 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Concept Bottleneck Models
Jan 01, 2026Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on static scenarios where the data and concepts are assumed to be fixed and clean. In real-world applications, deployed models require continuous maintenance: we often need to remove erroneous or sensitive data (unlearning), correct mislabeled concepts, or incorporate newly acquired samples (incremental learning) to adapt to evolving environments. Thus, deriving efficient editable CBMs without retraining from scratch remains a significant challenge, particularly in large-scale applications. To address these challenges, we propose Controllable Concept Bottleneck Models (CCBMs). Specifically, CCBMs support three granularities of model editing: concept-label-level, concept-level, and data-level, the latter of which encompasses both data removal and data addition. CCBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for retraining. Experimental results demonstrate the efficiency and adaptability of our CCBMs, affirming their practical value in enabling dynamic and trustworthy CBMs.
Evaluating Data Influence in Meta Learning
Jan 27, 2025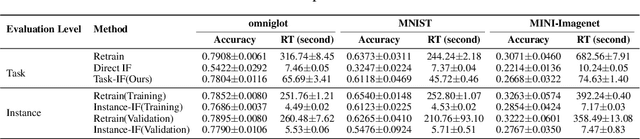
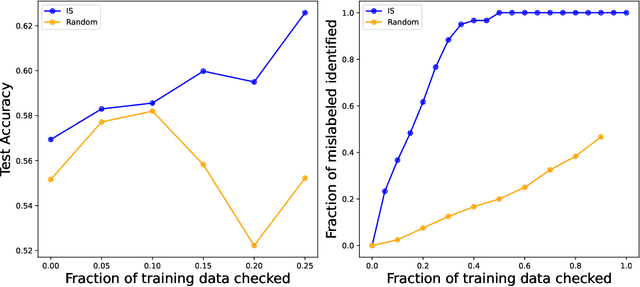
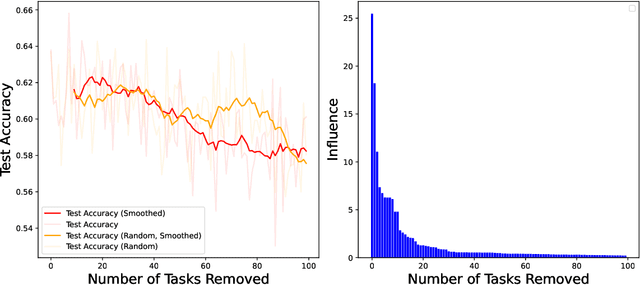
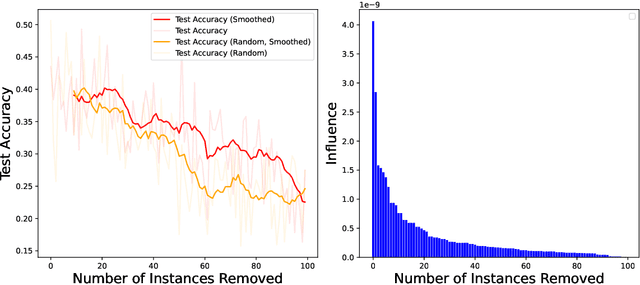
As one of the most fundamental models, meta learning aims to effectively address few-shot learning challenges. However, it still faces significant issues related to the training data, such as training inefficiencies due to numerous low-contribution tasks in large datasets and substantial noise from incorrect labels. Thus, training data attribution methods are needed for meta learning. However, the dual-layer structure of mata learning complicates the modeling of training data contributions because of the interdependent influence between meta-parameters and task-specific parameters, making existing data influence evaluation tools inapplicable or inaccurate. To address these challenges, based on the influence function, we propose a general data attribution evaluation framework for meta-learning within the bilevel optimization framework. Our approach introduces task influence functions (task-IF) and instance influence functions (instance-IF) to accurately assess the impact of specific tasks and individual data points in closed forms. This framework comprehensively models data contributions across both the inner and outer training processes, capturing the direct effects of data points on meta-parameters as well as their indirect influence through task-specific parameters. We also provide several strategies to enhance computational efficiency and scalability. Experimental results demonstrate the framework's effectiveness in training data evaluation via several downstream tasks.
Dissecting Misalignment of Multimodal Large Language Models via Influence Function
Nov 18, 2024Multi-modal Large Language models (MLLMs) are always trained on data from diverse and unreliable sources, which may contain misaligned or mislabeled text-image pairs. This frequently causes robustness issues and hallucinations, leading to performance degradation. Data valuation is an efficient way to detect and trace these misalignments. Nevertheless, existing methods are computationally expensive for MLLMs. While computationally efficient, the classical influence functions are inadequate for contrastive learning models because they were originally designed for pointwise loss. Additionally, contrastive learning involves minimizing the distance between the modalities of positive samples and maximizing the distance between the modalities of negative samples. This requires us to evaluate the influence of samples from both perspectives. To tackle these challenges, we introduce the Extended Influence Function for Contrastive Loss (ECIF), an influence function crafted for contrastive loss. ECIF considers both positive and negative samples and provides a closed-form approximation of contrastive learning models, eliminating the need for retraining. Building upon ECIF, we develop a series of algorithms for data evaluation in MLLM, misalignment detection, and misprediction trace-back tasks. Experimental results demonstrate our ECIF advances the transparency and interpretability of MLLMs by offering a more accurate assessment of data impact and model alignment compared to traditional baseline methods.
Semi-supervised Concept Bottleneck Models
Jun 27, 2024Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
Editable Concept Bottleneck Models
May 24, 2024Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on cases where the data, including concepts, are clean. In many scenarios, we always need to remove/insert some training data or new concepts from trained CBMs due to different reasons, such as privacy concerns, data mislabelling, spurious concepts, and concept annotation errors. Thus, the challenge of deriving efficient editable CBMs without retraining from scratch persists, particularly in large-scale applications. To address these challenges, we propose Editable Concept Bottleneck Models (ECBMs). Specifically, ECBMs support three different levels of data removal: concept-label-level, concept-level, and data-level. ECBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for re-training. Experimental results demonstrate the efficiency and effectiveness of our ECBMs, affirming their adaptability within the realm of CBMs.