interpretability of the learning process becomes crucial for understanding the evolving decision-making process, yet it is rarely explored. In this paper, we introduce a novel framework that integrates language-guided Concept Bottleneck Models (CBMs) to address both challenges. Our approach leverages the Concept Bottleneck Layer, aligning semantic consistency with CLIP models to learn human-understandable concepts that can generalize across tasks. By focusing on interpretable concepts, our method not only enhances the models ability to retain knowledge over time but also provides transparent decision-making insights. We demonstrate the effectiveness of our approach by achieving superior performance on several datasets, outperforming state-of-the-art methods with an improvement of up to 3.06% in final average accuracy on ImageNet-subset. Additionally, we offer concept visualizations for model predictions, further advancing the understanding of interpretable continual learning.
MASS: Mathematical Data Selection via Skill Graphs for Pretraining Large Language Models
Mar 19, 2025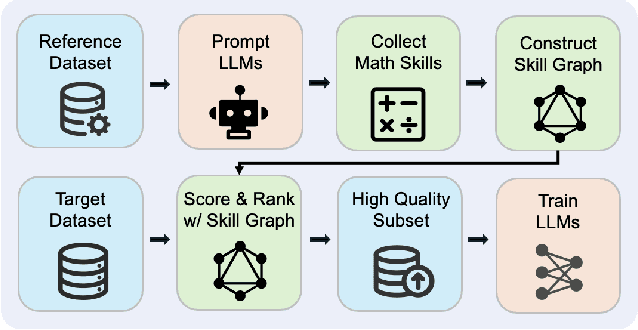

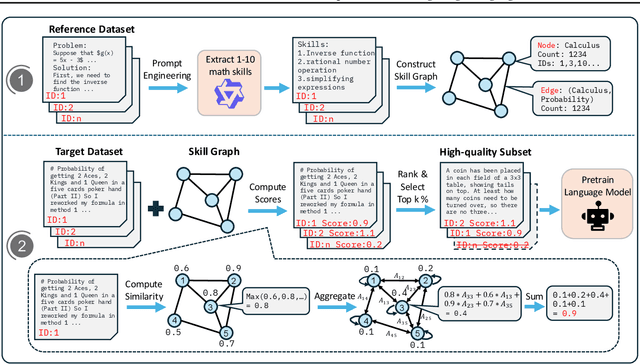

High-quality data plays a critical role in the pretraining and fine-tuning of large language models (LLMs), even determining their performance ceiling to some degree. Consequently, numerous data selection methods have been proposed to identify subsets of data that can effectively and efficiently enhance model performance. However, most of these methods focus on general data selection and tend to overlook the specific nuances of domain-related data. In this paper, we introduce MASS, a \textbf{MA}thematical data \textbf{S}election framework using the \textbf{S}kill graph for pretraining LLMs in the mathematical reasoning domain. By taking into account the unique characteristics of mathematics and reasoning, we construct a skill graph that captures the mathematical skills and their interrelations from a reference dataset. This skill graph guides us in assigning quality scores to the target dataset, enabling us to select the top-ranked subset which is further used to pretrain LLMs. Experimental results demonstrate the efficiency and effectiveness of MASS across different model sizes (1B and 7B) and pretraining datasets (web data and synthetic data). Specifically, in terms of efficiency, models trained on subsets selected by MASS can achieve similar performance to models trained on the original datasets, with a significant reduction in the number of trained tokens - ranging from 50\% to 70\% fewer tokens. In terms of effectiveness, when trained on the same amount of tokens, models trained on the data selected by MASS outperform those trained on the original datasets by 3.3\% to 5.9\%. These results underscore the potential of MASS to improve both the efficiency and effectiveness of pretraining LLMs.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Advancing Wasserstein Convergence Analysis of Score-Based Models: Insights from Discretization and Second-Order Acceleration
Feb 07, 2025
Score-based diffusion models have emerged as powerful tools in generative modeling, yet their theoretical foundations remain underexplored. In this work, we focus on the Wasserstein convergence analysis of score-based diffusion models. Specifically, we investigate the impact of various discretization schemes, including Euler discretization, exponential integrators, and midpoint randomization methods. Our analysis provides a quantitative comparison of these discrete approximations, emphasizing their influence on convergence behavior. Furthermore, we explore scenarios where Hessian information is available and propose an accelerated sampler based on the local linearization method. We demonstrate that this Hessian-based approach achieves faster convergence rates of order $\widetilde{\mathcal{O}}\left(\frac{1}{\varepsilon}\right)$ significantly improving upon the standard rate $\widetilde{\mathcal{O}}\left(\frac{1}{\varepsilon^2}\right)$ of vanilla diffusion models, where $\varepsilon$ denotes the target accuracy.